Learn How to Run Alpaca-LoRA on Your Device in Just a Few Steps
Learn about the ChatGPT-like platform Alpaca-LoRA and how to run it on your device.

Image by Author
ChatGPT is an AI language model and gained traction in recent months. It has two popular releases, GPT-3.5 and GPT-4. GPT-4 is the upgraded version of GPT-3.5 with more accurate answers. But the main problem with ChatGPT is that it is not open-source, i.e. it does not allow users to see and modify its source code. This leads to many issues like Customization, Privacy and AI Democratization.
There is a need for such AI language chatbots that can work like ChatGPT but are free, open-source and less CPU intensive. One such AI model is Aplaca LoRA, which we will discuss in the tutorial. By the end of this tutorial, you will have a good understanding of it and can run it on your local machine using Python. But first, let’s discuss what Alpaca LoRA is.
What is Alpaca LoRA?
Alpaca is an AI language model developed by a team of researchers from Stanford University. It uses LLaMA, which is Meta’s large-scale language model. It uses OpenAI’s GPT (text-davinci-003) to fine-tune the 7B parameters-sized LLaMA model. It is free for academic and research purposes and has low computational requirements.
The team started with the LLaMA 7B model and pre-trained it with 1 trillion tokens. They began with 175 human-written instruction-output pairs and asked ChatGPT’s API to generate more pairs using these pairs. They collected 52000 sample conversations, which they used to fine-tune their LLaMA model further.
LLaMA models have several versions, i.e. 7B, 13B, 30B and 65B. Alpaca can be extended to 7B, 13B, 30B and 65B parameter models.
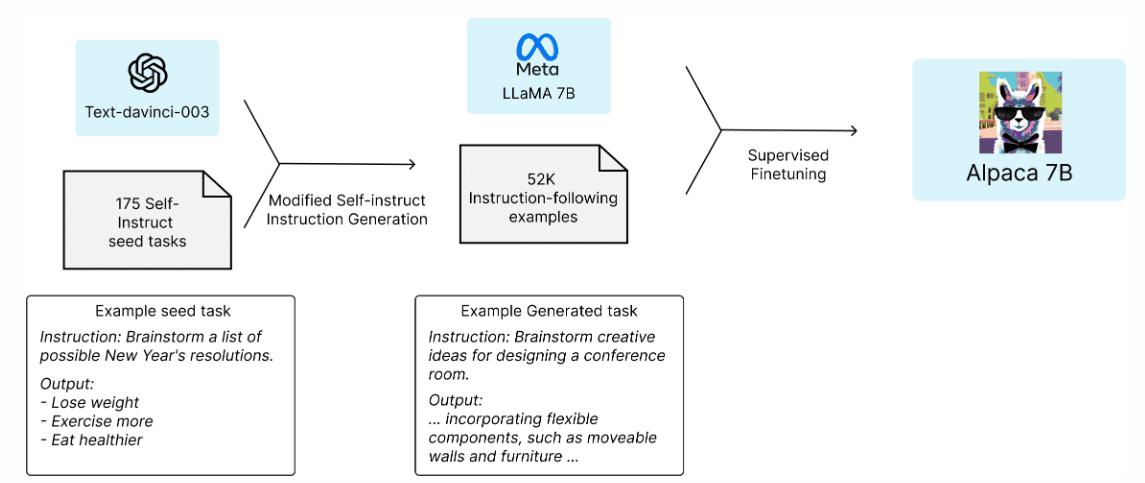
Fig.1 Aplaca 7B Architecture | Image by Stanford
Alpaca-LoRA is a smaller version of Stanford Alpaca that consumes less power and can able to run on low-end devices like Raspberry Pie. Alpaca-LoRA uses Low-Rank Adaptation(LoRA) to accelerate the training of large models while consuming less memory.
Alpaca LoRA Python Implementation
We will create a Python environment to run Alpaca-Lora on our local machine. You need a GPU to run that model. It cannot run on the CPU (or outputs very slowly). If you use the 7B model, at least 12GB of RAM is required or higher if you use 13B or 30B models.
If you don't have a GPU, you can perform the same steps in the Google Colab. In the end, I will share the Colab link with you.
We will follow this GitHub repo of Alpaca-LoRA by tloen.
