A Step-by-Step Guide to Web Scraping with Python and Beautiful Soup
Learn the basics of Web Scraping and its Python implementation. Also, get to know about the various methods of Beautiful Soup library.

Image by Author
Web scraping is a technique that is used for extracting HTML content from different websites. These web scrapers are mainly computer bots that can directly access the World Wide Web using HTTP Protocol and use this information in various applications. The data is obtained in an unstructured format, which is then converted into a structured manner after performing multiple pre-processing steps. Users can save this data in a spreadsheet or export it through an API.
Web scraping can also be done manually for small web pages by simply copying and pasting the data from the web page. But this copy and pasting would not work if we require data at a large scale and from multiple web pages. Here automated web scrapers come into the picture. They use intelligent algorithms which can extract large amounts of data from numerous web pages in less time.
Uses of Web Scraping
Web scraping is a powerful tool for businesses to gather and analyze information online. It has multiple applications across various industries. Below are some of these that you can check out.
- Marketing: Web scraping is used by many companies to collect information about their products or services from various social media websites to get a general public sentiment. Also, they extract email ids from various websites and then send bulk promotional emails to the owners of these email ids.
- Content Creation: Web scraping can gather information from multiple sources like news articles, research reports, and blog posts. It helps the creator to create quality and trending content.
- Price Comparison: Web scraping can be used to extract the prices of a particular product across multiple e-commerce websites to give a fair price comparison for the user. It also helps companies fix the optimal pricing of their products to compete with their competitors.
- Job Postings: Web Scraping can also be used to collect data on various job openings across multiple job portals so that this information can help many job seekers and recruiters.
Now, we will create a simple web scraper using Python and Beautiful Soup library. We will parse an HTML page and extract useful information from it. This tutorial requires a basic understanding of Python as its only prerequisite.
Code Implementation
Our implementation consists of four steps which are given below.
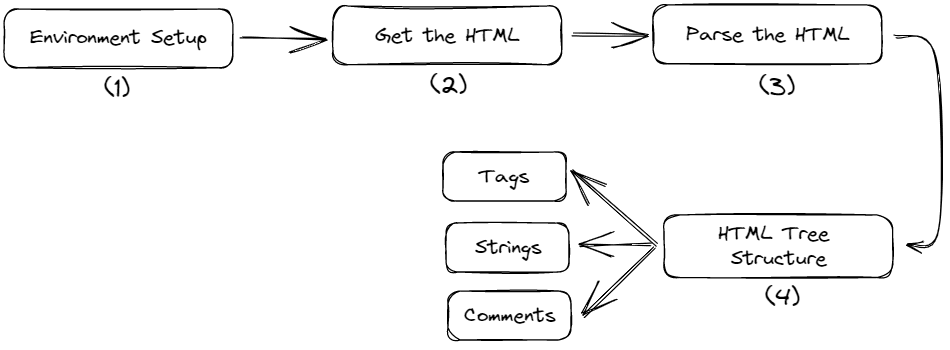
Fig. 1 Tutorial Steps | Image by Author
Setting Up the Environment
Create a separate directory for the project and install the below libraries using the command prompt. Creating a virtual environment first is preferable, but you can also install them globally.
$ pip install requests
$ pip install bs4
The requests module extracts the HTML content from a URL. It extracts all the data in a raw format as a string that needs further processing.
The bs4 is the Beautiful Soup module. It will parse the raw HTML content obtained from the `request` module in a well-structured format.
Get the HTML
Create a Python file inside that directory and paste the following code.
