Transforming AI with LangChain: A Text Data Game Changer
Learn how to unleash this Python library to enhance our AI usage.
Image by Author
Over the past few years, Large Language Models — or LLMs for friends — have taken the world of artificial intelligence by storm.
With the groundbreaking release of OpenAI’s GPT-3 in 2020, we have witnessed a steady surge in the popularity of LLMs, which has only intensified with recent advancements in the field.
These powerful AI models have opened up new possibilities for natural language processing applications, enabling developers to create more sophisticated, human-like interactions.
Isn’t it?
However, when dealing with this AI technology it is hard to scale and generate reliable algorithms.
Amidst this rapidly evolving landscape, LangChain has emerged as a versatile framework designed to help developers harness the full potential of LLMs for a wide range of applications. One of the most important use cases is to deal with large amounts of text data.
Let’s dive in and start harnessing the power of LLMs today!
LangChain can be used in chatbots, question-answering systems, summarization tools, and beyond. However, one of the most useful - and used - applications of LangChain is dealing with text.
Today’s world is flooded with data. And one of the most notorious types is text data.
All websites and apps are being bombed with tons and tons of words every single day. No human can process this amount of information…
But can computers?
LLM techniques together with LangChain are a great way to reduce the amount of text while maintaining the most important parts of the message. This is why today we will cover two basic — but really useful — use cases of LangChain to deal with text.
- Summarization: Express the most important facts about a body of text or chat interaction. It can reduce the amount of data while maintaining the most important parts.
- Extraction: Pull structured data from a body of text or some user query. It can detect and extract keywords within the text.
Whether you’re new to the world of LLMs or looking to take your language generation projects to the next level, this guide will provide you with valuable insights and hands-on examples to unlock the full potential of LangChain to deal with text.
⚠️ If you want to have some basic grasp, you can go check ????????
LangChain 101: Build Your Own GPT-Powered Applications — KDnuggets
Always remember that for working with OpenAI and GPT models, we need to have the OpenAI library installed on our local computer and have an active OpenAI key. If you do not know how to do that, you can go check here.
1. Summarization
ChatGPT together with LangChain can summarize information quickly and in a very reliable way.
LLM summarization techniques are a great way to reduce the amount of text while maintaining the most important parts of the message. This is why LLMs can be the best ally to any digital company that needs to process and analyze large volumes of text data.
To perform the following examples, the following libraries are required:
# LangChain & LLM
from langchain.llms import OpenAI
from langchain import PromptTemplate
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
#Wikipedia API
import wikipediaapi
1.1. Short text summarization
For summaries of short texts, the method is straightforward, in fact, you don’t need to do anything fancy other than simple prompting with instructions.
Which basically means generating a template with an input variable.
I know you might be wondering… what is exactly a prompt template?
A prompt template refers to a reproducible way to generate a prompt. It contains a text string - a template - that can take in a set of parameters from the end user and generates a prompt.
A prompt template contains:
- instructions to the language model - that allow us to standardize some steps for our LLM.
- an input variable - that allows us to apply the previous instructions to any input text.
Let’s see this in a simple example. I can standardize a prompt that generates a name of a brand that produces a specific product.

Screenshot of my Jupyter Notebook.
As you can observe in the previous example, the magic of LangChain is that we can define a standardized prompt with a changing input variable.
- The instructions to generate a name for a brand remain always the same.
- The product variable works as an input that can be changed.
This allows us to define versatile prompts that can be used in different scenarios.
So now that we know what a prompt template is…
Let’s imagine we want to define a prompt that summarizes any text using super easy-to-understand vocabulary. We can define a prompt template with some specific instructions and a text variable that changes depending on the input variable we define.
# Create our prompt string.
template = """
%INSTRUCTIONS:
Please summarize the following text.
Always use easy-to-understand vocabulary so an elementary school student can understand.
%TEXT:
{input_text}
"""
Now we define the LLM we want to work with - OpenAI’s GPT in my case - and the prompt template.
# The default model is already 'text-davinci-003', but it can be changed.
llm = OpenAI(temperature=0, model_name='text-davinci-003', openai_api_key=openai_api_key)
# Create a LangChain prompt template that we can insert values to later
prompt = PromptTemplate(
input_variables=["input_text"],
template=template,
)
So let’s try this prompt template. Using the wikipedia API, I am going to get the summary of the USA country and further summarize it in a really easy-to-understand tone.
