Simple and Fast Data Streaming for Machine Learning Projects
Learn about the cutting-edge DagsHub's Direct Data Access for simple and faster data loading and model training.

Image Author
Have you ever wondered why you have to wait for DVC to pull all the files to access a single file? Maybe you have created custom scripts to work around this problem. But what if I tell you there is a better solution for this issue?
Direct Data Access makes it fairly easy for you to load single or multiple files from the DagsHub DVC server. You can also upload a single file or multiple files using Upload API. It will help you save time, as you won’t be pulling the entire dataset to push a single file.
Direct Data Access works better with all kinds of Python libraries. Especially those that use high levels of functionalities. In the case of a training machine learning model, you can pull the data directly into DataLoader and start training or fine-tuning the model.
In this tutorial, we will look deep into DagsHub's Direct Data Access and train simple Yoga pose classification models using FastAI-2 and Direct Data Access.
Getting Started with Direct Data Access
Direct Data Access comes with DagsHub client API. Instead of using `dvc pull` to download all the data, you can access the files on demand from DagsHub servers.
The streamed files are indistinguishable from the local files saved on your disk. You can provide a local file path, and it will fetch files from DagsHub.
Install the DagsHub API using GitHub URL and pip command.
!pip install git+https://github.com/DagsHub/client.git
Or
!pip install dagshub
Note: currently, the Direct Data Access is in beta version with minor issues.
Manual Method
The manual method lets you stream files using DagsHubFilesystem.
You just have to replace:
| Python API | DagsHub File System |
| open() | fs.open() |
| os.stat() | fs.stat() |
| os.listdir() | fs.listdir() |
| os.scandir() | fs.scandir() |
If you are in a Git repository, you don’t have to provide configuration parameters.
To override automatically detected configuration, use:
- repo_url
- username
- Password
If you are outside the Git repository, you can also point to the project directory using the `project_root` argument.
In the example, we have created a DagsHubFilesystem and displayed a list of files and folders using listdir().
from dagshub.streaming import DagsHubFilesystem fs = DagsHubFilesystem() fs.listdir()
It is showing “Mobilenet-Weights” and “Saved_Models” folders that are not available in the local directory but on the DVC server. In short, you have access to all the files that you can see in the DagsHub repository without performing the `dvc pull` command.
['Mobilenet-Weights', 'Mobilenet-Weights.dvc', '.git', 'dvc.lock', '.gitignore', 'README.md', 'src', 'Saved_Models', 'LICENSE', 'Data', 'dvc.yaml', '.dvc', 'requirments.txt', '.dagshub-streaming', '.dvcignore']
Automatic Method
The `install_hooks` allows Python libraries (*some exceptions apply) to access DVC tracked files as if they are on your system. It is simple and fast.
In the example below, we have invoked `install_hooks()` and used PIL.Image to display the image of a woman in a down dog yoga pose.
from PIL import Image
from dagshub.streaming import install_hooks
install_hooks()
Image.open("./Data/Yoga Pose/Downdog/00000011.jpg")

I know, it is magic. It will also amaze you with faster loading time.
Note: While using the DagsHubFilesystem or install_hooks command you will be asked to generate a temporary OAuth key for additive security.
Yoga Pose Classification Using Direct Data Access
In this tutorial, we will fine-tune the Resnet34 model on the Yoga pose dataset using Direct Data Access. The dataset consists of 5 classes of Yoga pose images and the images were extracted using Bing API.

Image by Author
Setting Up
You can fork and clone my repository and run the command below on a Google Colab or Jupyter Notebook. The command requires a branch name, repo name, username, and access token. You can simply replace the placeholders with your configurations.
Note: make sure you are inside the repository to activate Streaming.
!git clone -b {BRANCH} https://{DAGSHUB_USER_NAME}:{DAGSHUB_TOKEN}@dagshub.com/{DAGSHUB_USER_NAME}/{DAGSHUB_REPO_NAME}.git
%cd {DAGSHUB_REPO_NAME}
If you are facing problems with getting started, check out the Colab notebook.
Next, we will import Pytorch, FastAI, os, and Matplotlib. The project is based on the FastAI framework. Read the documentation to learn more.
import torch import matplotlib.pyplot as plt from fastai.vision.all import * from fastai.metrics import error_rate, accuracy import os
Data Loader
After invoking install_hooks(), we can automatically access the files using: `ImageDataloaders`.
It took 6.54 seconds to load and download the 18.1 MB dataset. It is fast compared to 73.84 seconds with `dvc pull` + ImageDataLoaders.
%%time
from dagshub.streaming import install_hooks
install_hooks()
path = Path('./Data/Yoga Pose')
data = ImageDataLoaders.from_folder(path, valid_pct=0.2, item_tfms=Resize(224))
CPU times: user 1.68 s, sys: 914 ms, total: 2.59 s Wall time: 6.54 s
Visualization
Our dataset is pretty simple and consists of various Yoga poses with labels. We will be using it to train our model. The Resnet34 does not require large data, even a few hundred images can provide state-of-the-art results.
data.show_batch()

