Multilabel Classification: An Introduction with Python’s Scikit-Learn
Learn how to develop Multilabel Classifier in your work.

Image by Freepik
In machine learning tasks, classification is a supervised learning method to predict the label given the input data. For example, we want to predict if someone is interested in the sales offering using their historical features. By training the machine learning model using available training data, we can perform the classification tasks to incoming data.
We often encounter classic classification tasks such as binary classification (two labels) and multiclass classification (more than two labels). In this case, we would train the classifier, and the model would try to predict one of the labels from all the available labels. The dataset used for the classification is similar to the image below.
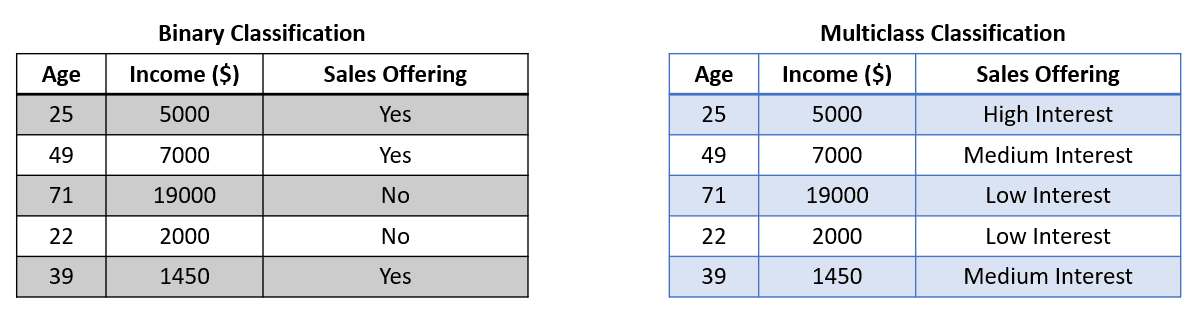
The image above shows that the target (Sales Offering) contains two labels in Binary Classification and three in the Multiclass Classification. The model would train from the available features and then output one label only.
Multilabel Classification is different from Binary or Multiclass Classification. In Multilabel Classification, we don’t try to predict only with one output label. Instead, Multilabel Classification would try to predict data with as many labels as possible that apply to the input data. The output could be from no label to the maximum number of available labels.
Multilabel Classification is often used in the text data classification task. For example, here is an example dataset for Multilabel Classification.
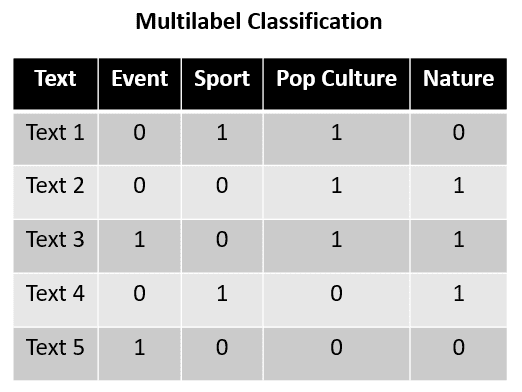
In the example above, imagine Text 1 to Text 5 is a sentence that can be categorized into four categories: Event, Sport, Pop Culture, and Nature. With the training data above, the Multilabel Classification task predicts which label applies to the given sentence. Each category is not against the other as they are not mutually exclusive; each label can be considered independent.
For more detail, we can see that Text 1 labels Sport and Pop Culture, while Text 2 labels Pop Culture and Nature. This shows that each label was mutually exclusive, and Multilabel Classification can have prediction output as none of the labels or all the labels simultaneously.
With that introduction, let’s try to build Multiclass Classifier with Scikit-Learn.
Multilabel Classification with Scikit-Learn
This tutorial will use the publicly available Biomedical PubMed Multilabel Classification dataset from Kaggle. The dataset would contain various features, but we would only use the abstractText feature with their MeSH classification (A: Anatomy, B: Organism, C: Diseases, etc.). The sample data is shown in the image below.