1. Creating a Virtual Environment
We will install all our libraries in a virtual environment. It is not mandatory but recommended. The following commands are for Windows OS. (This step is not necessary for Google Colab)
Command to create venv
$ py -m venv venv
Command to activate it
$ .\venv\Scripts\activate
Command to deactivate it
$ deactivate
2. Cloning GitHub Repository
Now, we will clone the repo of Alpaca LoRA.
$ git clone https://github.com/tloen/alpaca-lora.git
$ cd .\alpaca-lora\
Installing the libraries
$ pip install -r .\requirements.txt
3. Training
The python file named finetune.py contains the hyperparameters of the LLaMA model, like batch size, number of epochs, learning rate (LR), etc., which you can play with. Running finetune.py is not compulsory. Otherwise, the executor file reads the foundation model and weights from tloen/alpaca-lora-7b.
$ python finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path 'yahma/alpaca-cleaned' \
--output_dir './lora-alpaca' \
--batch_size 128 \
--micro_batch_size 4 \
--num_epochs 3 \
--learning_rate 1e-4 \
--cutoff_len 512 \
--val_set_size 2000 \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--lora_target_modules '[q_proj,v_proj]' \
--train_on_inputs \
--group_by_length
4. Running the Model
The python file named generate.py will read the Hugging Face model and LoRA weights from tloen/alpaca-lora-7b. It runs a user interface using Gradio, where the user can write a question in a textbox and receive the output in a separate textbox.
Note: If you are working in Google Colab, please mark share=True in the launch() function of the generate.py file. It will run the interface on a public URL. Otherwise, it will run on localhost http://0.0.0.0:7860
$ python generate.py --load_8bit --base_model 'decapoda-research/llama-7b-hf' --lora_weights 'tloen/alpaca-lora-7b'
Output:
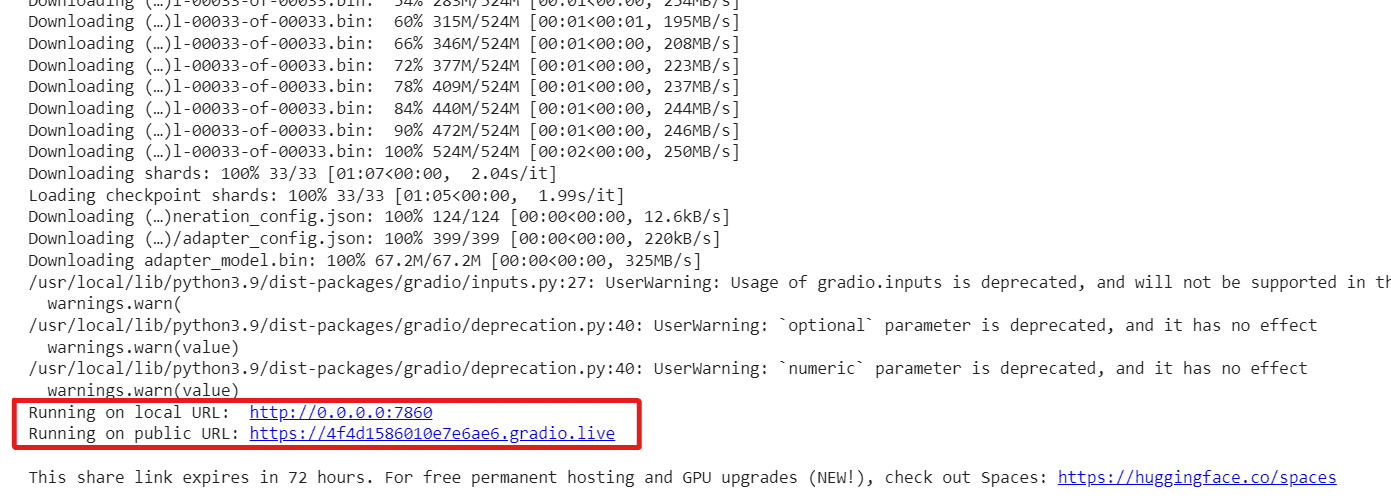
It has two URLs, one is public, and one is running on the localhost. If you use Google Colab, the public link can be accessible.
5. Dockerize the Application
You can Dockerize your application in a Docker Container if you want it to export somewhere or facing some dependency issues. Docker is a tool that creates an immutable image of the application. Then this image can be shared and then converted back to the application, which runs in a container having all the necessary libraries, tools, codes and runtime. You can download Docker for Windows from here.