import requests
url = "https://www.kdnuggets.com/"
res = requests.get(url)
htmlData = res.content
print(htmlData)
Output:
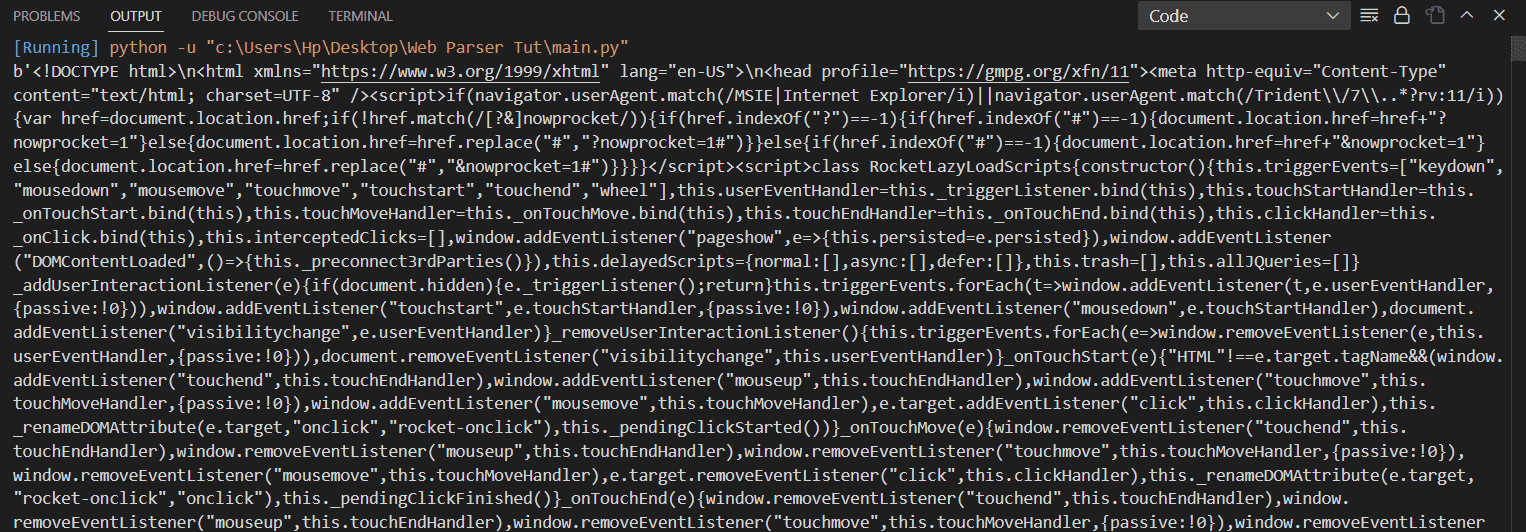
Image by Author
This script will extract all the raw HTML content from the URL `/`. This raw data contains all the texts, paragraphs, anchor tags, divs, etc. Our next task is to parse that data and extract all the texts and tags separately.
Parse the HTML
Here the role of Beautiful Soup comes in. It is used to parse and prettify the raw data obtained above. It creates a tree-like structure of our DOM, which can be traversed along the tree branches and able to find the target tags and objects.
import requests
from bs4 import BeautifulSoup
url = "https://www.kdnuggets.com/"
res = requests.get(url)
htmlData = res.content
parsedData = BeautifulSoup(htmlData, "html.parser")
print(parsedData.prettify())
Output:
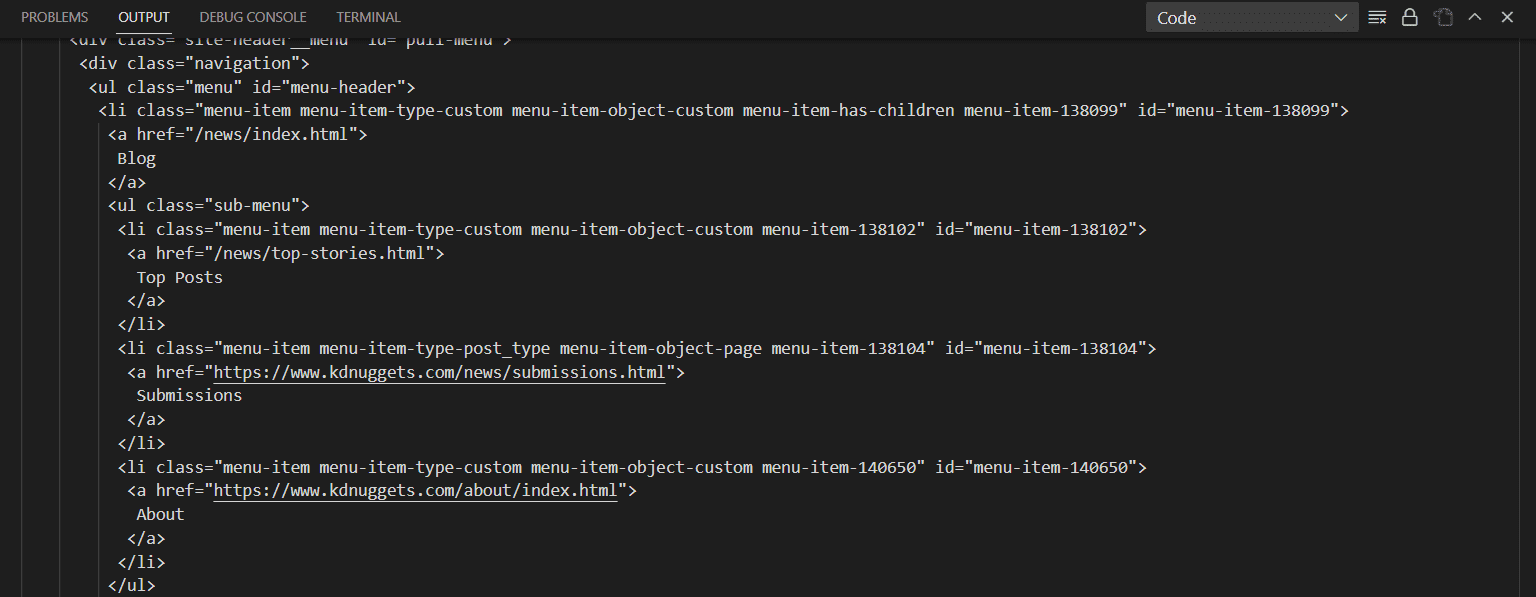
Image by Author
You can see in the above output that Beautiful Soup has presented the content in a more structured format with proper indentations. The function BeautifulSoup() takes two arguments, one is the input HTML, and another is a parser. We are currently using html.parser, but there are other parsers as well, like lxml or html5lib. All of them have their own pros and cons. Some have better leniency, while some are very fast. The selection of the parser entirely depends on the user's choice. Below is the list of parsers with their pros and cons that you can checkout.