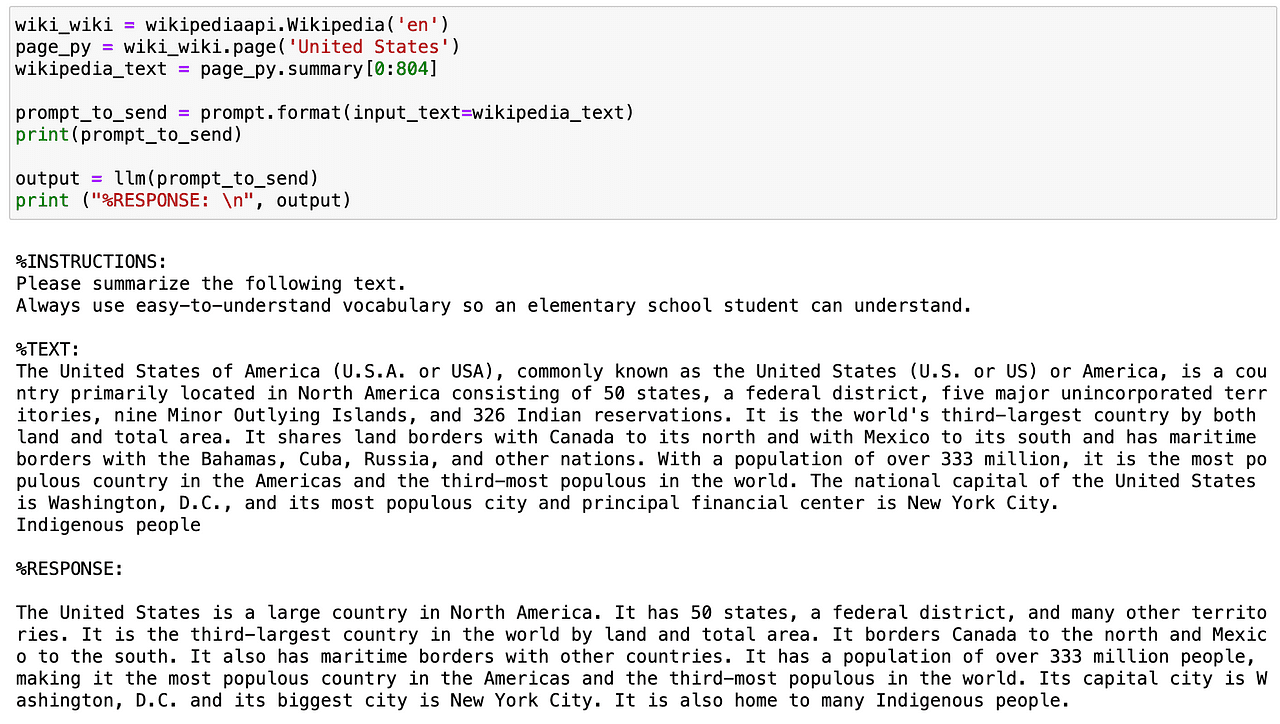
Screenshot of my Jupyter Notebook.
So now that we know how to summarize a short text… can I spice this up a bit?
Sure we can with…
1.2. Long text summarization
When dealing with long texts, the main problem is that we cannot communicate them to our AI model directly via prompt, as they contain too many tokens.
And now you might be wondering… what is a token?
Tokens are how the model sees the input — single characters, words, parts of words, or segments of text. As you can observe, the definition is not really precise and it depends on every model. For instance, OpenAI’s GPT 1000 tokens are approximately 750 words.
But the most important thing to learn is that our cost depends on the number of tokens and that we cannot send as many tokens as we want in a single prompt. To have a longer text, we will repeat the same example as before but using the whole Wikipedia page text.
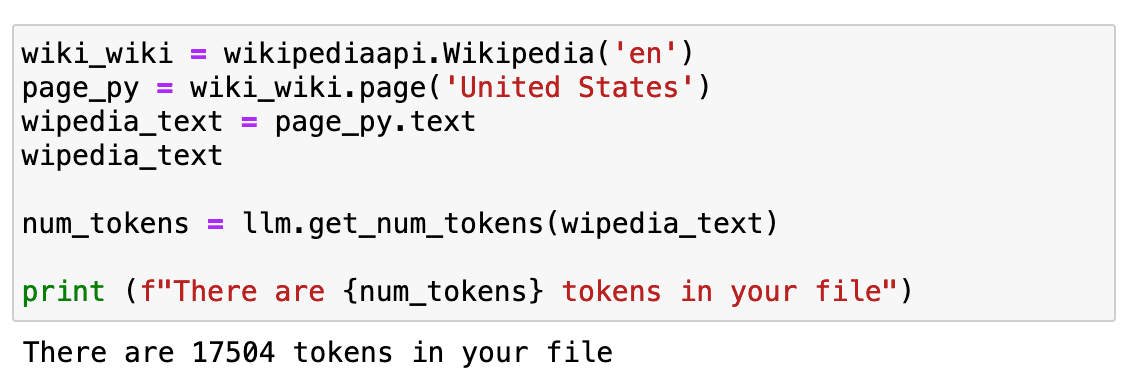
Screenshot of my Jupyter Notebook.