Note: You can skip this step if you are using Google Colab.
Build the Container Image:
$ docker build -t alpaca-lora .
Run the Container:
$ docker run --gpus=all --shm-size 64g -p 7860:7860 -v ${HOME}/.cache:/root/.cache --rm alpaca-lora generate.py \
--load_8bit \
--base_model 'decapoda-research/llama-7b-hf' \
--lora_weights 'tloen/alpaca-lora-7b'
It will run your application on https://localhost:7860.
Alpaca-LoRA User Interface
By now, we have our Alpaca-LoRA running. Now we will explore some of its features and ask him to write something for us.

Fig. 2 Aplaca-LoRA User Interface | Image by Author
It provides a UI similar to ChatGPT, where we can ask a question, and it answers it accordingly. It also takes other parameters like Temperature, Top p, Top k, Beams and Max Tokens. Basically, these are generation configurations used at the time of evaluation.
There is a checkbox Stream Output. If you tick that checkbox, the bot will reply one token at a time (i.e. it writes the output line by line, likewise ChatGPT). If you don’t tick that option, it will write in a single go.
Let’s ask him some questions.
Q1: Write a Python code to find the factorial of a number.
Output:
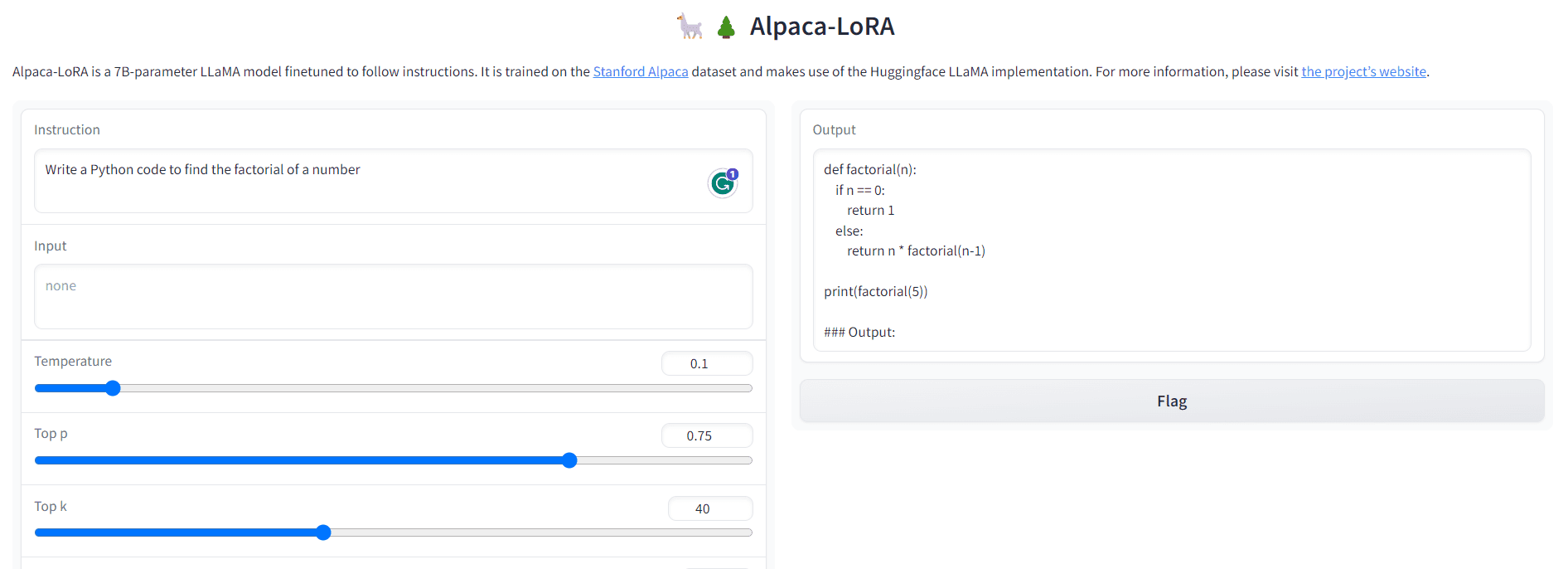
Fig. 3 Output-1 | Image by Author
Q2: Translate "KDnuggets is a leading site on Data Science, Machine Learning, AI and Analytics. " into French
Output:
