
ChatGPT vs Google Bard: A Comparison of the Technical Differences
The Biggest Rivalry: ChatGPT vs Google Bard! Here's a comparison of the technical differences between the two AI engines.

Image by Author
The biggest difference between Google Bard and ChatGPT is that, as of this writing, Bard knows about ChatGPT but ChatGPT is blissfully unaware of Bard. But I can play around with ChatGPT, while Google Bard is still out of reach for most of us.

Source: Screenshot from ChatGPT
The Start of the ChatGPT vs Google Bard Battle
Both ChatGPT and Google Bard are AI chatbots. The simplest version of this technology already exists on your smartphone - you type “Good,” and your phone predicts that the next word you might want to use is “morning.”
ChatGPT was originally developed by OpenAI and then invested in by Microsoft for an eye-watering $10 billion (in addition to an earlier $1 billion investment). Google, panicking slightly that their search monopoly might be at an end, responded by unveiling Bard, their version of the technology with some flaws. In its very first live demo, Bard made several factual errors. Embarrassing for Google, to say the least.
ChatGPT and Google Bard are a little more sophisticated than smartphone predictive text, but to understand the differences between the two AI chatbots, that’s all you need to know to start with.
Let’s take a deeper look at the technical differences between these two AI engines.
ChatGPT vs Bard: What’s under the hood?
You’re here for a quick, easy table to get the technical differences between the two engines. Here’s exactly that. If you want a more nuanced look, feel free to scroll further.
| ChatGPT | Bard | |
| Model | GPT-3.5 | LaMDA, or Language Model for Dialogue Applications |
| Neural network architecture | Transformer | Transformer |
| Training data | Web text, primarily a dataset called “common crawl,” cut off mid-2021 | 1.56 million words of public dialog data and web text |
| Purpose | To be an all-purpose text-generation chatbot | Specifically to help assist search |
| Parameters | 175 billion parameters | 137 billion parameters |
| Creator | OpenAI | |
| Advantages | - Open to all right now
- More flexible and capable of open-ended text - Training data cut off at 2021 |
- Training data through present day
- Trained specifically for dialogue, so it sounds more human when you use it to speak |
| Weaknesses | - Dialogue is not as convincing
- Not as carefully fine-tuned |
- Not currently available
- May not be as well suited to general text creation |
Now you’ve got the TL;DR, let’s get a deeper look into all these metrics.
What is ChatGPT?
ChatGPT burst onto the scene on November 30th, 2022. By December 4th, 2022, the service had over a million daily users. In January 2023, that number ballooned to over 100 million users.
It was instantly popular for the basic reason that it could offer you solid responses across a number of topics in a way that sounded almost human, and it was accessible to anyone with an internet connection.
ChatGPT was created by OpenAI, a San Francisco-based AI lab that focuses on creating a friendly AI. The chatbot sits on GPT-3.5, which is a large language model that, when given text, can continue the prompt.
ChatGPT got some extra training on top of that – human trainers improved the model by interacting with it and “rewarded” the model for higher-quality answers.
Training data
GPT-3.5 was trained on a huge data set of web text, including a popular dataset called Common Crawl. Common Crawl contains petabytes of web data with raw web page data, metadata extracts, and text extracts. It includes, for instance, a collection of our own URLs from StrataScratch. Isn’t it wild to think ChatGPT was trained using websites we go on every day?
Common Crawl was responsible for 60% of the training data, but GPT-3.5 also got data from other sources.
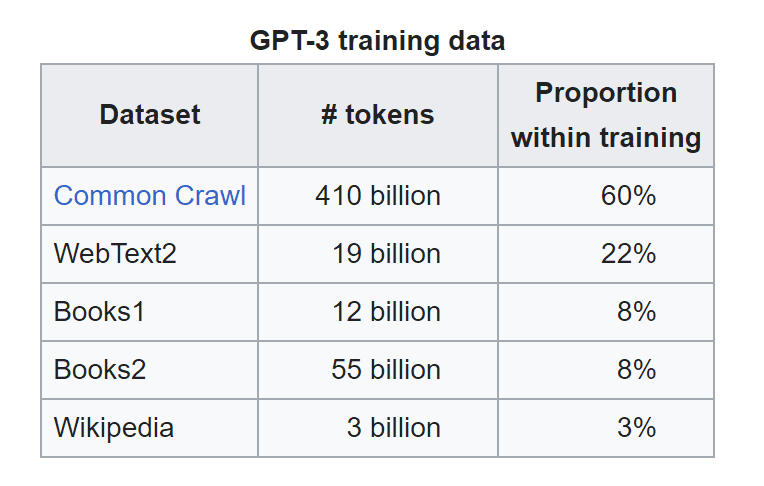
Source: Wikipedia
What is Google Bard?
Bard is Google’s answer to ChatGPT’s popularity. Unlike ChatGPT, Bard is powered by Google’s own model LaMDA, which is short for Language Model for Dialogue Applications. And unlike ChatGPT, it’s not as exciting for the simple reason that most people can’t access it yet. Though Google did host an error-laden demo of Bard in early February, right now it’s only available to a select few.
The main advantage of Google’s Bard is that it’s open to the internet. Ask ChatGPT who the president is, and it doesn’t know. This is because the training data was cut off around mid-2021. Bard, meanwhile, draws on information on the internet today. Ask Bard, and in theory, Bard should be able to pull from the data available on the internet today to tell you who the president is.
Although you can’t take it for a spin just yet, it’s easy to see how Bard stands out from ChatGPT in a few key respects.
Source: Google’s blog post about LaMDA
Training data
First, LaMDA was trained in dialogue, specifically for talking in conversation, not just producing text like GPT-n models are. While ChatGPT makes no secret of its training data, we just don’t know that much - yet - about the data that Bard was trained on.
We can extrapolate a little bit by looking at LaMDA’s research paper. Google’s researchers said that 12.5% of the training data came from Common Crawl, like GPT-n models. Another 12.5% comes from Wikipedia. And according to the research paper, they used 1.56 trillion words of “public dialog data and web text.”
Here’s the full breakdown:
| 12.5% C4-based data (a derivative of Common Crawl data) |
| 12.5% English language Wikipedia |
| 12.5% code documents from programming Q&A websites, tutorials, and others |
| 6.25% English web documents |
| 6.25% Non-English web documents |
| 50% dialogs data from public forums |
We know the Common Crawl data, and obviously you know Wikipedia. The rest? It’s intentionally hidden, presumably to keep Bard (and LaMDA) safe from copycats.
LaMDA was built by fine-tuning a family of Transformer-based neural language models, which are an open-source neural network architecture originally developed by Google. (Fun side note - GPT is also built on Transformer.)

