5 Reasons Why You Need Synthetic Data
Collecting and labeling data in the real world can be time-consuming and expensive. This data can also come with quality, diversity, and quantity issues. Fortunately, problems like these can be helped with synthetic data.

Synthetic data generated from Kubric
To train a machine learning model, you need data. Data science tasks aren’t usually a Kaggle competition where you have a nice large curated dataset that comes pre-labeled. Sometimes you have to collect, organize, and clean your own data. This process of collecting and labeling data in the real world can be time-consuming, cumbersome, expensive, inaccurate, and sometimes dangerous. Furthermore, at the end of this process, you can end up with the data that you encountered in the real world not necessarily being the data you would like in terms of quality, diversity (e.g., class imbalance), and quantity. Below are common problems you can encounter when working with real data:
- Real data collection and labeling aren’t scalable
- Manually labeling real data can sometimes be impossible
- Real data has privacy and safety issues
- Real data is not programmable
- A model trained exclusively on real data is not performant enough (e.g., slow development velocity)
Fortunately, problems like these can be solved with synthetic data. You might be wondering, what is synthetic data? Synthetic data can be defined as artificially generated data which is typically created using algorithms that simulate real-world processes, from the behavior of other road users all the way down to the behavior of light as it interacts with surfaces. This post goes over the limitations of real-world data, and how synthetic data can help overcome these problems and improve model performance.
Real Data Collection and Labeling aren’t Scalable
For small datasets, it is usually possible to collect and manually label data; however, many complex machine learning tasks require massive datasets for training. For example, models trained for autonomous vehicle applications need large amounts of data collected from sensors attached to cars or drones. This data collection process is slow and can take months or even years. Once the raw data is collected, it must then be manually annotated by human beings, which is also expensive and time-consuming. Furthermore, there is no guarantee that the labeled data that comes back will be beneficial as training data, since it may not contain examples that inform the model’s current gaps in knowledge.
Labeling this data often involves humans hand-drawing labels on top of sensor data. This is very costly as high paid ML teams often spend a huge portion of their time making sure labels are correct and sending mistakes back to the labelers. A major strength of synthetic data is that you can generate as much perfectly labeled data as you like. All you need is a way to generate quality synthetic data.
Open source software to generate synthetic data: Kubric (multi-object videos with segmentation masks, depth maps, and optical flow) and SDV (tabular, relational, and time series data).
Some (of many) companies that sell products or build platforms that can generate synthetic data include Gretel.ai (synthetic data sets that ensure the privacy of real data), NVIDIA (omniverse), and Parallel Domain (autonomous vehicles). For more, see the 2022 list of synthetic data companies.
Manually Labeling Real Data can sometimes be Impossible

Image from Parallel Domain
There is some data that humans can’t fully interpret and label. Below are some use cases where synthetic data is the only option:
- Accurate estimation of depth and optical flow from single images
- Self-driving applications that utilize radar data that isn’t visible to the human eye
- Generating deep fakes that can be used to test face recognition systems
Real Data has Privacy and Safety Issues

Image by Michael Galarnyk
Synthetic data is highly useful for applications in domains where you can’t easily get real data. This includes some types of car accident data and most types of health data that have privacy restrictions (e.g., electronic health records). In recent years, healthcare researchers have been interested in predicting atrial fibrillation (irregular heart rhythm) using ECG and PPG signals. Developing an arrhythmia detector is not only challenging since annotation of these signals is tedious and costly, but also because of privacy restrictions. This is one reason why there is research in simulating these signals.
It is important to emphasize that collecting real data doesn’t just take time and energy, but can actually be dangerous. One of the core problems with robotic applications like self-driving cars is that they are physical applications of machine learning. You can’t deploy an unsafe model in the real world and have a crash due to a lack of relevant data. Augmenting a dataset with synthetic data can help models avoid these problems.
The following are some companies using synthetic data to improve application safety: Toyota, Waymo, and Cruise.
Real Data is not Programmable

Image from Parallel Domain
Synthetic image of an occluded child on a bicycle emerging from behind a school bus and cycling across the street in a suburban California-style environment.
Autonomous vehicle applications often deal with relatively “uncommon” (relative to normal driving conditions) events like pedestrians at night or bicyclists riding in the middle of the road. Models often need hundreds of thousands or even millions of examples to learn a scenario. One major problem is that the real-world data collected might not be what you are looking for in terms of quality, diversity (e.g., class imbalance, weather conditions, location), and quantity. Another problem is that for self-driving cars and robots, you don’t always know what data you need unlike traditional machine learning tasks with fixed datasets and fixed benchmarks. While some data augmentation techniques that systematically or randomly alter images are helpful, these techniques can introduce their own problems.
This is where synthetic data comes in. Synthetic data generation APIs allow you to engineer datasets. These APIs can save you a lot of money as it is very expensive to build robots and collect data in the real world. It is much better and faster to try to generate data and figure out the engineering principles using synthetic dataset generation.
The following are examples that highlight how programmable synthetic data helps models learn: prevention of fraudulent transactions (American Express), better cyclist detection (Parallel Domain), and surgery analysis and review (Hutom.io).
A Model Trained Exclusively on Real Data is not Performant enough

