Ensuring Reliable Few-Shot Prompt Selection for LLMs
Data-centric techniques for better Few-Shot Prompting when applying LLMs to Noisy Real-World Data.
Authors: Chris Mauck, Jonas Mueller
In this article, we prompt the Davinci Large Language Model from OpenAI (the model underpinning GPT-3/ChatGPT) with few-shot prompts in an effort to classify the intent of customer service requests at a large bank. Following typical practice, we source the few-shot examples to include in the prompt template from an available dataset of human-labeled request examples. However, the resulting LLM predictions are unreliable — a close inspection reveals this is because real-world data is messy and error-prone. LLM performance in this customer service intent classification task is only marginally boosted by manually modifying the prompt template to mitigate potentially noisy data. The LLM predictions become significantly more accurate if we instead use data-centric AI algorithms like Confident Learning to ensure only high-quality few-shot examples are selected for inclusion in the prompt template.
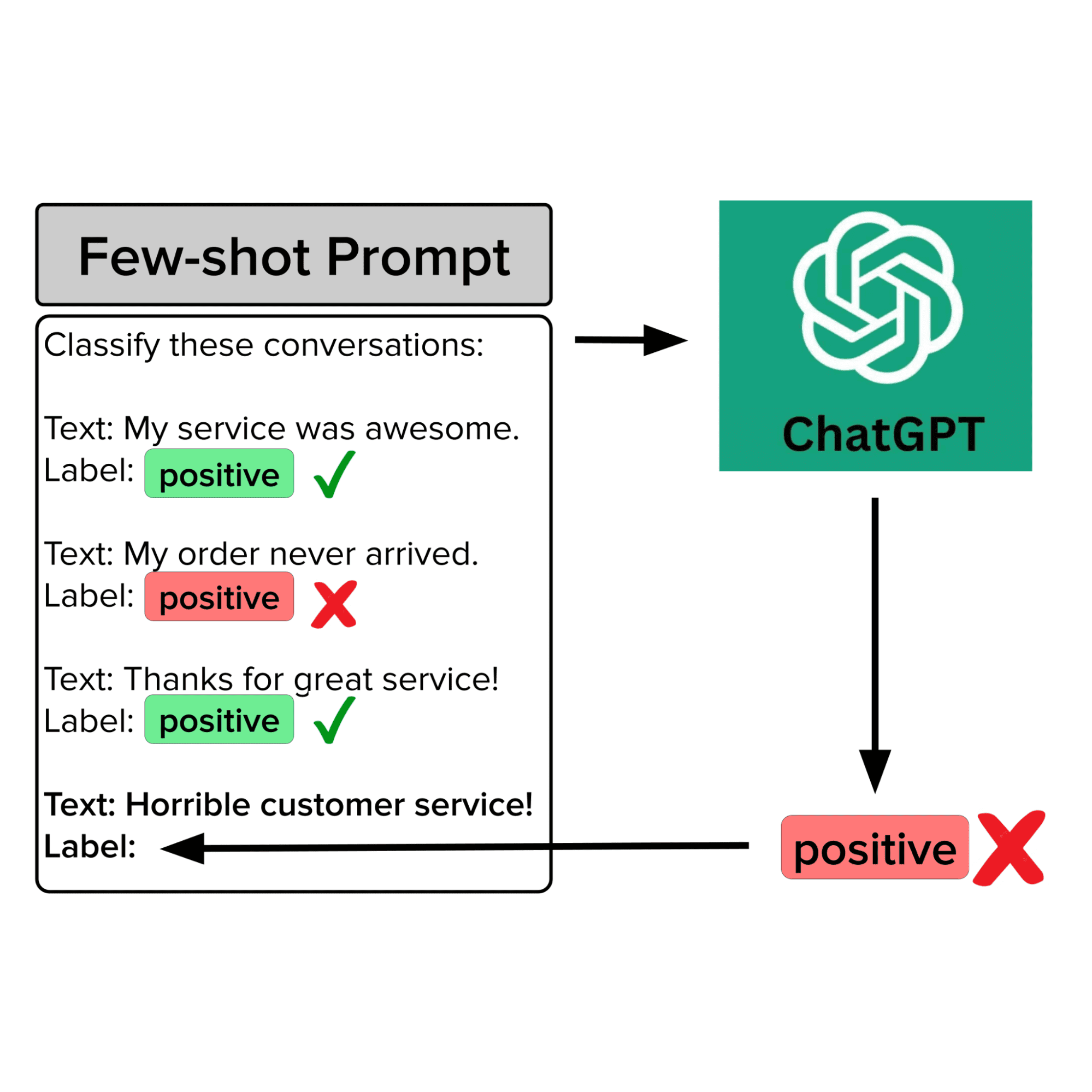
Let’s consider how we can curate high-quality few-shot examples for prompting LLMs to produce the most reliable predictions. The need to ensure high-quality examples in the few-shot prompt may seem obvious, but many engineers don’t know there are algorithms/software to help you do this more systematically (in fact an entire scientific discipline of Data-Centric AI). Such algorithmic data curation has many advantages, it is: fully automated, systematic, and broadly applicable to general LLM applications beyond intent classification.
Banking Intent Dataset
This article studies a 50-class variant of the Banking-77 Dataset which contains online banking queries annotated with their corresponding intents (the label shown below). We evaluate models that predict this label using a fixed test dataset containing ~500 phrases, and have a pool of ~1000 labeled phrases which we consider as candidates to include amongst our few-shot examples.