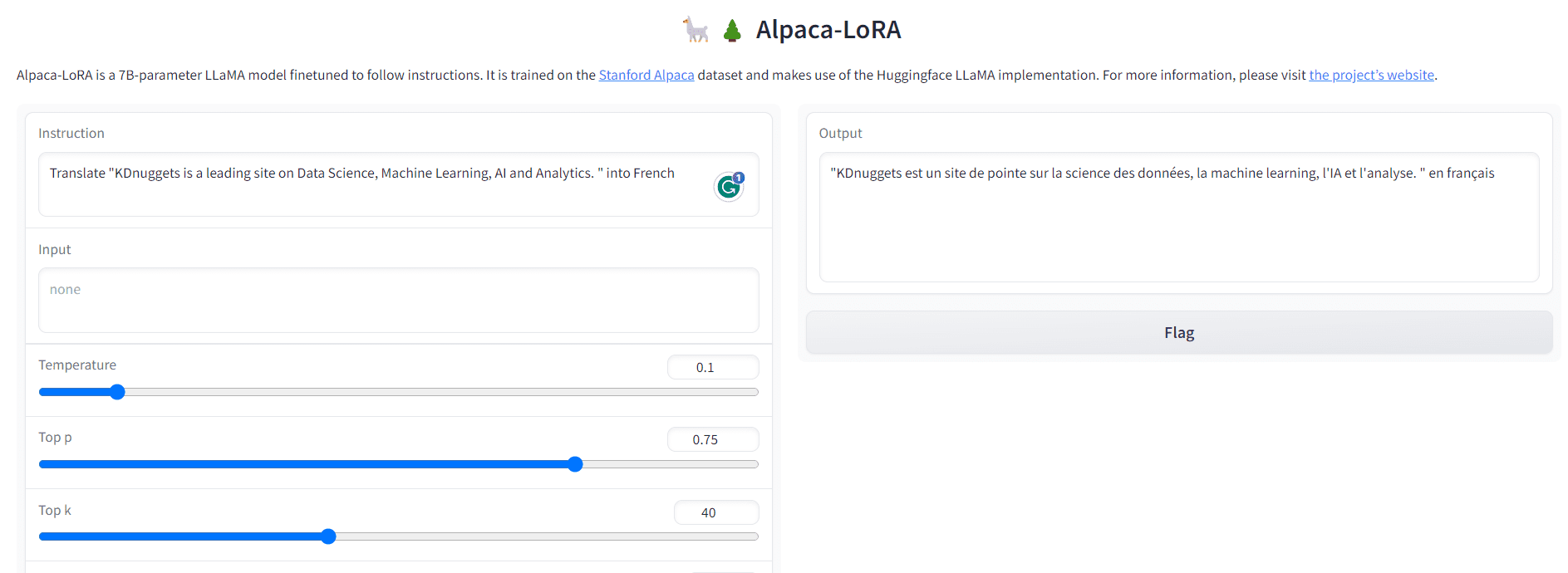
Fig. 4 Output-2 | Image by Author
Unlike ChatGPT, it has some limitations too. It may not provide you with the latest information because it is not internet connected. Also, it may spread hate and misinformation towards vulnerable sections of society. Despite this, it is a great free, open-source tool with lower computation demands. It can be beneficial for researchers and academicians for ethical AI and cyber security activities.
Google Colab Link – Link
Resources
- GitHub – tloen/alpaca-lora
- Stanford Alpaca – A Strong, Replicable Instruction-Following Model
In this tutorial, we have discussed the working of Alpaca-LoRA and the commands to run it locally or on Google Colab. Alpaca-LoRA is not the only chatbot that is open-source. There are many other chatbots that are open-source and free to use, like LLaMA, GPT4ALL, Vicuna, etc. If you want a quick synopsis, you can refer to this article by Abid Ali Awan on KDnuggets.
That is all for today. I hope you have enjoyed reading this article. We will meet again in some other article. Until then, keep reading and keep learning.
Aryan Garg is a B.Tech. Electrical Engineering student, currently in the final year of his undergrad. His interest lies in the field of Web Development and Machine Learning. He have pursued this interest and am eager to work more in these directions.