Best Architecture for Your Text Classification Task: Benchmarking Your Options
We want to show a real-life example of text classification models based on the most recent algorithms and pre-trained models with their respective benchmarks.

Image by Editor
In our previous article, we covered a variety of approaches to building a text classification model based on what modern NLP currently has to offer.
With old-school TF-IDF approaches, pre-trained embedding models, and transformers of various shapes and sizes to choose from, we wanted to give some practical advice based on our own experience. Which models are best suited for different situations? What are some use cases you can find in your own line of work?
To add extra flavor, we want to show you a real-life example of benchmarks for those different approaches and compare them using a dataset we chose for this quick follow-up article.
Describing the Dataset and Task
To illustrate our ideas, we chose The Twitter Financial News, an English-language dataset containing an annotated corpus of finance-related tweets. It’s commonly used to build finance-related content classification models that sort tweets into a number of topics.
It’s a medium-sized dataset, which is perfect for us to illustrate how different models perform. Also fairly diverse, the size allows us to train and evaluate models relatively quickly.
What’s interesting about this domain is that financial language is usually crisp and laconic. There are plenty of proper nouns describing brands, terms, and related entities, and the models need to learn to distinguish them from common nouns with completely different meanings. Intuitively, fine-tuning pre-trained generic-language models in this domain should boost overall performance and accuracy.
The dataset consists of around 21,000 items. Not too small, it’s also not too large, making it perfect for showing off the advantages and disadvantages of each model and approach. Let’s come back to this once we have the results.
And finally, the dataset has 20 classes. It’s no common classification task, where you have to distinguish between a handful of sentiment classes and emotional tones. There’s an imbalance too. With a 60x+ difference between the most and least frequent classes, some approaches can be expected to underperform.
Let’s see how different models will perform in our benchmarking test.
Describing the Approach
Based on our previous article, FastText, BERT, RoBERTa (with second-stage tuning), and GPT-3 are our choices for assessing their performance and efficiency. The dataset was split into training and test sets with 16,500 and 4500 items, respectively. After the models were trained on the former, their performance and efficiency (inference time) were measured on the latter.
To train a FastText model, we used the fastText library with the corresponding command line tool. We prepared the dataset by inserting labels into texts with the proper prefix, ran the fasttext supervised command to train a classifier, and waited a couple minutes to produce the model on a CPU-only machine. The next command, fasttext predict, gave us predictions for the test set and model performance.
As for transformers, we chose three slightly different models to compare: BERT (more formal, best-base-uncased), RoBERTa-large, and an adapted version of the latter tuned for sentiment classification on a couple finance-related datasets (check it out on the HuggingFace website). The transformers library stood in for our experiments, though it entails writing some code to actually run training and evaluation procedures. A single machine with the A100 GPU handled training, which took 20–28 minutes until early stopping conditions were met for each model. The trained models were stored in a MLFlow registry.
To train a classifier based on the GPT-3 model, we referred to the official documentation on the OpenAI website and used the corresponding command line tool to submit data for training, track its progress, and make predictions for the test set (more formally, completions, a better term for generative models). Since the work itself happened on OpenAI’s servers, we didn’t use any particular hardware. It only took a regular laptop to create a cloud-based model. We trained two GPT-3 variations, Ada and Babbage, to see if they would perform differently. It takes 40–50 minutes to train a classifier in our scenario.
Once training was complete, we evaluated all the models on the test set to build classification metrics. We chose macro average F1 and weighted average F1 to compare them, as that let us estimate both precision and recall in addition to seeing if dataset imbalance influenced the metrics. The models were compared on their inference speed in milliseconds per item with a batch size of one. For the RoBERTa model, we also include an ONNX-optimized version as well as inference using an A100 GPU accelerator. Measuring the average response time from our tuned Babbage model gave us the GPT-3 speed (note that OpenAI applies some rate limiters, so the actual speed might be lower or higher depending on your terms of use).
Results
How did the training work out? We arranged the results in a couple tables to show you the end product and the effect we observed.