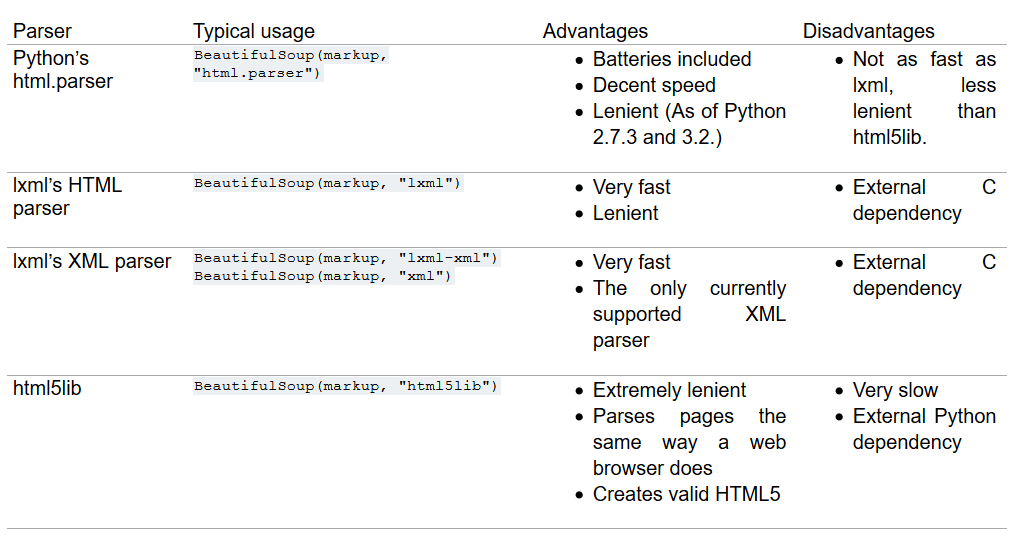
Fig. 2 List of Parsers | Image by crummy
HTML Tree Traversal
In this section, we will understand the tree structure of HTML and then extract the title, different tags, classes, lists, etc., from the parsed content using Beautiful Soup.
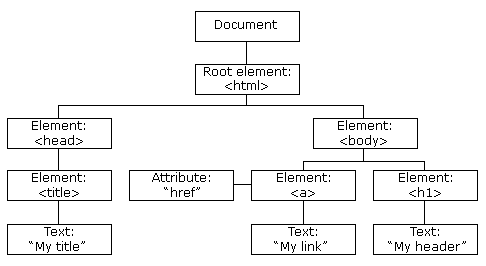
Fig. 3 HTML Tree Structure | Image by w3schools
The HTML tree represents a hierarchical information view. The root node is the <html> tag, which can have parents, children and siblings. The head tag and body tag follow the HTML tag. The head tag contains the metadata and the title, and the body tag contains the divs, paragraphs, heading, etc.
When an HTML document is passed through Beautiful Soup, it converts the complex HTML content into four major Python objects; these are
- BeautifulSoup:
It represents the parsed document as a whole. It is the complete document that we are trying to scrap.
soup = BeautifulSoup("<h1> Welcome to KDnuggets! </h1>", "html.parser")
print(type(soup))
Output:
<class 'bs4.BeautifulSoup'>
You can see the entire html content is an object of type Beautiful Soup.