Phases of the Model Development Cycle | Image from Jules S. Damji
In industry, there are a lot of factors that affect the viability/performance of a machine learning project in both development and production (e.g., data acquisition, annotation, model training, scaling, deployment, monitoring, model retraining, and development velocity). Recently, 18 machine learning engineers took part in an interview study that had the goal of understanding common MLOps practices and challenges across organizations and applications (e.g., autonomous vehicles, computer hardware, retail, ads, recommender systems, etc.). One of the conclusions of the study was the importance of development velocity which can be roughly defined as the ability to rapidly prototype and iterate on ideas.
One factor affecting development velocity is the need to have data to do the initial model training and evaluation as well as frequent model retraining due to model performance decaying over time due to data drift, concept drift, or even train training-serving skew.

Image from Evidently AI
The study also reported that this need led some organizations to set up a team to label live data frequently. This is expensive, time-consuming, and limits an organization's ability to retrain models frequently.
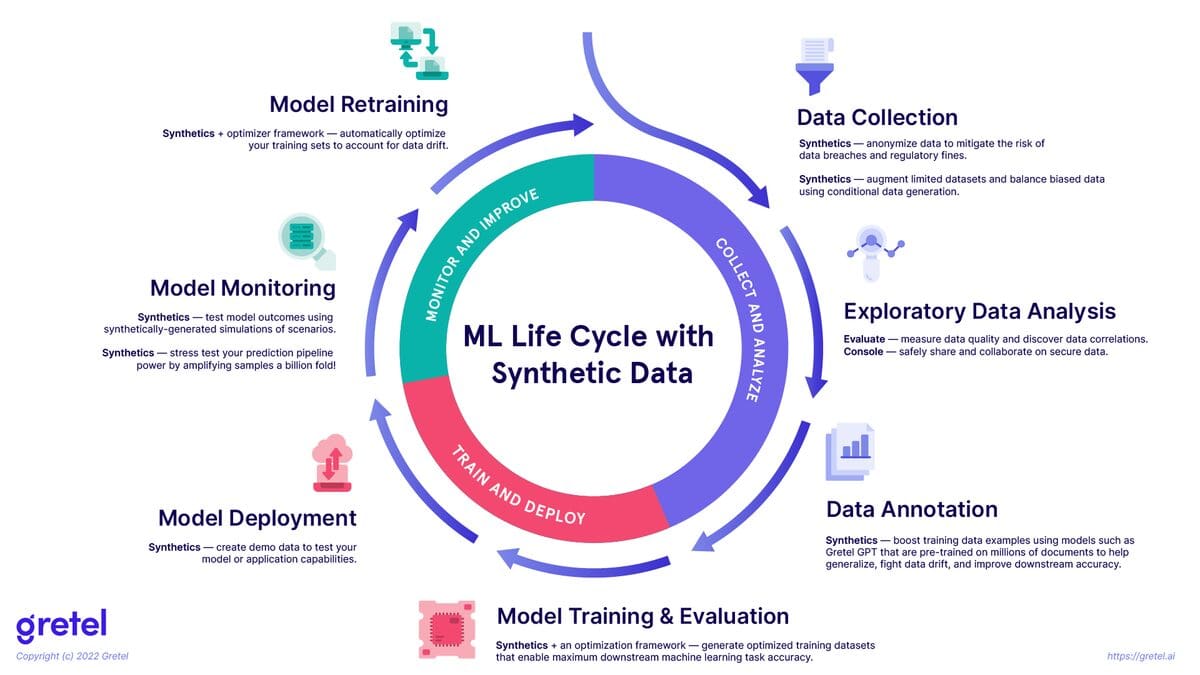
Image from Gretel.ai
Note, this diagram doesn’t cover how synthetic data can also be used for things like MLOps testing in recommenders.
Synthetic data has the potential to be used with real-world data in the machine learning life cycle (pictured above) to help organizations keep their models performant longer.
Conclusion
Synthetic data generation is becoming more and more commonplace in machine learning workflows. In fact, Gartner predicts that by 2030, synthetic data will be used much more than real-world data to train machine learning models. If you have any questions or thoughts on this post, feel free to reach out in the comments below or through Twitter.
Michael Galarnyk is a Data Science Professional, and works in Synthetic Data at Parallel Domain.