Model Fine-Tuning
Before we start fine-tuning, we need to set up MLflow for experiment tracking. DagsHub provides a free MLflow server. You just need to set the tracking URI, and we are good to go. You can find URI by clicking on the green button(Remote) on the repo page and accessing it through the MLflow tab.
The `get_experiment_id` function generates and returns experiment id.
import mlflow
mlflow.set_tracking_uri(os.getenv("MLFLOW_TRACKING_URI"))
def get_experiment_id(name):
exp = mlflow.get_experiment_by_name(name)
if exp is None:
exp_id = mlflow.create_experiment(name)
return exp_id
return exp.experiment_id
exp_id = get_experiment_id("yoga_colab")
After that, activate tracking using mlflow.fastai.autolog(). It will log the experiment and send it to the MLflow server on DagsHub.
Finally, we will build our learner with resnet34 and set metrics to accuracy and error_rate.
%%time
mlflow.fastai.autolog()
learn = vision_learner(data, resnet34, metrics=[accuracy, error_rate])
with mlflow.start_run(experiment_id=exp_id) as run:
learn.fine_tune(3)
After fine-tuning for 3 epochs, we got state-of-the-art results with 95.9% accuracy and 0.04 loss.
| epoch | train_loss | valid_loss | accuracy | error_rate | time |
| 0 | 0.368970 | 0.154318 | 0.954315 | 0.045685 | 00:05 |
| 1 | 0.220782 | 0.127155 | 0.964467 | 0.035533 | 00:05 |
| 2 | 0.145330 | 0.116135 | 0.959391 | 0.040609 | 00:05 |
CPU times: user 12.4 s, sys: 4.55 s, total: 16.9 s Wall time: 1min 14s
Note: If you are using Colab to train a model, you need to set tag to link commit with experiment results using: `mlflow.set_tag('mlflow.source.git.commit', "<commit-id>")`
Save the model and use it for Inference and reproducibility.
os.mkdir("/content/Yoga-Pose-Classification/Saved_Models/")
learn.save("/content/Yoga-Pose-Classification/Saved_Models/my_model", with_opt=False)
Simple Prediction
Let’s get a random image from a training set to predict the label. As you can see, we get the Downdog label with 99.99% certainty.
files = get_image_files("/content/Yoga-Pose-Classification/Data/Yoga Pose/Downdog")
learn.predict(files[0])
>>> ('Downdog',
TensorBase(0),
TensorBase([9.9999e-01, 8.2240e-07, 9.9132e-06, 5.6985e-07, 9.2867e-07]))
Evaluation
The model evaluation shows that the model has accurately predicted all of the images.
learn.show_results()