You can download the candidate pool of few-shot examples and test set here and here. Here’s a notebook you can run to reproduce the results shown in this article.
Few-shot Prompting
Few-shot prompting (also known as in-context learning) is a NLP technique that enables pretrained foundation models to perform complex tasks without any explicit training (i.e. updates to model parameters). In few-shot prompting, we provide a model with a limited number of input-output pairs, as part of a prompt template that is included in the prompt used to instruct the model how to handle a particular input. The additional context provided by the prompt template helps the model better infer what types of outputs are desired. For example, given the input: “Is San Francisco in California?”, a LLM will better know what type of output is desired if this prompt is augmented with a fixed template such that the new prompt looks something like:
Text: Is Boston in Massachusetts?
Label: Yes
Text: Is Denver in California?
Label: No
Text: Is San Fransisco in California?
Label:
Few-shot prompting is particularly useful in text classification scenarios where your classes are domain-specific (as is typically the case in customer service applications within different businesses).

In our case, we have a dataset with 50 possible classes (intents) to provide context for, such that OpenAI’s pretrained LLM can learn the difference between classes in context. Using LangChain, we select one random example from each of the 50 classes (from our pool of labeled candidate examples) and construct a 50-shot prompt template. We also append a string that lists the possible classes before the few-shot examples to ensure the LLM output is a valid class (i.e. intent category).
The above 50-shot prompt is used as input for the LLM to get it to classify each of the examples in the test set (target text above is the only part of this input that changes between different test examples). These predictions are compared against the ground truth labels to evaluate the LLM accuracy produced using a selected few-shot prompt template.
Baseline Model Performance
# This method handles:
# - collecting each of the test examples
# - formatting the prompt
# - querying the LLM API
# - parsing the output
def eval_prompt(examples_pool, test, prefix="", use_examples=True):
texts = test.text.values
responses = []
examples = get_examples(examples_pool, seed) if use_examples else []
for i in range(len(texts)):
text = texts[i]
prompt = get_prompt(examples_pool, text, examples, prefix)
resp = get_response(prompt)
responses.append(resp)
return responses
# Evaluate the 50-shot prompt shown above.
preds = eval_prompt(examples_pool, test)
evaluate_preds(preds, test)
>>> Model Accuracy: 59.6%
Running each of the test examples through the LLM with the 50-shot prompt shown above, we achieve an accuracy of 59.6% which not bad for a 50-class problem. But this is not quite satisfactory for our bank’s customer service application, so let’s take a closer look at the dataset (i.e. pool) of candidate examples. When ML performs poorly, the data is often to blame!
Issues in Our Data
Via close inspection of the candidate pool of examples from which our few-shot prompt was drawn, we find mislabeled phrases and outliers lurking in the data. Here are a few examples that were clearly annotated incorrectly.

Previous research has observed many popular datasets contain incorrectly labeled examples because data annotation teams are imperfect.
It is also common for customer service datasets to contain out-of-scope examples that were accidentally included. Here we see a few strange-looking examples that do not correspond to valid banking customer service requests.

Why Do These Issues Matter?
As the context size for LLMs grows, it is becoming common for prompts to include many examples. As such, it may not be possible to manually validate all of the examples in your few-shot prompt, especially with a large number of classes (or if you lack domain knowledge about them). If the data source of these few-shot examples contains issues like those shown above (as many real-world datasets do), then errant examples may find their way into your prompts. The rest of the article examines the impact of this problem and how we can mitigate it.
Can we warn the LLM the examples may be noisy?
What if we just include a “disclaimer warning” in the prompt telling the LLM that some labels in the provided few-shot examples may be incorrect? Here we consider the following modification to our prompt template, which still includes the same 50 few-shot examples as before.

prefix = 'Beware that some labels in the examples may be noisy and have been incorrectly specified.'
preds = eval_prompt(examples_pool, test, prefix=prefix)
evaluate_preds(preds, test)
>>> Model Accuracy: 62.0%
Using the above prompt, we achieve an accuracy of 62%. Marginally better, but still not good enough to use the LLM for intent classification in our bank’s customer service system!
Can we remove the noisy examples entirely?
Since we can’t trust the labels in the few-shot examples pool, what if we just remove them entirely from the prompt and only rely on the powerful LLM? Rather than few-shot prompting, we are doing zero-shot prompting in which the only example included in the prompt is the one the LLM is supposed to classify. Zero-shot prompting entirely relies on the LLM’s pretrained knowledge to get the correct outputs.

