Detecting Data Drift for Ensuring Production ML Model Quality Using Eurybia
This article will focus on a step-by-step data drift study using Eurybia an open-source python library
In the rest of this article, we will focus on a step-by-step data drift study using Eurybia an open-source python library. Detecting data drift is an important step to ensure the quality of machine learning models in production. This detection strongly favors robust AI maintainability over time.
Eurybia demo, image by Author
What is Data Drift and Why Should You Care?
Machine learning models are usually trained on data from historical databases. Models are then deployed in a production environment. Predictions from the production environment are made on freshly available data.
As such, historical data used to train the model and data used to predict the results might differ. This difference between datasets is named data drift.
Production ML models sometimes face performance drop over time. This decrease can be attributed either (or both) to the operational use or to the data drift.
How to Detect Data Drift?
To detect data drift, several methods such as comparing the distributions of the dataset features using statistical tests are available.
The python library Eurybia uses a method consisting in training a binary classification model (named “datadrift classifier”). This model tries to predict whether a sample belongs to the training/baseline dataset or to the production/current dataset.
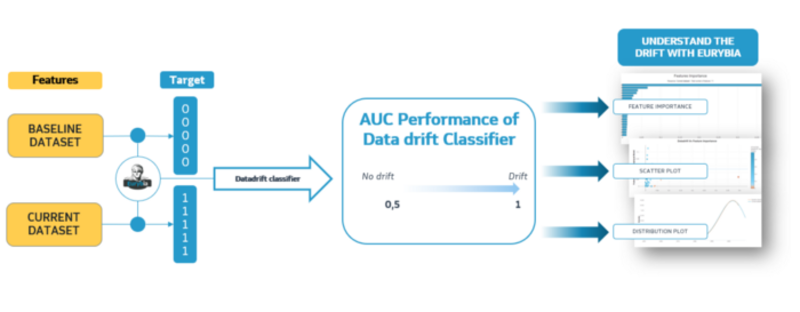
How the datadrift classifier works, image by Author
It is then possible to study the explainability of the created “datadrift classifier”. This is a great advantage since the explainability provides a detailed analysis of what drifted along with a strong rationale for further study and understanding of the data drift. In addition to explainability, the performance of the “datadrift classifier” provides a measure of the data drift.
Data Drift: What Are We Looking For?
What feature changed the most ?
Feature importance of each feature included in the “datadrift classifier” can be extracted. It allows to prioritize the study of features that changed the most.
Does the data drift affect the model predictions ?
Eurybia puts into perspective the data drift along with the feature importance of the deployed model. The more important a feature is for the deployed model, the more problematic the drift of the feature is.
What is the variation of each feature?
It is possible to observe the feature distribution of each feature in both baseline and current datasets.
What is the impact of data drift?
Eurybia plots the predicted probabilities distributions based on the baseline dataset and the production dataset. We can measure the difference between this distibution with the Jensen Shannon Divergence.
Can we measure the data drift?
Eurybia provides performance metrics (AUC of the “datadrift classifier” and Jensen Shannon Divergence of the predicted probabilities distributions) for data drift, which notably allows tracking over time.
Demonstration of Data Drift Detection with Eurybia
You can install the package through pip:
$pip install eurybia
Let’s Use Eurybia!
In the rest of this article, we will focus on a step-by-step data drift study using Eurybia.
We will use the famous “House Prices” dataset from Kaggle. Data will be split into two distinct datasets. Data from 2006 will be used to train a regressor able to predict the selling price of a house. Then, the price of houses sold in 2007 will be predicted using the previously created model.
We will then try to detect the drift of this regressor, based on the data drift of 2006 vs. 2007 datasets.
Let’s start by loading the dataset:
Building supervised model:
And use Eurybia to detect data drift…
Step 1 — Import
Step 2 — Initialise a SmartDrift Object
Optional parameters:
- “deployed_model”: Indicate here the model used to provide predictions. This parameter allows combining of data drift results with the prediction model. It thus provides hints about the potential impact of data drift on the deployed model performances.
- “Encoding”: If a specific encoder has been used to prepare the dataset to provide the “deployed_model” with modified data, it should be indicated here. Eurybia will then be able to integrate it and get back to the original data format.
Step 3 — Compile
Optional parameters:
- “full_validation”: False/True (default: False). The full validation consists in analyzing the modalities consistency between columns.
- “date_compile_auc ”: date to specify a date to be indicated when saving the results. This might be useful when computing the drift for a past data set.
- “datadrift_file”: Name of the CSV file containing the data drift performance history. This parameter is useful when the drift is evaluated over time.
Step 4 — Generate Html Report
Optional parameters:
- “title_description ”: short subtitle to describe the report.
