Time Series Forecasting with statsmodels and Prophet
Easy forecast model development with the popular time series Python packages.
Image by jcomp on Freepik
Time series is a unique dataset within the data science field. The data is recorded on time-frequency (e.g., daily, weekly, monthly, etc.), and each observation is related to the other. The time series data is valuable when you want to analyze what happens to your data over time and create future predictions.
Time series forecasting is a method to create future predictions based on historical time series data. There are many statistical methods for time series forecasting, such as ARIMA or Exponential Smoothing.
Time series forecasting is often encountered in the business, so it’s beneficial for the data scientist to know how to develop a time series model. In this article, we will learn how to forecast time series using two popular forecastings Python packages; statsmodels and Prophet. Let’s get into it.
Time Series Forecasting with statsmodels
The statsmodels Python package is an open-source package offering various statistical models, including the time series forecasting model. Let’s try out the package with an example dataset. This article will use the Digital Currency Time Series data from Kaggle (CC0: Public Domain).
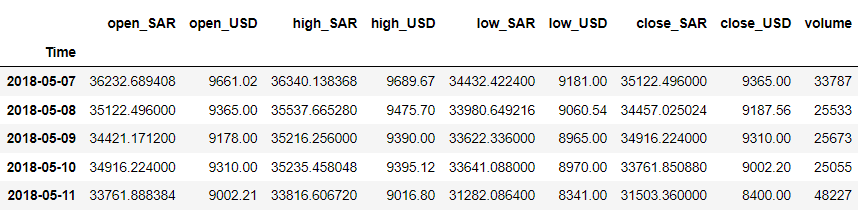
Let’s clean up the data and take a look at the dataset that we have.
import pandas as pd
df = pd.read_csv('dc.csv')
df = df.rename(columns = {'Unnamed: 0' : 'Time'})
df['Time'] = pd.to_datetime(df['Time'])
df = df.iloc[::-1].set_index('Time')
df.head()
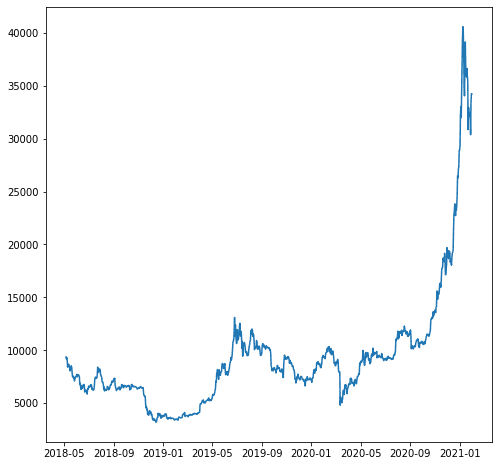
For our example, let’s say we want to forecast the ‘close_USD’ variable. Let’s see how the data pattern over time.
import matplotlib.pyplot as plt
plt.plot(df['close_USD'])
plt.show()
Let’s build the forecast model based on our above data. Before modeling, let’s split the data into train and test data.
# Split the data
train = df.iloc[:-200]
test = df.iloc[-200:]
We don’t split the data randomly because it’s time series data, and we need to preserve the order. Instead, we try to have the train data from earlier and the test data from the latest data.
Let’s use statsmodels to create a forecast model. The statsmodel provides many time series model APIs, but we would use the ARIMA model as our example.
from statsmodels.tsa.arima.model import ARIMA
#sample parameters
model = ARIMA(train, order=(2, 1, 0))
results = model.fit()
# Make predictions for the test set
forecast = results.forecast(steps=200)
forecast
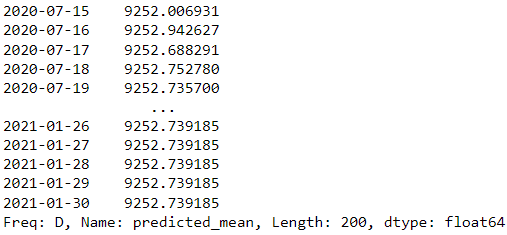
In our example above, we use the ARIMA model from statsmodels as the forecasting model and try to predict the next 200 days.
Is the model result good? Let’s try to evaluate them. The time series model evaluation usually uses a visualization graph to compare the actual and prediction with regression metrics such as Mean Absolute Error (MAE), Root Mean Square Error (RMSE), and MAPE (Mean Absolute Percentage Error).