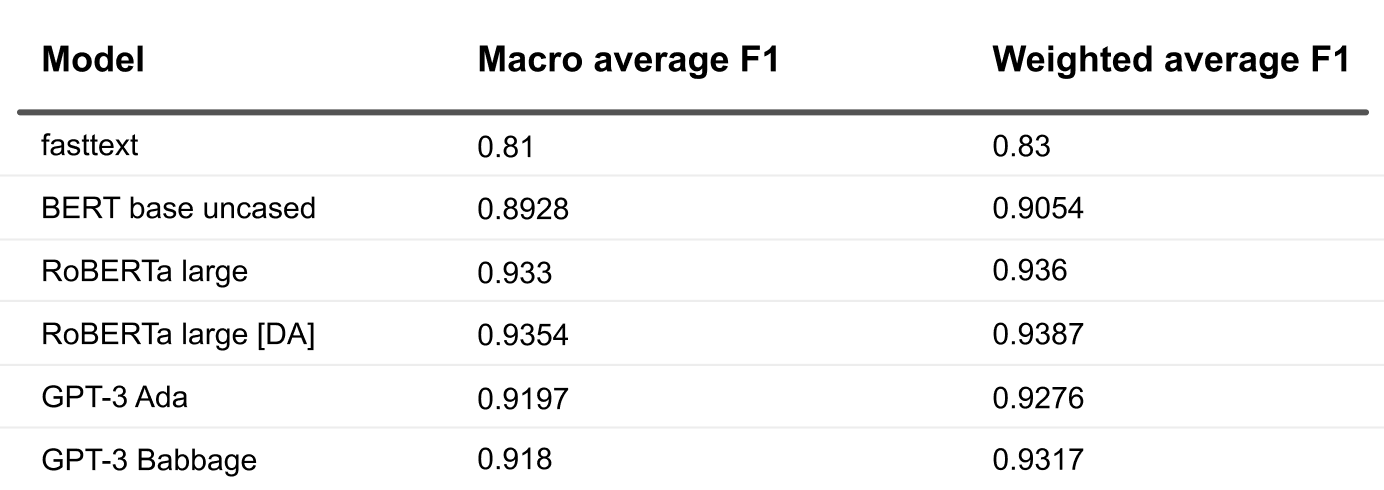
Photo by Author
What caught our eye first is that fasttext lagged far behind. With that said, it took minimal resources in terms of computation, time, and training, and it gave us a low bar benchmark.
How about the transformers? As expected, RoBERTa delivered better results than BERT, which is easy to attribute to the size advantage it had. It’s also generally better with domain-specific classification tasks. To be fair, we specifically selected a large RoBERTa architecture for this comparison, and the base RoBERTa model might have performed similarly to BERT despite differences in the underlying corpus and training methodology.
The tangible gap between the F1 metrics for BERT and RoBERTa could also have been caused by the fact that we’re dealing with a fairly large number of classes. The dataset has imbalances that larger models tend to capture better. But that’s just our suspicion and proving it would require more experimentation. You can also see that the domain-pretrained RoBERTa offered a tiny accuracy boost, though it’s insignificant. It’s hard to say if the pre-trained domain-tuned model was actually worthwhile for our experiment.
Next comes GPT-3. We selected the Ada and Babbage models for a fair comparison with BERT and RoBERTa-large since they have excellent parameter sizes that grow gradually (from 165 million parameters in BERT and 355 million in RoBERTa-large to 2.7 billion in Ada and 6.7 billion in Babbage) and can show whether the model size really gives a proportional performance boost. Surprisingly, Ada and Babbage both deliver almost the same metrics, and they actually lose to RoBERTa even without domain-specific pre-training. But there’s a reason for that. Remember that GPT-3 API-accessible models actually give users a generative inference interface, so they try to predict a token that would classify each example in the classification task. RoBERTa and other models from transformers, on the other hand, have the last layers of their architecture configured correctly for classification. Imagine a proper logit or softmax at the end that returns the likelihood of all the classes for any data item you pass to it. While the huge GPT-3 would be sufficient to tackle classification for one of 20 classes by generating the right token class, it’s overkill here. Let’s just not forget that the GPT-3 model is fine-tuned and accessed with just three lines of code, unlike RoBERTa, which takes work to roll out on your architecture.