- “project_info_file”: path to yaml file. The file could contain multiple informations to be added to the report such as general information, dataset description, data preparation, or model training.
How to Understand Eurybia’s Outputs
Eurybia is designed to generate an HTML report for analysis. All the plots provided in the HTML report are also available in Jupyter notebooks.
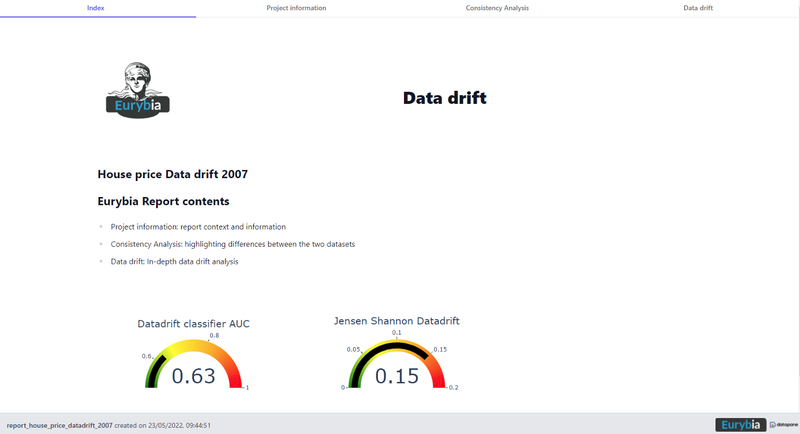
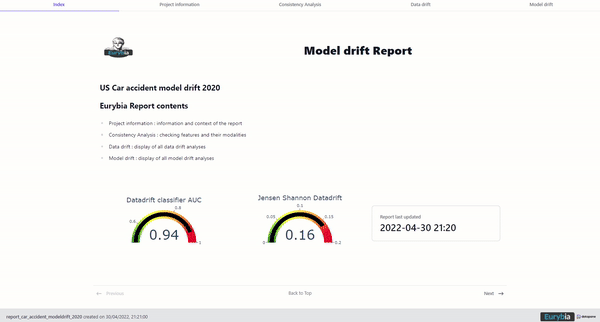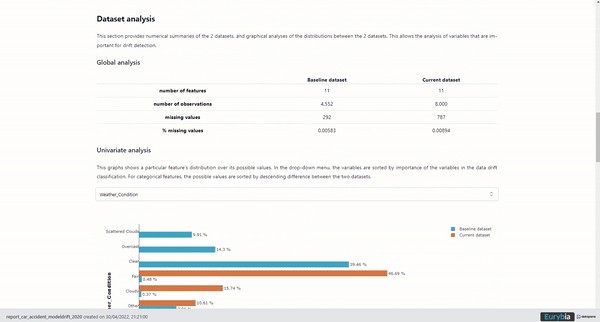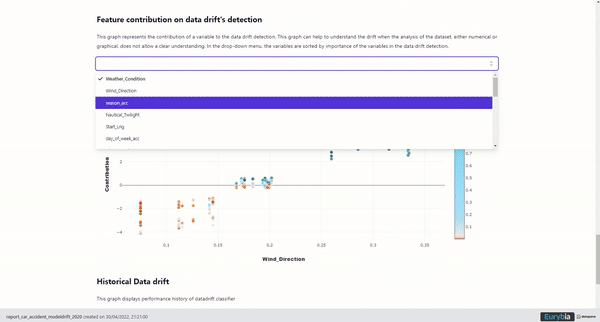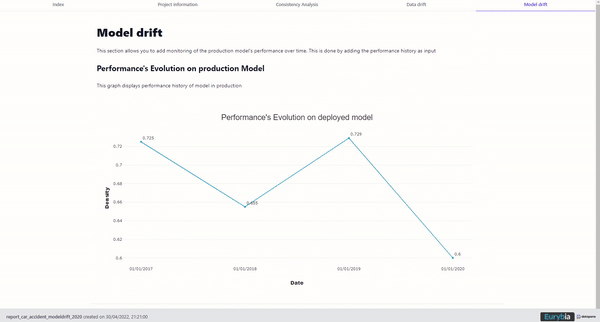
Eurybia Report index, image by Author
The report can be browsed with tabs and is separated as follows:
- Index: home page
- Project information: report context and information
- Consistency Analysis: highlighting differences between the two datasets
- Data drift: In-depth data drift analysis
Datadrift classifier model performances
The data drift detection method is based on the ability of a model classifier to identify whether a sample belongs to one or another dataset. For this purpose, a target (0) is assigned to the baseline dataset and a second target (1) to the current dataset. A classification model (catboost) is trained to predict this target. As such, the data drift classifier performance is related to the difference between two datasets. A marked difference will lead to an easy classification (final AUC close to 1). Similar datasets will lead to poor data drift classifier performance (final AUC close to 0.5).