preds = eval_prompt(examples_pool, test, use_examples=False)
evaluate_preds(preds, test)
>>> Model Accuracy: 67.4%
After removing the poor-quality few-shot examples entirely, we achieve an accuracy of 67.4% which is the best that we’ve done so far!
t seems that noisy few-shot examples can actually harm model performance instead of boosting it as they are supposed to do.
Can we identify and correct the noisy examples?
Instead of modifying the prompt or removing the examples entirely, the smarter (yet more complex) way to improve our dataset would be to find and fix the label issues by hand. This simultaneously removes a noisy data point that is harming the model and adds an accurate one that should improve its performance via few-shot prompting, but making such corrections manually is cumbersome. Here we instead effortlessly correct the data using Cleanlab Studio, a platform that implements Confident Learning algorithms to automatically find and fix label issues.
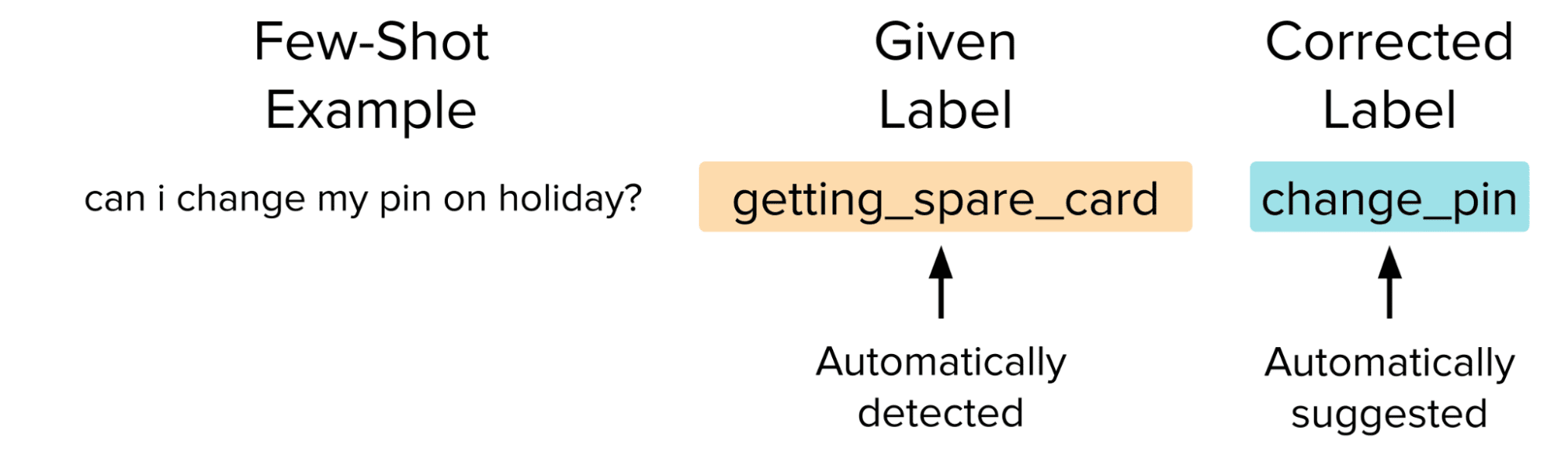
After replacing the estimated bad labels with ones estimated to be more suitable via Confident Learning, we re-run the original 50-shot prompt through the LLM with each test example, except this time we use the auto-corrected label which ensures we provide the LLM with 50 high-quality examples in its few-shot prompt.
# Source examples with the corrected labels.
clean_pool = pd.read_csv("studio_examples_pool.csv")
clean_examples = get_examples(clean_pool)
# Evaluate the original 50-shot prompt using high-quality examples.
preds = eval_prompt(clean_examples, test)
evaluate_preds(preds, test)
>>> Model Accuracy: 72.0%
After doing this, we achieve an accuracy of 72% which is quite impressive for the 50-class problem.
We’ve now shown that noisy few-shot examples can considerably decrease LLM performance and that it is suboptimal to just manually change the prompt (via adding caveats or removing examples). To achieve the highest performance, you should also try correcting your examples using Data-centric AI techniques like Confident Learning.
Importance of Data-centric AI
This article highlights the significance of ensuring reliable few-shot prompt selection for language models, specifically focusing on customer service intent classification in the banking domain. Through the exploration of a large bank's customer service request dataset and the application of few-shot prompting techniques using the Davinci LLM, we encountered challenges stemming from noisy and erroneous few-shot examples. We demonstrated that modifying the prompt or removing examples alone cannot guarantee optimal model performance. Instead, data-centric AI algorithms like Confident Learning implemented in tools like Cleanlab Studio proved to be more effective in identifying and rectifying label issues, resulting in significantly improved accuracy. This study emphasizes the role of algorithmic data curation in obtaining reliable few-shot prompts, and highlights the utility of such techniques in enhancing Language Model performance across various domains.
Chris Mauck is Data Scientist at Cleanlab.