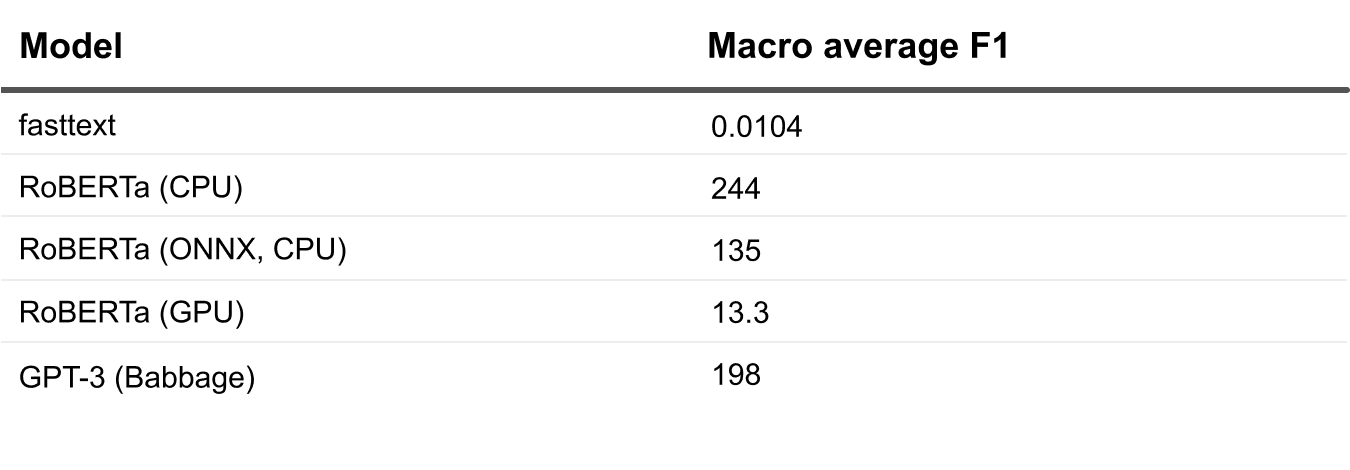
Photo by Author
Let’s now finally compare the models and their inference setups in terms of their request execution speed. Since we’re not just training them for performance and accuracy, we need to take into account how fast they return us their inference for new data. We clocked the online synchronous requests to the models and tried to understand the best niche for each.
The winner here is fasttext. Its accuracy, however, forces us to keep moving down the list.
Between the RoBERTa and GPT-3 setups, we can see that GPT-3 is relatively fast despite being the largest, especially given that its response time includes two-sided network communication to their API endpoint. The actual inference here is small. That’s obviously good, especially since this is a pretty simple solution to set up, fine-tune, and implement model calls for. While it can be expensive, especially if you plan on sending a lot of data frequently, the cost-benefit decision is up to you.
The GPU-hosted version is the winner among the RoBERTa setups. The GPUs add a huge performance boost to inference computations, though hosting your model server on GPU machines might price the project out of your budget. Rolling out a GPU-based model server can also be tricky, especially if you haven’t done it before.
You also need to remember that despite these benchmarks are all being fast in terms of returning the results of your model requests, you shouldn’t forget to do some planning and break down how you plan to use the models in your project. Real-time inference or asynchronous batch requests? Accessed over the internet or within your local network? Do you have overhead for your business logic operations on top of the model response? All that can add much more time overhead to each request over the actual model inference calculation itself.
Conclusions and Follow-up Ideas
What have we learned? We tried to demonstrate a real-life example of the balance between the difficulty of running various models, their resulting accuracy metrics, and their response speed when they are ready to be used. Obviously, figuring out what to use when and how given your project is a challenge. But we hope to leave you with some guidance?—?there’s no silver bullet when it comes to GPT models. We all have to count our money as well, especially when it comes to machine learning.
Here at Toloka, we’re working hard on a platform that will enable users to train, deploy, and use a transformer like RoBERTa with the same three API calls as GPT-3 API.
In our next article, we’ll run a couple more experiments on how to mitigate the effects of disbalanced datasets and upsample or downsample classes for balance. Our suspicion is that the GPT-3 generative approach will perform better than RoBERTa-large. We’ll also discuss how these results might change if we take on a much smaller dataset, and we point out exactly when and where GPT-3+ models will outperform all the others in classification tasks. Stay tuned and check out more of our work over at the Toloka ML team’s blog.
Aleksandr Makarov is a senior product manager in Toloka.ai leading the product development of Toloka.ai ML platform, a former healthtech entrepreneur and co-founder of Droice Labs