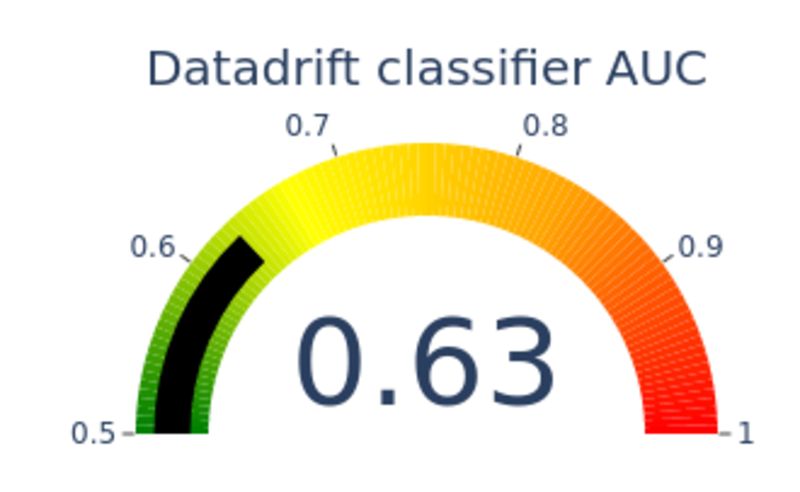
Datadrift classifier model performance, image by Author
The closer the AUC is from 0.5 the less the data drifted. The closer the AUC is from 1 the more the data drifted
Importance of features in data drift
Bar chart representing the feature importance of each variable included in the “datadrift classifier”.

Importance of features in data drift, image by Author
This graph highlights variables that drifted the most. This might help to prioritize the subsequent deeper study of specific variables.
Feature importance overview
Eurybia HTML reports also contain a scatter plot depicting, for each feature, the feature importance of the deployed model as a function of the “datadrift classifier” feature importance. This highlights the real importance of a data drift for the deployed model classification.
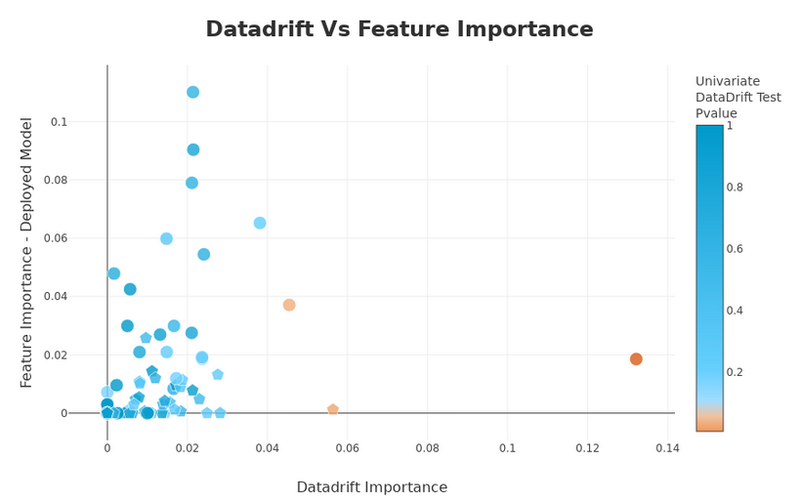
Feature importance overview, image by Author
Graphical interpretation based on the feature location:
- Top left: Feature important to the deployed model and with low data drift
- Bottom left: Feature with moderated importance to the deployed model and with low data drift
- Bottom right: Feature with moderated importance to the deployed model but with high data drift. This feature might need your attention.
- Top right: Feature important to the deployed model and high drift. This feature requires your attention.
Univariate analysis
The univariate analysis is supported by the graphical analysis of the 2 datasets’ distributions, making easier the study of the most important feature for drift detection.