If we check how long it is… it is around 17K tokens.
Which is quite a lot to be sent directly to our API.
So what now?
First, we’ll need to split it up. This process is called chunking or splitting your text into smaller pieces. I usually use RecursiveCharacterTextSplitter because it’s easy to control but there are a bunch you can try.
After using it, instead of just having a single piece of text, we get 23 pieces which facilitate the work of our GPT model.
Next we need to load up a chain which will make successive calls to the LLM for us.
LangChain provides the Chain interface for such chained applications. We define a Chain very generically as a sequence of calls to components, which can include other chains. The base interface is simple:
class Chain(BaseModel, ABC):
"""Base interface that all chains should implement."""
memory: BaseMemory
callbacks: Callbacks
def __call__(
self,
inputs: Any,
return_only_outputs: bool = False,
callbacks: Callbacks = None,
) -> Dict[str, Any]:
...
If you want to learn more about chains, you can go check directly in the LangChain documentation.
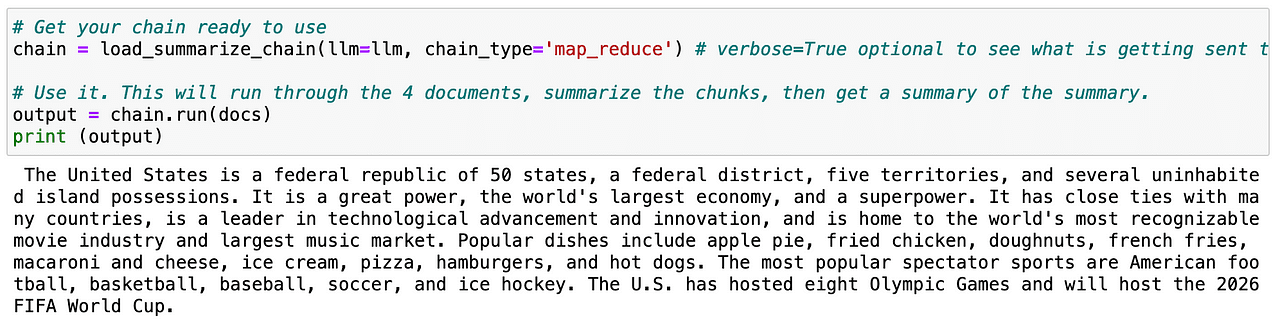
So if we repeat again the same procedure with the splitted text - called docs - the LLM can easily generate a summary of the whole page.

Screenshot of my Jupyter Notebook.
Useful right?
So now that we know how to summarize text, we can move to the second use case!
2. Extraction
Extraction is the process of parsing data from a piece of text. This is commonly used with output parsing to structure our data.
Extracting key data is really useful in order to identify and parse key words within a text. Common use cases are extracting a structured row from a sentence to insert into a database or extracting multiple rows from a long document to insert into a database.
Let’s imagine we are running a digital e-commerce company and we need to process all reviews that are stated on our website.
I could go read all of them one by one… which would be crazy.
Or I can simply EXTRACT the information that I need from each of them and analyze all the data.
Sounds easy… right?