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np
#mean absolute error
mae = mean_absolute_error(test, forecast)
#root mean square error
mse = mean_squared_error(test, forecast)
rmse = np.sqrt(mse)
#mean absolute percentage error
mape = (forecast - test).abs().div(test).mean()
print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"MAPE: {mape:.2f}%")
MAE: 7956.23
RMSE: 11705.11
MAPE: 0.35%
The score above looks fine, but let’s see how it is when we visualize them.
plt.plot(train.index, train, label='Train')
plt.plot(test.index, test, label='Test')
plt.plot(forecast.index, forecast, label='Forecast')
plt.legend()
plt.show()
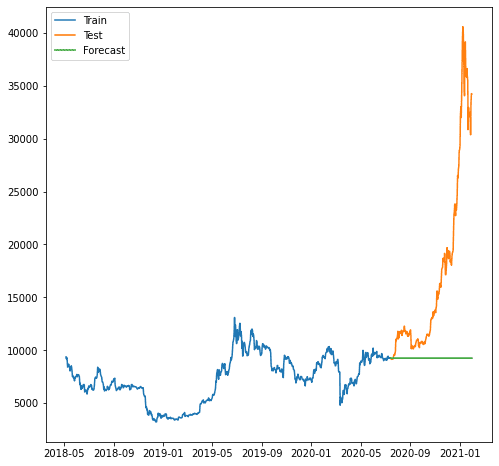
As we can see, the forecast was worse as our model can’t forecast the increasing trend. The model ARIMA that we use seems too simple for forecasting.
Maybe it’s better if we try using another model outside of statsmodels. Let’s try out the famous prophet package from Facebook.
Time Series Forecasting with Prophet
Prophet is a time series forecasting model package that works best on data with seasonal effects. Prophet was also considered a robust forecast model because it could handle missing data and outliers.
Let’s try out the Prophet package. First, we need to install the package.
pip install prophet
After that, we must prepare our dataset for the forecasting model training. Prophet has a specific requirement: the time column needs to be named as ‘ds’ and the value as ‘y’.
df_p = df.reset_index()[["Time", "close_USD"]].rename(
columns={"Time": "ds", "close_USD": "y"}
)
With our data ready, let’s try to create forecast prediction based on the data.
import pandas as pd
from prophet import Prophet
model = Prophet()
# Fit the model
model.fit(df_p)
# create date to predict
future_dates = model.make_future_dataframe(periods=365)
# Make predictions
predictions = model.predict(future_dates)
predictions.head()
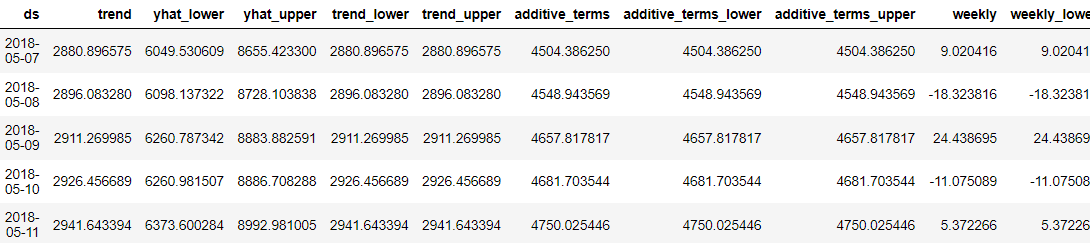
What was great about the Prophet was that every forecast data point was detailed for us users to understand. However, it is hard to understand the result just from the data. So, we could try to visualize them using Prophet.
model.plot(predictions)
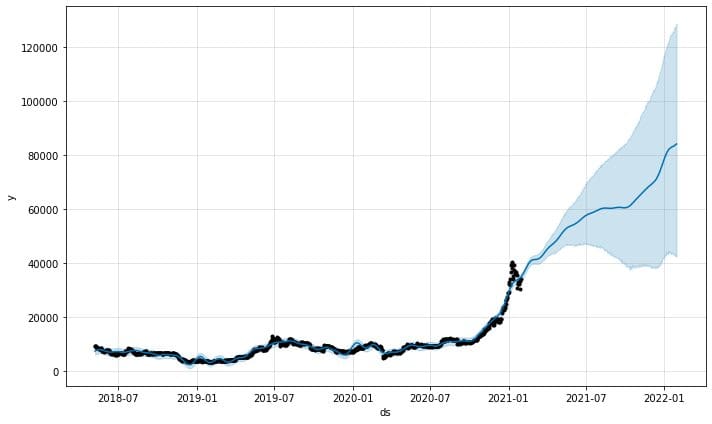
The predictions plot function from the model would provide us with how confident the predictions were. From the above plot, we can see that the prediction has an upward trend but with increased uncertainty the longer the predictions are.