MLflow
You can review past experiments and results using the DagsHub experiment tab. I was first training with Keras MobilenetV3 and various other models. In the end, I chose FastAI and Resnet34 for simplicity and better results.
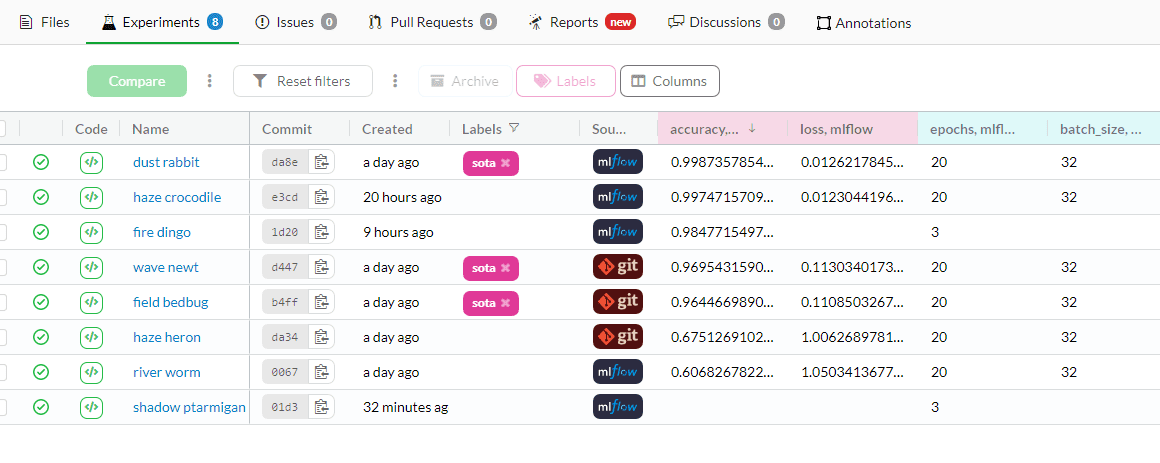
Image from kingabzpro/Yoga-Pose-Classification
DagsHub Data Upload API
The streaming goes both ways. You can also upload single or multiple files using the DagsHub Upload API.
To test our model on unseen data, let's download the Yoga Pose images from Google. We will be uploading the images and by using Streaming, we will be accessing them for prediction.
Image form Google search
We will use upload.Repo to create a repo object. It will help us directly upload files using a username, access token, repository name, and branch.
Note: For uploading, you don’t even need to clone any git repository.
from dagshub.upload import Repo
repo = Repo(
owner=DAGSHUB_USER_NAME,
name=DAGSHUB_REPO_NAME,
branch=BRANCH,
username=DAGSHUB_USER_NAME,
password=DAGSHUB_TOKEN,
)
Uploading Multiple Files
To Upload multiple files, we need to provide a folder directory. If the folder name does not exist, it will create one for you.
In the next step, we are using a loop to add 2 new yoga pose image files and committing it with message and versioning.
By using the versioning, you can upload the files that are tracked by Git or DVC.
ds = repo.directory("Sample")
file_list = ["/content/yoga1.jpeg", "/content/yoga2.jpeg"]
for file1 in file_list:
ds.add(file1)
ds.commit("multiple files upload", versioning="dvc")
The files are successfully uploaded. Hurray!!!
It is awesome.
I was so happy when I uploaded the files for the first time without cloning the Git repository and pulling dvc data.
Uploading Single File
You can also upload a file using a single line, by providing a local file and repository file path. With this you can upload files in any folder.
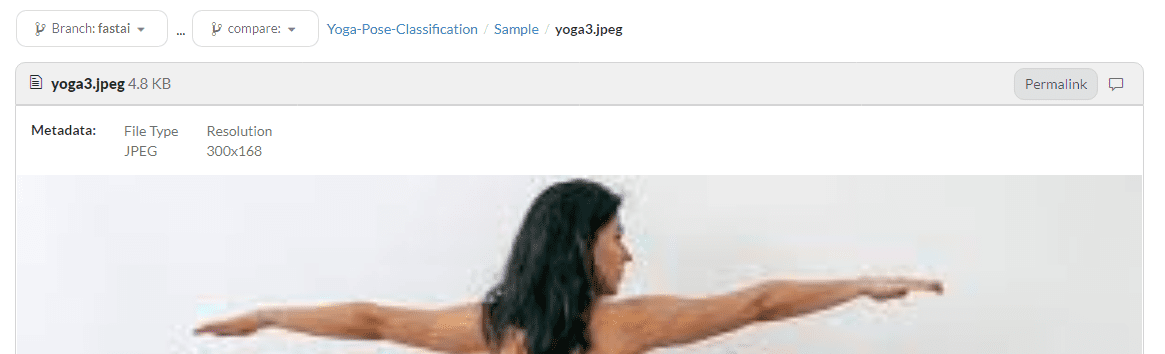
In our case, we are uploading the third file to the Sample folder using message and dvc versioning.
repo.upload(
file="/content/yoga3.jpeg",
path="Sample/yoga3.jpeg",
commit_message="yoga single file upload",
versioning="dvc",
)
The third image is successfully uploaded to the DagsHub repository.
Model Prediction
Now, we will use the uploaded images to predict the Yoga Pose.
%%time install_hooks() from PIL import Image import IPython.display as display img_loc = "./Sample/yoga3.jpeg" img = Image.open(img_loc) display.display(img) learn.predict(img_loc)
The model has accurately predicted the Warrior2 pose with 99.9% certainty.

CPU times: user 56.7 ms, sys: 2.14 ms, total: 58.8 ms
Wall time: 62.2 ms
('Warrior2',
TensorBase(4),
TensorBase([3.8390e-05, 5.2042e-04, 7.9451e-05, 5.5486e-06, 9.9936e-01]))
Note: to access recently uploaded files, you have to run `install_hooks()` again.
Benchmark
Even though DagsHub's Direct Data Access is in the Beta stage, it shows promising results. With streaming, we have loaded the image files 11X faster than `dvc pull`. There are still minor bugs that you will always see in the Beta version, but overall, I was impressed by the DagsHub team, who came up with an amazing solution.
| Streaming(s) | No-streaming(s) | |
| Dataloader | 6.54 | 73.84 |
| Training | 74 | 72 |
| Total | 80.54 | 145.84 |
In the end, I will ask everyone to give Direct Data Access a try and ask questions in the Discord support channel, if you are facing issues.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.