The Importance of Data Cleaning in Data Science
This article provides an overview of the importance of data cleaning in data science. It explains what data cleaning is, the benefits of using it, and the commonly used tools.

Image by Editor
In data science, the accuracy of predictive models is vitally important to ensure any costly errors are avoided and that each aspect is working to its optimal level. Once the data has been selected and formatted, the data needs to be cleaned, a crucial stage of the model development process.
In this article, we will provide an overview of the importance of data cleaning in data science, including what it is, the benefits, the data cleaning process, and the commonly used tools.
What Is Data Cleaning?
In data science, data cleaning is the process of identifying incorrect data and fixing the errors so the final dataset is ready to be used. Errors could include duplicate fields, incorrect formatting, incomplete fields, irrelevant or inaccurate data, and corrupted data.
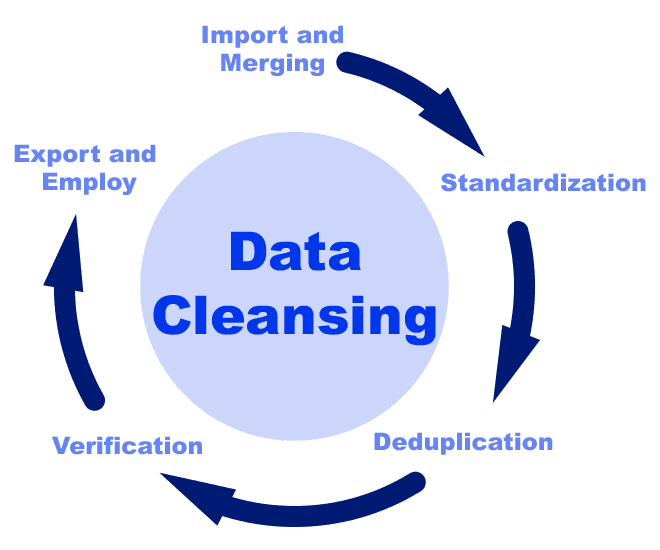
Source
In a data science project, the cleaning stage comes before validation in the data pipeline. In the pipeline, each stage ingests input and creates output, improving the data each step of the way. The benefit of the data pipeline is that each step has a specific purpose and is self-contained, meaning the data is thoroughly checked.
The Importance of Data Cleaning in Data Science
Data seldom arrives in a readily usable form; in fact, it can be confidently stated that data is never flawless. When collected from diverse sources and real-world environments, data is bound to contain numerous errors and adopt different formats. Hence, the significance of data cleaning arises -- to render the data error-free, pertinent, and easily assimilated by models.
When dealing with extensive datasets from multiple sources, errors can occur, including duplication or misclassification. These mistakes greatly affect algorithm accuracy. Notably, data cleaning and organization can consume up to 80% of a data scientist's time, highlighting its critical role in the data pipeline.
Examples of Data Cleaning
Below are three examples of how data cleaning can fix errors within datasets.
Data Formatting
Data formatting involves transforming data into a specific format or modifying the structure of a dataset. Ensuring consistency and a well-structured dataset is crucial to avoid errors during data analysis. Therefore, employing various techniques during the cleaning process is necessary to guarantee accurate data formatting. This may encompass converting categorical data to numerical values and consolidating multiple data sources into a unified dataset.
Empty/ Missing Values
Data cleaning techniques play a crucial role in resolving data issues such as missing or empty values. These techniques involve estimating and filling in gaps in the dataset using relevant information.
For instance, consider the location field. If the field is empty, scientists can populate it with the average location data from the dataset or a similar one. Although not flawless, having the most probable location is preferable to having no location information at all. This approach ensures improved data quality and enhances the overall reliability of the dataset.
Identifying Outliers
Within a dataset, certain data points may lack any substantive connection to others (e.g., in terms of value or behavior). Consequently, during data analysis, these outliers possess the ability to significantly distort results, leading to misguided predictions and flawed decision-making. However, by implementing various data cleaning techniques, it is possible to identify and eliminate these outliers, ultimately ensuring the integrity and relevance of the dataset.

Source
The Benefits of Data Cleaning
Data cleaning provides a range of benefits that have a significant impact on the accuracy, relevance, usability, and analysis of data.
