Bark: The Ultimate Audio Generation Model
Bark is a versatile audio generation model that supports multi-language, music, voice cloning, and speaker prompts audio generation.

Image by Author | Canva Pro | Bing Image Creator
We are witnessing swift progress in text-to-speech models, which are increasingly exhibiting remarkable improvements in achieving a more natural-sounding output. The advancements in this field are not limited to speech generation alone; rather significant strides are being made in the development of music and ambient sound generators and speech cloning, which are rapidly evolving.
In this post, we are going to learn about Bark, the ultimate audio generation model capable of producing various spoken languages, ambient sounds, music, and multi-speaker prompts. We will delve into its functionalities and key features and get a starting guide.
What is Bark?
Bark, developed by Suno, is a transformer-based text-to-audio model that excels in generating highly realistic, multilingual speech, music, background noise, and even simple sound effects. Additionally, the model can produce various nonverbal communications, such as laughter, sighs, and cries. You can access pre-trained model checkpoints that are ready for inference.
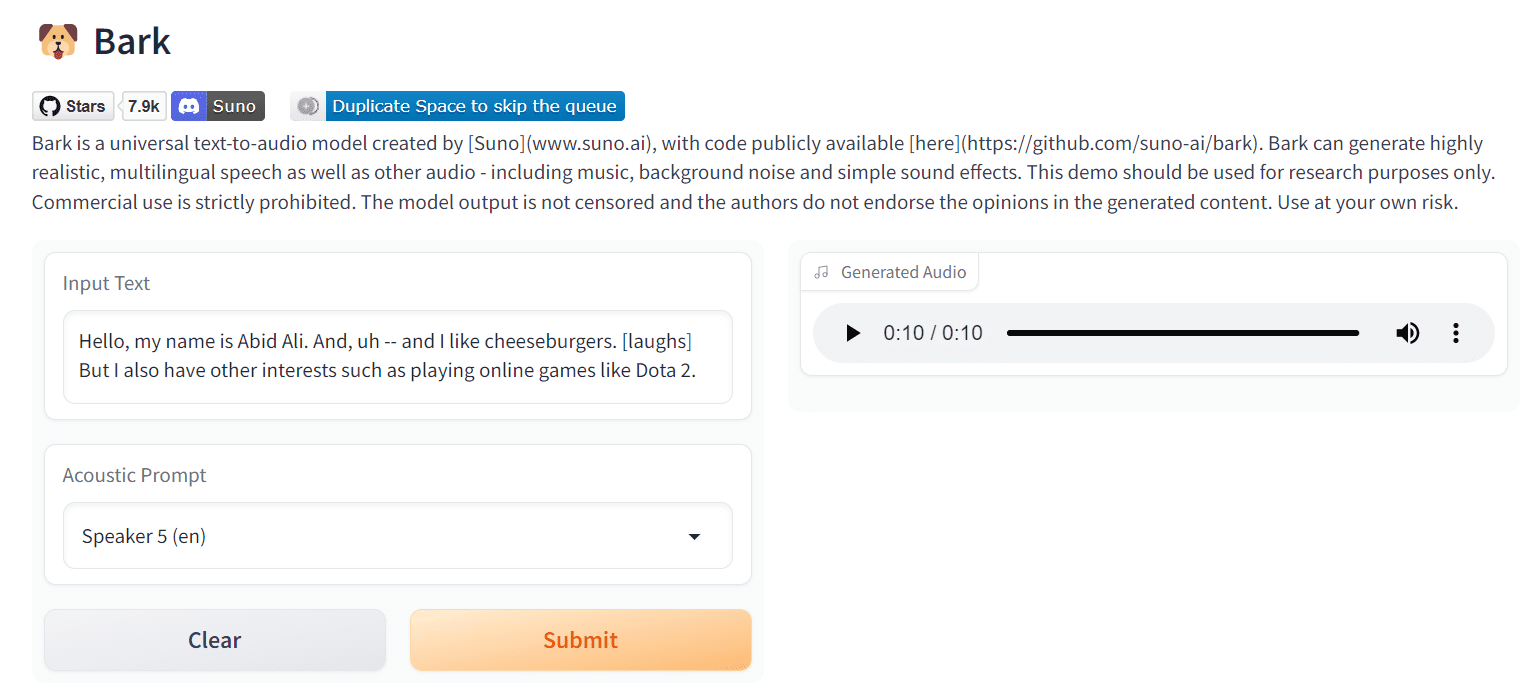
Image from Bark by suno
How Bark Works?
