Does the Random Forest Algorithm Need Normalization?
Normalization is a good technique to use when your data consists of being scaled and your choice of machine learning algorithm does not have the ability to make assumptions on the distribution of your data.

Irina Iriser via Unsplash
I’m going to start off with some definitions, to understand this blog better.
Random Forest is a tree-based algorithm consisting of multiple decision trees to improve decision-making. It is called a random forest because it is a forest of trees that uses bagging and feature randomness. These multiple trees are combined together to make predictions.
Normalization is a technique that is done during the data preparation phase for machine learning. It is the process of organizing data in a dataset by creating new values and presenting the data so that it has a general distribution. It is a type of scaling technique where values are rescaled so they range between 0 and 1 - this is also known as Min-Max scaling. This is done to reduce or completely remove redundant data, and data errors.
How Do I normalize My Data?
You can use the sklearn library to normalize your data by importing the MinMaxScaler
# data normalization with sklearn from sklearn.preprocessing import MinMaxScaler # fit scaler on your training data norm = MinMaxScaler().fit(X_train) # transform your training data X_train_norm = norm.transform(X_train) # transform testing database X_test_norm = norm.transform(X_test)
If you google the question in the title, the majority of people will say ‘No’. Here’s why...
Why Don’t I Need to Normalize Data for the Random Forest Algorithm?
The process of scaling data through normalization is to ensure that a specific feature is not prioritized over another. This technique is particularly important in algorithms that are distance-based, such as K nearest Neighbors and K-means as it requires Euclidean Distance.
However, the Random Forest algorithm is not a distance-based model - it is a tree-based model. Each node in a Random Forest is not comparing feature values, it is simply splitting a sorted list that requires absolute values for branching. The algorithm is based on partitioning the data to make predictions, therefore, it does not require normalization.
For example, a decision tree splits a node on a feature, where this feature is not influenced by another feature and neither influences another feature. This means that all the remaining features have no effect on the split - so we can say that tree-based algorithms are insensitive to the scaling of features.
Gini Index
Rather than scaling features, the Random Forest algorithm allows us to further understand the importance of features through Gini index. Also known as Gini impurity, determines how well a decision tree, random forest, or another tree-based model was split.
The formula:
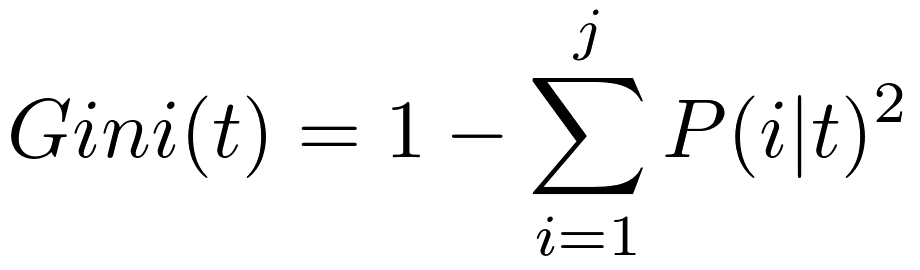
It calculates the probability that a specific feature is classified incorrectly when selected randomly. Gini impurity scales between 0-0.5, where the minimum value of 0 is the best value (classification is pure) and 0.5 is the worst value we can get.
Entropy
Entropy is the measure of impurity or randomness in the data points. When working with machine learning algorithms, your main aim should be to reduce the amount of uncertainty and randomness.
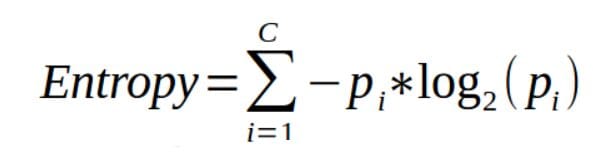
Entropy is scaled between 0 and 1, where the minimum value of 0 is the best value (purity) and 1 is the worst value (high level of impurity)
Conclusion
Normalization is a good technique to use when your data consists of being scaled and your choice of machine learning algorithm does not have the ability to make assumptions on the distribution of your data.
Tree-based models are not based on the distance where features have an effect on one another. Gini index and Entropy are both used to calculate information gain, therefore normalization is not required.
Nisha Arya is a Data Scientist and Freelance Technical Writer. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.