- Accuracy - Using data cleaning tools and techniques significantly reduces errors and inaccuracies contained in a dataset. This is important for data analysis, helping to create models that make accurate predictions.
- Usability - Once cleaned and correctly formatted, data can be applied to a number of use cases, making it much more accessible so it can be used in a range of project types.
- Analysis - Clean data makes the analysis stage much more effective, allowing analysts to gain greater insights and deliver more reliable results.
- Efficient Data Storage - By removing unnecessary and duplicate data, storage costs are reduced as only relevant, valuable data needs to be retained, whether that is on an on-site server or a cloud data warehouse.
- Governance - Data cleaning can help organizations adhere to strict regulations and data governance, protecting the privacy of individuals and avoiding any penalties. More data compliance laws have been enacted in recent months. An example is the recent Texas consumer privacy law (TDPSA), which prohibits certain data practices such as gathering personal customer data that is not reasonably necessary for the purpose of collection.
The Data Cleaning Process: 8 Steps
The data cleaning stage of the data pipeline is made up of eight common steps:
- The removal of duplicates
- The removal of irrelevant data
- The standardization of capitalization
- Data type conversion
- The handling of outliers
- The fixing of errors
- Language Translation
- The handling of any missing values
1. The Removal of Duplicates
Large datasets that utilize multiple data sources are highly likely to have errors, including duplicates, particularly when new entries haven't undergone quality checks. Duplicate data is redundant and consumes unnecessary storage space, necessitating data cleansing to enhance efficiency. Common instances of duplicate data comprise repetitive email addresses and phone numbers.
2. The Removal of Irrelevant Data
To optimize a dataset, it is crucial to remove irrelevant data fields. This will result in faster model processing and enable a more focused approach toward achieving specific goals. During the data cleaning stage, any data that does not align with the scope of the project will be eliminated, retaining only the necessary information required to fulfill the task.
3. The Standardization of Capitalization
Standardizing text in datasets is crucial for ensuring consistency and facilitating easy analysis. Correcting capitalization is especially important, as it prevents the creation of false categories that could result in messy and confusing data.
4. Data Type Conversion
When working with CSV data using Python to manipulate it, analysts often rely on Pandas, the go-to data analysis library. However, there are instances where Pandas fall short in processing data types effectively. To guarantee accurate data conversion, analysts employ cleaning techniques. This ensures that the correct data is easily identifiable when applied to real-life projects.
5. The Handling of Outliers
An outlier is a data point that lacks relevance to other points, deviating significantly from the overall context of the dataset. While outliers can occasionally offer intriguing insights, they are typically regarded as errors that should be removed.
6. The Fixing of Errors
Ensuring the effectiveness of a model is crucial, and rectifying errors before the data analysis stage is paramount. Such errors often result from manual data entry without adequate checking procedures. Examples include phone numbers with incorrect digits, email addresses without an "@" symbol, or unpunctuated user feedback.
7. Language Translation
Datasets can be gathered from various sources written in different languages. However, when using such data for machine translation, evaluation tools typically rely on monolingual Natural Language Processing (NLP) models, which can only handle one language at a time. Thankfully, during the data cleaning phase, AI tools can come to the rescue by converting all the data into a unified language. This ensures greater coherence and compatibility throughout the translation process.
8. The Handling of Any Missing Values
One of the last steps in data cleaning involves addressing missing values. This can be achieved by either removing records that have missing values or employing statistical techniques to fill in the gaps. A comprehensive understanding of the dataset is crucial in making these decisions.
Summary
The importance of data cleaning in data science can never be underestimated as it can significantly impact the accuracy and overall success of a data model. With thorough data cleaning, the data analysis stage is likely to output flawed results and incorrect predictions.
Common errors that need to be rectified during the data cleaning stage are duplicate data, missing values, irrelevant data, outliers, and converting multiple data types or languages into a single form.
Nahla Davies is a software developer and tech writer. Before devoting her work full time to technical writing, she managed — among other intriguing things — to serve as a lead programmer at an Inc. 5,000 experiential branding organization whose clients include Samsung, Time Warner, Netflix, and Sony.