Building Data Pipelines to Create Apps with Large Language Models
For production grade LLM apps, you need a robust data pipeline. This article talks about the different stages of building a Gen AI data pipeline and what is included in these stages.

Image from DALL-E 3
Enterprises currently pursue two approaches for LLM powered Apps - Fine tuning and Retrieval Augmented Generation (RAG). At a very high level, RAG takes an input and retrieves a set of relevant/supporting documents given a source (e.g., company wiki). The documents are concatenated as context with the original input prompt and fed to the LLM model which produces the final response. RAG seems to be the most popular approach to get LLMs to market especially in real-time processing scenarios. The LLM architecture to support that most of the time includes building an effective data pipeline.
In this post, we’ll explore different stages in the LLM data pipeline to help developers implement production-grade systems which work with their data. Follow along to learn how to ingest, prepare, enrich, and serve data to power GenAI apps.
What are the Different Stages of an LLM pipeline?
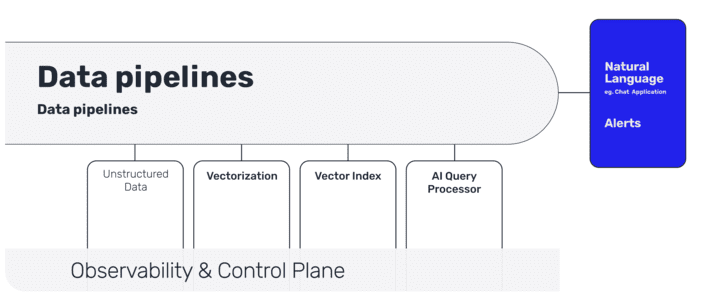
These are the different stages of an LLM pipeline:
Data ingestion of unstructured data
Vectorization with enrichment (with metadata)
Vector indexing (with real-time syncing)
AI Query Processor
Natural Language User interaction (with Chat or APIs)
Data Ingestion of unstructured data
The first step is gathering the right data to help with the business goals. If you are building a consumer facing chatbot then you have to pay special attention to what data is going to be used. The sources of data could range from a company portal (e.g. Sharepoint, Confluent, Document storage) to internal APIs. Ideally you want to have a push mechanism from these sources to the index so that your LLM app is up to date for your end consumer.
Organizations should implement data governance policies and protocols when extracting text data for LLM in context training. Organizations can start by auditing document data sources to catalog sensitivity levels, licensing terms and origin. Identify restricted data that needs redaction or exclusion from datasets.
These data sources should also be assessed for quality - diversity, size, noise levels, redundancy. Lower quality datasets will dilute the responses from LLM apps. You might even need an early document classification mechanism to help with the right kind of storage later in the pipeline.
Adhering to data governance guardrails, even in fast-paced LLM development, reduces risks. Establishing governance upfront mitigates many issues down the line and enables scalable, robust extraction of text data for context learning.
Pulling messages via Slack, Telegram, or Discord APIs gives access for real-time data is what helps RAG but raw conversational data contains noise - typos, encoding issues, weird characters. Filtering out messages real-time with offensive content or sensitive personal details that could be PII is an important part of data cleansing.
Vectorization with metadata
Metadata like author, date, and conversation context further enriches data. This embedding of external knowledge into vectors helps with smarter and targeted retrieval.
Some of the metadata related to documents could lie in the portal or in the document’s metadata itself, however if the document is attached to a business object( e.g. Case, Customer , Employee information) then you would have to fetch that information from a relational database. If there are security concerns around data access, this is a place where you can add security metadata which also helps with the retrieval stage later in the pipeline.
A critical step here is to convert text and images into vector representations using the LLM’s embedding models. For documents, you need to do chunking first, then you do encoding preferably using on-prem zero shot embedding models.
Vector indexing
Vector representations have to be stored somewhere. This is where vector databases or vector indexes are used to efficiently store and index this information as embeddings.
This becomes your “LLM source of truth” and this has to be in sync with your data sources and documents. Real-time indexing becomes important if your LLM app is servicing customers or generating business related information. You want to avoid your LLM app being out of sync with your data sources.
Fast retrieval with a query processor
When you have millions of enterprise documents, getting the right content based on the user query becomes challenging.
This is where the early stages of pipeline starts adding value : Cleansing and Data enrichment via metadata addition and most importantly Data indexing. This in-context addition helps with making prompt engineering stronger.
User interaction
In a traditional pipelining environment, you push the data to a data warehouse and the analytics tool will pull the reports from the warehouse. In an LLM pipeline, an end user interface is usually a chat interface which at the simplest level takes a user query and responds to the query.
Summary
The challenge with this new type of pipeline is not just getting a prototype but getting this running in production. This is where an enterprise grade monitoring solution to track your pipelines and vector stores becomes important. The ability to get business data from both structured and unstructured data sources becomes an important architectural decision. LLMs represent the state-of-the-art in natural language processing and building enterprise grade data pipelines for LLM powered apps keeps you at the forefront.
Here is access to a source available real-time stream processing framework.
Anup Surendran is a Head of Product Marketing at Pathway who specializes in bringing AI products to market. He has worked with startups that have had two successful exits (to SAP and Kroll) and enjoys teaching others about how AI products can improve productivity within an organization.