Source: Google’s blog post about Bard
ChatGPT has some guardrails to keep it from getting too nasty or spouting complete nonsense, but Google has made a real point of highlighting how they’ve carefully created quality assurances to make Bard a better, safer chatbot to use. Bard is fine-tuned to promote “quality, groundedness, and safety.”
Google has a lot to say about this, and I recommend reading their blog post about it, but if you’re short on time, it basically breaks down to this:
- Bard should give responses that make sense – nothing absurd, no contradictions
- Bard should give responses that are insightful, witty, or unexpected in a good way
- Bard should avoid anything that risks harm to the user - gore, bias, hateful stereotypes to mention a few
- Bard shouldn’t make stuff up
Thanks to a faulty launch, we already know that Google hasn’t quite figured out that bottom requirement. But it is notable that Google is speaking so clearly about these design requirements in a way that ChatGPT just hasn’t – at least not yet.
ChatGPT vs Google Bard: The model parameter and why does it matter?
ChatGPT does have more model parameters than Bard - 175 billion versus 137 billion. You can think of parameters as knobs or levers that the model adjusts to fit the data it's being trained on. More parameters generally mean that the model has more capacity to capture complex relationships in language, but it also runs the risk of overfitting.
Google Bard may be less flexible, but may also be more robust to new language use cases compared to ChatGPT.
ChatGPT vs Google Bard: What they have in common?
It’s worth highlighting that both Bard and ChatGPT sit on models (LaMDA and GPT-3.5 respectively) that sit on Transformer-based deep-learning neural networks.
Transformer can make a model that’s trained to read a sentence or paragraph, for example, pay attention to how those words relate to one another and then predict what words it thinks will come next – similar to your smartphone’s predictive text, as I mentioned earlier.
I won’t get too into the weeds here, but all you need to know is that this means that at their core, Bard and ChatGPT aren’t too different from each other.
ChatGPT vs Google Bard: Ownership
While ownership is not exactly a technical difference, it is worth keeping in mind.
Google Bard is produced and owned wholly by Google, on top of LaMDA, which is also created by Google.
ChatGPT is developed by OpenAI, a San Francisco-based AI research lab. OpenAI was originally nonprofit but it did create a for-profit subsidiary back in 2019. OpenAI was also behind Dall-E, the AI text-to-image generation you may have played around with.
While Microsoft has invested a lot of money in OpenAI, it is, for the moment, an independent research organization.
Which is Best, ChatGPT or Google Bard?
It’s hard to give a fair answer to this question because they’re both so similar, yet so different. For one, almost nobody can access Google Bard right now. For another, ChatGPT’s training data were cut off almost two years ago.
Both are text generators - you offer a prompt, and both Google Bard and ChatGPT can answer it. Both have billions of parameters to fine-tune the model. Both have overlapping training data sources, and both are built on Transformer, the same neural network model.
They’re designed for different purposes, too. Bard will help you navigate Google search. It’s designed to be conversational. ChatGPT can generate entire blog posts. It’s designed to spit out chunks of text that make sense.
Ultimately, the technical differences between ChatGPT and Google Bard just underline how far AI-powered text generation technology has come. While they both have a ways to go, and both have faced controversy on the copyright and ethics side of things, both generators are powerful demonstrations of modern AI models.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Connect with him on Twitter: StrataScratch or LinkedIn.