It is also possible to examine the forecast components with the following function.
model.plot_components(predictions)
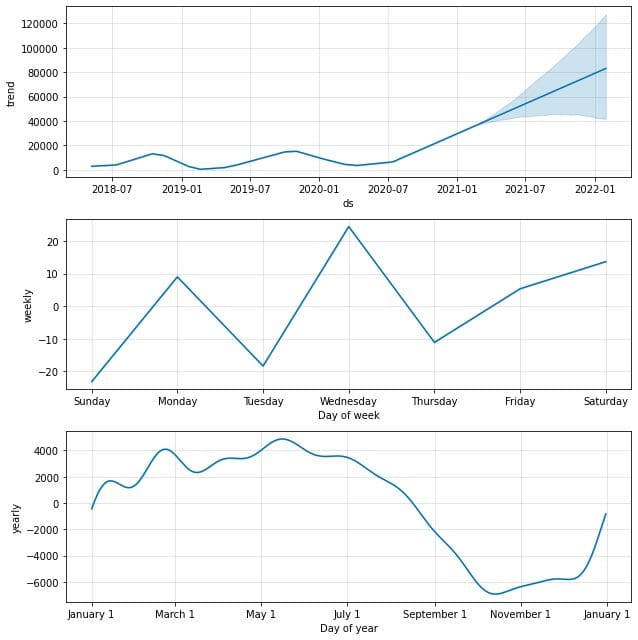
By default, we would obtain the data trend with yearly and weekly seasonality. It’s a good way to explain what happens with our data.
Would it be possible to evaluate the Prophet model as well? Absolutely. Prophet includes a diagnostic measurement that we can use: time series cross-validation. The method uses part of the historical data and fits the model each time using data up to the cutoff point. Then the Prophet would compare the predictions with the actual ones. Let’s try using the code.
from prophet.diagnostics import cross_validation, performance_metrics
# Perform cross-validation with initial 365 days for the first training data and the cut-off for every 180 days.
df_cv = cross_validation(model, initial='365 days', period='180 days', horizon = '365 days')
# Calculate evaluation metrics
res = performance_metrics(df_cv)
res
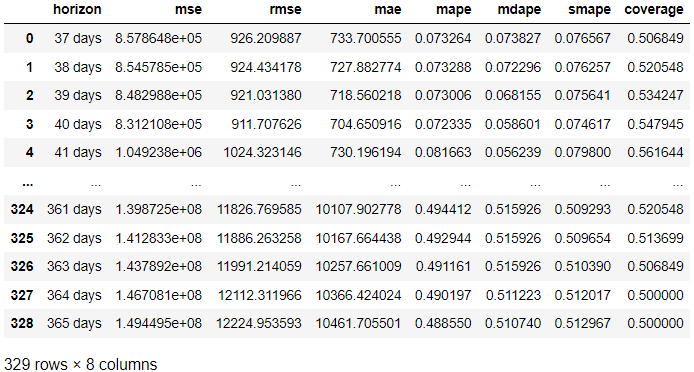
In the result above, we acquired the evaluation result from the actual result compared to the forecast in each forecast day. It’s also possible to visualize the result with the following code.
from prophet.plot import plot_cross_validation_metric
#choose between 'mse', 'rmse', 'mae', 'mape', 'coverage'
plot_cross_validation_metric(df_cv, metric= 'mape')
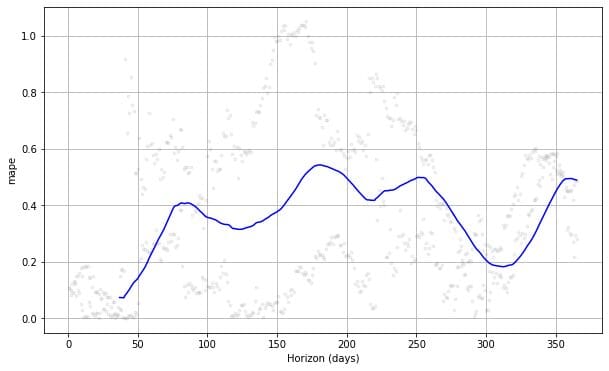
If we see the plot above, we can see the prediction error was vary following the days, and it could achieve 50% error at some points. This way, we might want to tweak the model further to fix the error. You can check the documentation for further exploration.
Conclusion
Forecasting is one of the common cases that occur in the business. One easy way to develop a forecasting model is using the statsforecast and Prophet Python packages. In this article, we learn how to create a forecast model and evaluate them with statsforecast and Prophet.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and Data tips via social media and writing media.