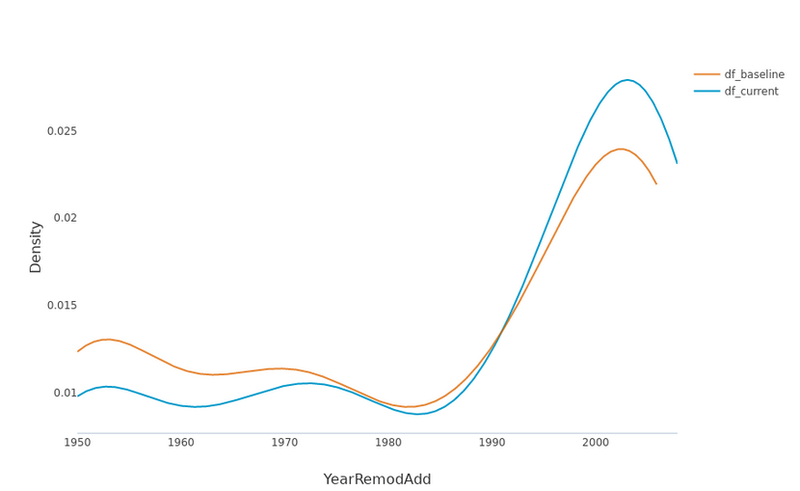
Univariate analysis, image by Author
With the Eurybia report, in the drop-down menu, the features are sorted by their importance in the data drift classification. For categorical features, the possible values are sorted by descending difference between the two datasets.
Distribution of predicted values
The distribution of predicted values helps the visualization of output predictions provided by the deployed model on both baseline and current datasets. A difference in distributions might reflect a data drift.

Distribution of predicted values, image by Author
Jensen Shannon Divergence (JSD). The JSD measures the effect of a data drift on the deployed model performance. A value close to 0 indicates similar data distributions, while a value close to 1 tends to show distinct data distributions with a negative effect on the deployed model performance.
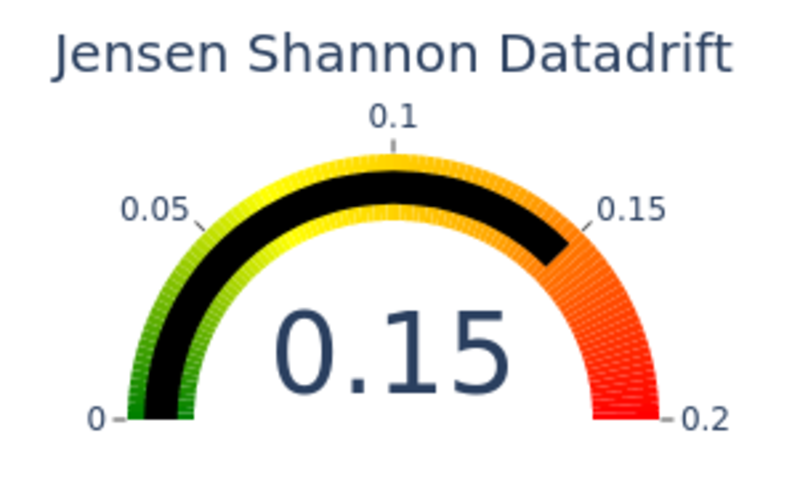
Jensen Shannon Divergence, image by Author
Historical Data drift
Eurybia can compile the data drift over the years with sales up to 2010.
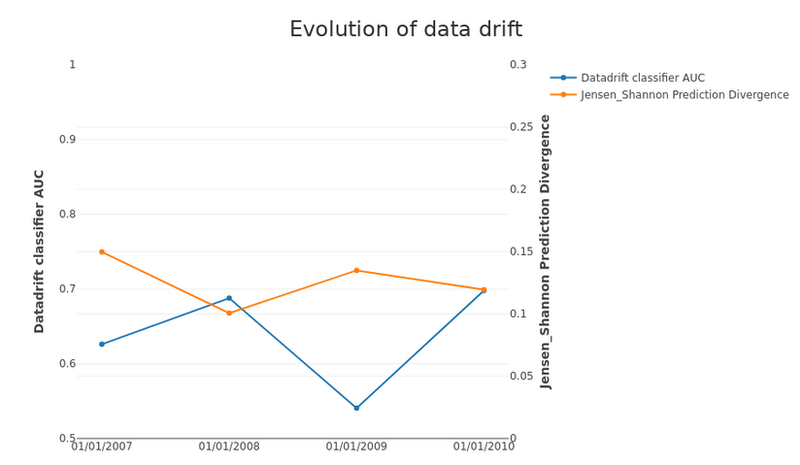
Historical Data drift, image by Author
The “Datadrift classifier AUC” and “Jensen Shannon Datadrift” provide 2 helpful indicators of data drift.
While AUC striclty focuses on data evolution, JSD evaluates the impact of data evolution on the predictions of the deployed model.
In other words, a marked drift of a single variable with low feature importance for the deployed model should cause a high AUC but potentially a low JSD.
If You Want To Go Further…
Tutorials on the different uses of Eurybia can be found here.
I hope that Eurybia will be useful in monitoring ML models in production. Any feedback and ideas are very welcomed..! Eurybia is open source! Feel free to contribute by commenting on this post or on the GitHub discussions.
Thomas Bouché is a Data Scientist at MAIF.