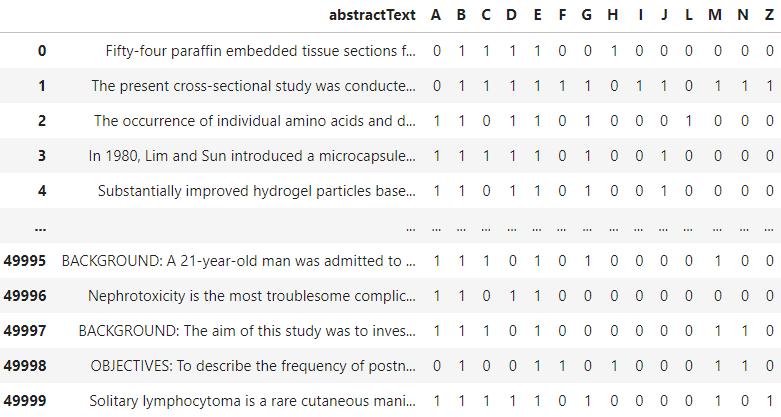
The above dataset shows that each paper can be classified into more than one category, the cases for Multilabel Classification. With this dataset, we can build Multilabel Classifier with Scikit-Learn. Let’s prepare the dataset before we train the model.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
df = pd.read_csv('PubMed Multi Label Text Classification Dataset Processed.csv')
df = df.drop(['Title', 'meshMajor', 'pmid', 'meshid', 'meshroot'], axis =1)
X = df["abstractText"]
y = np.asarray(df[df.columns[1:]])
vectorizer = TfidfVectorizer(max_features=2500, max_df=0.9)
vectorizer.fit(X)
In the code above, we transform the text data into TF-IDF representation so our Scikit-Learn model can accept the training data. Also, I am skipping the preprocessing data steps, such as stopword removal, to simplify the tutorial.
After data transformation, we split the dataset into training and test datasets.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=101)
X_train_tfidf = vectorizer.transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)
After all the preparation, we would start training our Multilabel Classifier. In Scikit-Learn, we would use the MultiOutputClassifier object to train the Multilabel Classifier model. The strategy behind this model is to train one classifier per label. Basically, each label has its own classifier.
We would use Logistic Regression in this sample, and MultiOutputClassifier would extend them into all labels.
from sklearn.multioutput import MultiOutputClassifier
from sklearn.linear_model import LogisticRegression
clf = MultiOutputClassifier(LogisticRegression()).fit(X_train_tfidf, y_train)
We can change the model and tweak the model parameter that passed into the MultiOutputClasiffier, so manage according to your requirements. After the training, let’s use the model to predict the test data.
prediction = clf.predict(X_test_tfidf)
prediction
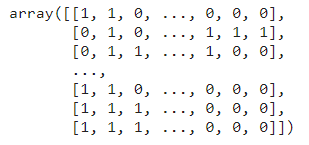
The prediction result is an array of labels for each MeSH category. Each row represents the sentence, and each column represents the label.
Lastly, we need to evaluate our Multilabel Classifier. We can use the accuracy metrics to evaluate the model.
from sklearn.metrics import accuracy_score
print('Accuracy Score: ', accuracy_score(y_test, prediction))
Accuracy Score: 0.145
The accuracy score result is 0.145, which shows that the model only could predict the exact label combination less than 14.5% of the time. However, the accuracy score contains weaknesses for a multilabel prediction evaluation. The accuracy score would need each sentence to have all the label presence in the exact position, or it would be considered wrong.
For example, the first-row prediction only differs by one label between the prediction and test data.
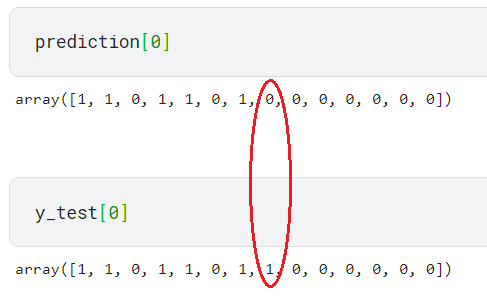
It would be considered a wrong prediction for the accuracy score as the label combination differs. That is why our model has a low metric score.
To mitigate this problem, we must evaluate the label prediction rather than their label combination. In this case, we can rely on Hamming Loss evaluation metric. Hamming Loss is calculated by taking a fraction of the wrong prediction with the total number of labels. Because Hamming Loss is a loss function, the lower the score is, the better (0 indicates no wrong prediction and 1 indicates all the prediction is wrong).
from sklearn.metrics import hamming_loss
print('Hamming Loss: ', round(hamming_loss(y_test, prediction),2))
Hamming Loss: 0.13
Our Multilabel Classifier Hamming Loss model is 0.13, which means that our model would have a wrong prediction 13% of the time independently. This means each label prediction might be wrong 13% of the time.
Conclusion
Multilabel Classification is a machine-learning task where the output could be no label or all the possible labels given the input data. It’s different from binary or multiclass classification, where the label output is mutually exclusive.
Using Scikit-Learn MultiOutputClassifier, we could develop Multilabel Classifier where we train a classifier to each label. For the model evaluation, it’s better to use Hamming Loss metric as the Accuracy score might not give the whole picture correctly.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and Data tips via social media and writing media.