Let’s start with a quite simple example. First, we need to import the following libraries:
# To help construct our Chat Messages
from langchain.schema import HumanMessage
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
# We will be using a chat model, defaults to gpt-3.5-turbo
from langchain.chat_models import ChatOpenAI
# To parse outputs and get structured data back
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
chat_model = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo', openai_api_key=openai_api_key)
2.1. Extracting specific words
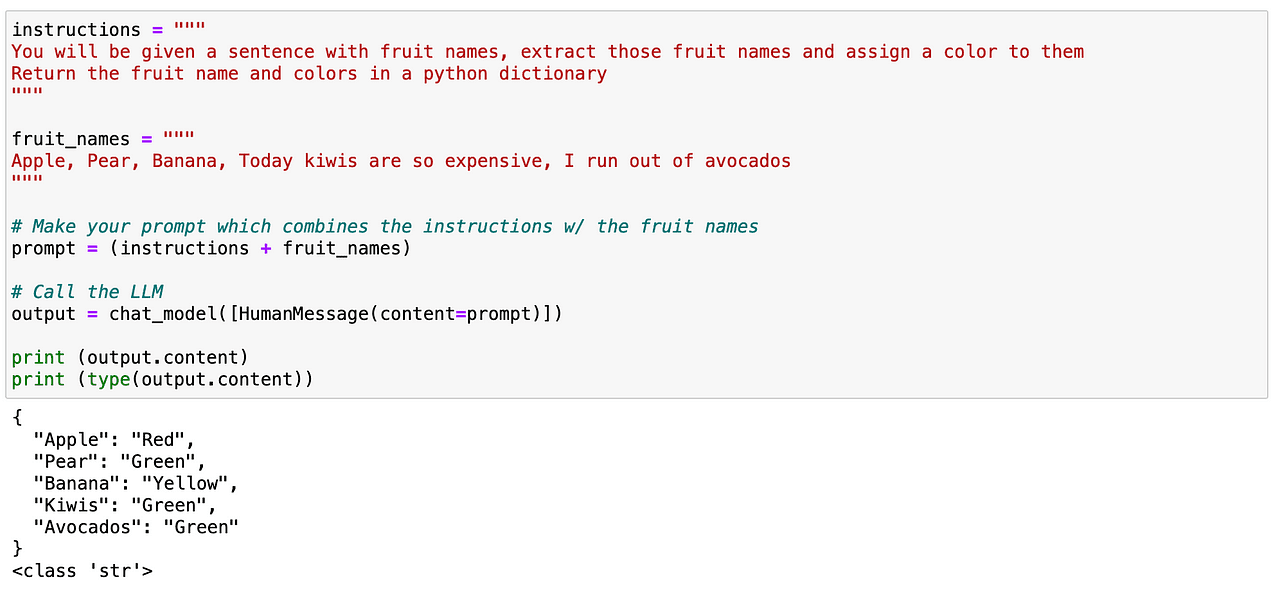
I can try to look for specific words within some text. In this case, I want to parse all fruits that are contained within a text. Again, it is quite straightforward as before. We can easily define a prompt giving clear instructions to our LLM stating that identifies all fruits contained in a text and gives back a JSON-like structure containing such fruits and their corresponding colors.
Screenshot of my Jupyter Notebook.
And as we can see before, it works perfectly!
So now… let’s play a little bit more with it. While this worked this time, it’s not a long term reliable method for more advanced use cases. And this is where a fantastic LangChain concept comes into play…
2.2. Using LangChain’s Response Schema
LangChain’s response schema will do two main things for us:
- Generate a prompt with bonafide format instructions. This is great because I don’t need to worry about the prompt engineering side, I’ll leave that up to LangChain!
- Read the output from the LLM and turn it into a proper python object for me. Which means, always generate a given structure that is useful and that my system can parse.
And to do so, I just need to define what response I except from the model.
So let’s imagine I want to determine the products and brands that users are stating in their comments. I could easily perform as before with a simple prompt - take advantage of LangChain to generate a more reliable method.
So first I need to define a response_schema where I define every keyword I want to parse with a name and a description.
# The schema I want out
response_schemas = [
ResponseSchema(name="product", description="The name of the product to be bought"),
ResponseSchema(name="brand", description= "The brand of the product.")
]
And then I generate an output_parser object that takes as an input my response_schema.
# The parser that will look for the LLM output in my schema and return it back to me
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
After defining our parser, we generate the format of our instruction using the .get_format_instructions() command from LangChain and define the final prompt using the ChatPromptTemplate. And now it is as easy as using this output_parser object with any input query I can think of, and it will automatically generate an output with my desired keywords.
Screenshot of my Jupyter Notebook.
As you can observe in the example below, with the input of “I run out of Yogurt Danone, No-brand Oat Milk and those vegan bugers made by Heura”, the LLM gives me the following output:

Screenshot of my Jupyter Notebook.
Main Takeaways
LangChain is a versatile Python library that helps developers harness the full potential of LLMs, especially for dealing with large amounts of text data. It excels at two main use cases for dealing with text. LLMs enable developers to create more sophisticated and human-like interactions in natural language processing applications.
- Summarization: LangChain can quickly and reliably summarize information, reducing the amount of text while preserving the most important parts of the message.
- Extraction: The library can parse data from a piece of text, allowing for structured output and enabling tasks like inserting data into a database or making API calls based on extracted parameters.
- LangChain facilitates prompt engineering, which is a crucial technique for maximizing the performance of AI models like ChatGPT. With prompt engineering, developers can design standardized prompts that can be reused across different use cases, making the AI application more versatile and effective.
Overall, LangChain serves as a powerful tool to enhance AI usage, especially when dealing with text data, and prompt engineering is a key skill for effectively leveraging AI models like ChatGPT in various applications.
Josep Ferrer is an analytics engineer from Barcelona. He graduated in physics engineering and is currently working in the Data Science field applied to human mobility. He is a part-time content creator focused on data science and technology. You can contact him on LinkedIn, Twitter or Medium.