Bark, like Vall-E and other impressive works in the field, employs GPT-style models for generating audio from scratch. However, unlike Vall-E, Bark uses high-level semantic tokens to embed the initial text prompt, without relying on phonemes. It allows Bark to generalize to a wide range of arbitrary instructions beyond speech, including music lyrics, sound effects, and non-speech sounds present in the training data.
The generated semantic tokens are then processed by a second model to convert them into audio codec tokens, producing the complete waveform. To make Bark accessible to the community via public code, we integrated the remarkable EnCodec codec from Facebook as an audio representation.
Bark has used nanoGPT for blazing fast implementation of GPT-style models, EnCodec for the implementation of a fantastic audio codec, AudioLM for training and inference code, and Vall-E, AudioLM, and similar papers for the development of Bark project.
Bark Features
Multi Language
Bark supports various languages out-of-the-box, and it can automatically detect the language of the input text. Even when the text contains a mixture of different languages, known as code-switching, Bark can accurately identify and apply the native accent for each language in the same voice.
Try the prompt:
Hallo, wie geht es dir?. ¿Qué haces aquí? Are you looking for someone?
Non-Speech Sounds
Bark can add non-speech sounds such as laughter, gasps, and a clear throat.
Just add tags or change the text to make it sound natural.
- [laughs]
- [sighs]
- [music]
- [gasps]
- [clears throat]
- … for hesitations
- ♪ for song lyrics
- capitalization for emphasis of a word
- MAN/WOMAN: for bias towards speaker
Try the prompt:
" [clears throat] Hello, my name is Abid. And, uh -- and I like cheeseburgers. [laughs] But I also have other interests such as [music]... ♪ singing ♪."
Music
Bark can generate all types of audio, and it does not differentiate between speech and music. While Bark may sometimes generate text as music, you can enhance its performance by adding music notes around your lyrics to help it distinguish between the two.
Try the prompt:
♪ Almost heaven, West Virginia. Blue Ridge Mountains, Shenandoah River. Life is old there, older than the trees. Younger than the mountains, growin' like a breeze ♪
Voice Cloning
Bark can fully clone voices. It can accurately replicate a speaker's tone, pitch, emotion, and prosody while also preserving other audio features, such as music and ambient noise. However, to prevent the misuse of this advanced technology, they have implemented limitations. Users are only allowed to choose from a select set of fully synthetic options provided by Suno.
Speaker Prompts
While you can provide specific speaker prompts such as "NARRATOR," "MAN," "WOMAN," and so on, it's important to note that these prompts may not always be respected, particularly if there is a conflicting audio history prompt present.
Try the prompt:
MAN: Can you buy me the coffee from starbucks?
WOMAN: Sure, what type of coffee do you want?
Getting Started
You can start experimenting by testing out the demo on Bark by suno or run your own inference by using Google Colab Notebook.
If you want to run it locally, you have to install the bark package by using the command below in the terminal.
pip install git+https://github.com/suno-ai/bark.git
After that, run the code below in the Jupyter Notebook. The code will download all the models and then convert a text prompt into audio.
from bark import SAMPLE_RATE, generate_audio, preload_models
from IPython.display import Audio
# download and load all models
preload_models()
# generate audio from text
text_prompt = """
Hello, my name is Abid Ali. And, uh -- and I like cheeseburgers. [laughs]
But I also have other interests such as playing online games like Dota 2.
"""
audio_array = generate_audio(text_prompt)
# play text in notebook
Audio(audio_array, rate=SAMPLE_RATE)
You can save the audio in wav format by using <code>scipy.io.wavfile</code>.
from scipy.io.wavfile import write as write_wav
write_wav("/project/sample_audio.wav", SAMPLE_RATE, audio_array)
Check out other resources and learn to integrate Bark into your application.
Resources:
- GitHub: suno-ai/bark
- Spaces Demo: Bark by suno
- Colab Notebook: Bark Google Colab Demo
- Model Card: Bark
- License: CC-BY 4.0 NC. The Suno models themselves may be used commercially
- Suno Studio (Early Access): Suno Studio(typeform.com)
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.