- Tag:
The tag object corresponds to a particular tag in the HTML document. It can extract a tag from the whole document and return the first found tag if multiple tags with the same name are present in the DOM.
soup = BeautifulSoup("<h1> Welcome to KDnuggets! </h1>", 'html.parser')
print(type(soup.h1))
Output:
<class 'bs4.element.Tag'>
- NavigableString:
It contains the text inside a tag in string format. Beautiful Soup uses the NavigableString object to store the texts of a tag.
soup = BeautifulSoup("<h1> Welcome to KDnuggets! </h1>", "html.parser")
print(soup.h1.string)
print(type(soup.h1.string))
Output:
Welcome to KDnuggets!
<class 'bs4.element.NavigableString'>
- Comments:
It reads the HTML comments that are present inside a tag. It is a special type of NavigableString.
soup = BeautifulSoup("<h1><!-- This is a comment --></h1>", "html.parser")
print(soup.h1.string)
print(type(soup.h1.string))
Output:
This is a comment
<class 'bs4.element.Comment'>
Now, we will extract the title, different tags, classes, lists, etc., from the parsed HTML content.
1. Title
Getting the title of the HTML page.
print(parsedData.title)
Output:
<title>Data Science, Machine Learning, AI & Analytics - KDnuggets</title>
Or, you can also print the title string only.
print(parsedData.title.string)
Output:
Data Science, Machine Learning, AI & Analytics - KDnuggets
2. Find and Find All
These functions are useful when you want to search for a specific tag in the HTML content. Find() will give only the first occurrence of that tag, while find_all() will give all the occurrences of that tag. You can also iterate through them. Let’s see this with an example below.
find():
h2 = parsedData.find('h2')
print(h2)
Output:
<h2>Latest Posts</h2>
find_all():
H2s = parsedData.find_all("h2")
for h2 in H2s:
print(h2)
Output:
<h2>Latest Posts</h2>
<h2>From Our Partners</h2>
<h2>Top Posts Past 30 Days</h2>
<h2>More Recent Posts</h2>
<h2 size="+1">Top Posts Last Week</h2>
This will return the complete tag, but if you want to print only the string, you can write like that.
h2 = parsedData.find('h2').text
print(h2)
We can also get the class, id, type, href, etc., of a particular tag. For example, getting the links of all the anchor tags present.
anchors = parsedData.find_all("a")
for a in anchors:
print(a["href"])
Output:
Image by Author
You can also get the class of every div.
divs = parsedData.find_all("div")
for div in divs:
print(div["class"])
3. Finding Elements using Id and Class Name
We can also find specific elements by giving a particular id or a class name.
tags = parsedData.find_all("li", class_="li-has-thumb")
for tag in tags:
print(tag.text)
This will print the text of all the lis which belong to the li-has-thumb class. But writing the tag name is not always necessary if you are unsure about it. You can also write like this.
tags = parsedData.find_all(class_="li-has-thumb")
print(tags)
It will fetch all the tags with this class name.
Now, we will discuss some more interesting methods of Beautiful Soup
Some more Methods of Beautiful Soup
In this section, we will discuss some more functions of Beautiful Soup that will make your work easier and faster.
-
select()
The select() function allows us to find specific tags based on CSS selectors. CSS selectors are patterns that select certain HTML tags based on their class, id, attribute, etc.
Below is the example to find the image with the alt attribute starting withKDnuggets.
data = parsedData.select("img[alt*=KDnuggets]")
print(data)
Output:

-
parent
This attribute returns the parent of a given tag.
tag = parsedData.find('p')
print(tag.parent)
contents
This attribute returns the contents of the selected tag.
tag = parsedData.find('p')
print(tag.contents)
-
attrs
This attribute is used to get the attributes of a tag in a dictionary.
tag = parsedData.find('a')
print(tag.attrs)
-
has_attr()
This method checks if a tag has a particular attribute.
tag = parsedData.find('a')
print(tag.has_attr('href'))
It will return True if the attribute is present, otherwise returns False.
-
find_next()
This method finds the next tag after a given tag. It takes the name of the input tag that it needs to find next.
first_anchor = parsedData.find("a")
second_anchor = first_anchor.find_next("a")
print(second_anchor)
-
find_previous()
This method is used to find the previous tag after a given tag. It takes the name of the input tag that it needs to find next.
second_anchor = parsedData.find_all('a')[1]
first_anchor = second_anchor.find_previous('a')
print(first_anchor)
It will print the first anchor tag again.
There are many other methods that you can give a try. These methods are available in this documentation of the Beautiful Soup.
Conclusion
We have discussed web scraping, its uses, and its Python and Beautiful Soup implementation. It is all for today. Feel free to comment below if you have any comments or suggestions.
Aryan Garg is a B.Tech. Electrical Engineering student, currently in the final year of his undergrad. His interest lies in the field of Web Development and Machine Learning. He have pursued this interest and am eager to work more in these directions.