How Watermarking Can Help Mitigate The Potential Risks Of LLMs?
Adding embedding signals into generated text can help mitigate potential risks of plagiarism, misinformation, and abuse in large language models.

Image by Author
Why do we need a Watermarking for Large Language Models?
Large language models (LLMs) like ChatGPT, GPT-4, and Bard are revolutionizing the way we work. We now have tools that help us code the whole program or write a blog post for a new product release. Applications powered by GPT-3.5 are generating realistic and diverse texts on multiple topics. Just like all of the new technologies, they come with the potential risks of stealing intellectual property, plagiarism, misinformation, and online abuse.
How do we ensure that LLMs outputs are trustworthy and accountable? Currently, there is no reliable solution. There are some tools for detecting generated text, but they have low accuracy.
In the paper by the University of Maryland: A Watermark for Large Language Models, the authors have proposed a watermarking framework for proprietary LLMs. It watermarks the output of generated text with invisible signals that can be detected by an algorithm and invisible to humans.
Watermarking is an effective technique that can be used to prove the ownership, authenticity, or integrity of the object.
For example:
- It can help protect the intellectual property (models) of LLM developers, scientists, and companies.
- It can prevent plagiarism or misattribution.
- It can help detect social media misinformation campaigns.
- The most important use of watermarking is that it can help monitor and audit the use and impact of LLMs and prevent misuse or abuse.
How does Watermarking work for LLMs?
The watermarking framework consists of two components: embedding and detection.
Embedding
It is the process of inserting a watermark into the output of the LLMs. To make it possible, the LLM developer needs to slightly modify the model parameters to embed the watermark.
The embedding works by selecting a random set of "green" tokens before each word is generated, and then softly promoting the use of green tokens during sampling. The green tokens are chosen in a way that does not affect the context and quality of the text. The embedding also ensures that there are enough tokens in each span to make the decision process possible.
Detection
It is the process of extracting the “green” tokens from a given span of text. It does not require model parameters or API. The detection works by computing a statistic called curvature for each token in the span. Curvature is the measurement of how sensitive the probability distribution over tokens is to small changes in model parameters.
The authors explain that the green tokens have a higher curvature than the normal tokes and thus form a detectable pattern in the text.
After performing watermarking detection, the algorithm performs a statistical test to determine the confidence level of the result.
You can learn more by reading the paper on arxiv.org.
Hugging Face Demo
You can try generating text with watermarks by using the Hugging Space Gradio Demo or you can check out the GitHub repository: jwkirchenbauer/lm-watermarking for running the Python scripts on personal machine.
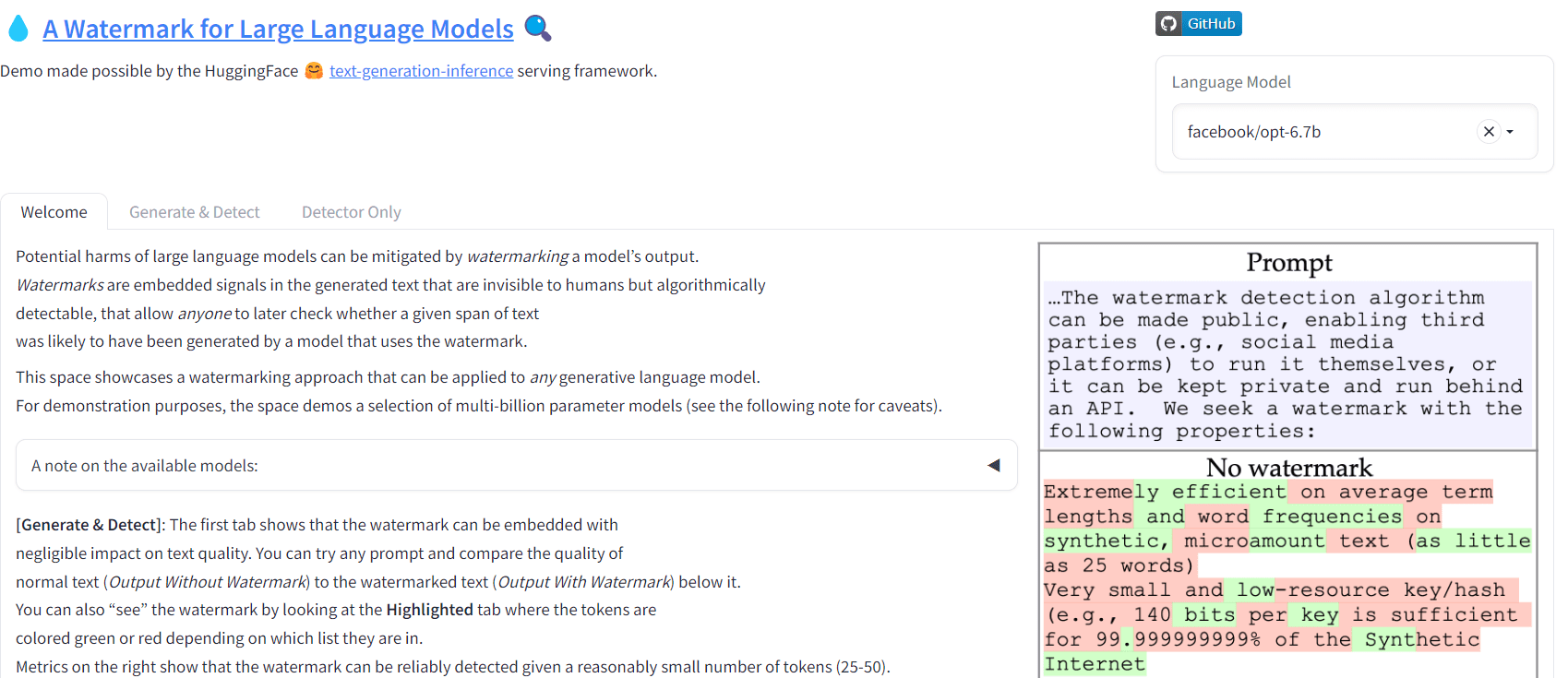
Image from Hugging Face | A Watermark for LLMs
How Effective is Watermarking for LLMs?
We will review the results mentioned in the paper on various tasks such as summarization, translation, and dialogue generation.
The paper reports that their framework achieves high embedding rates > 90% and detection rates > 99% across different tasks while maintaining low false positive rates < 1% and high text quality scores. The authors have also demonstrated that the framework is robust to various attacks, such as paraphrasing, mixing, or truncating watermarked texts.
- Embedding rate: how often green tokens are used in the output.
- Detection rate: how often watermarks are correctly detected.
- False positive rate: how often non-watermarked texts are mistakenly detected as watermarked.
- Text quality: how natural and fluent.
Limitations and Challenges
It is a start, and the watermark framework comes with limitations and challenges, such as:
- You have to modify model parameters during embedding, and in some cases (API, edge device) it is not possible.
- It relies on sampling-based generation methods that are not compatible with other methods, such as beam search or nucleus sampling.
- The watermarks are embedded uniformly across different tasks, and it might not be good for certain tasks where certain tokens have more semantic importance than others
There are other implementation challenges and fair use policies that are essential for wide adoption of an algorithm.
Conclusion
In this blog, we have discussed the importance of watermarking for large language models, how the framework works, results, and limitations. It is the summary of a paper that proposes a watermarking framework for proprietary LLMs.
It is a start, and we need frameworks like watermarking to make AI safer for everyone. I want you to try the Hugging Face demo to experience the awesomeness yourself. If you are interested in theory and the inner working of algorithms, read the paper and code source.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.