Introduction to NExT-GPT: Any-to-Any Multimodal Large Language Model
The future of the multimodal large language model.
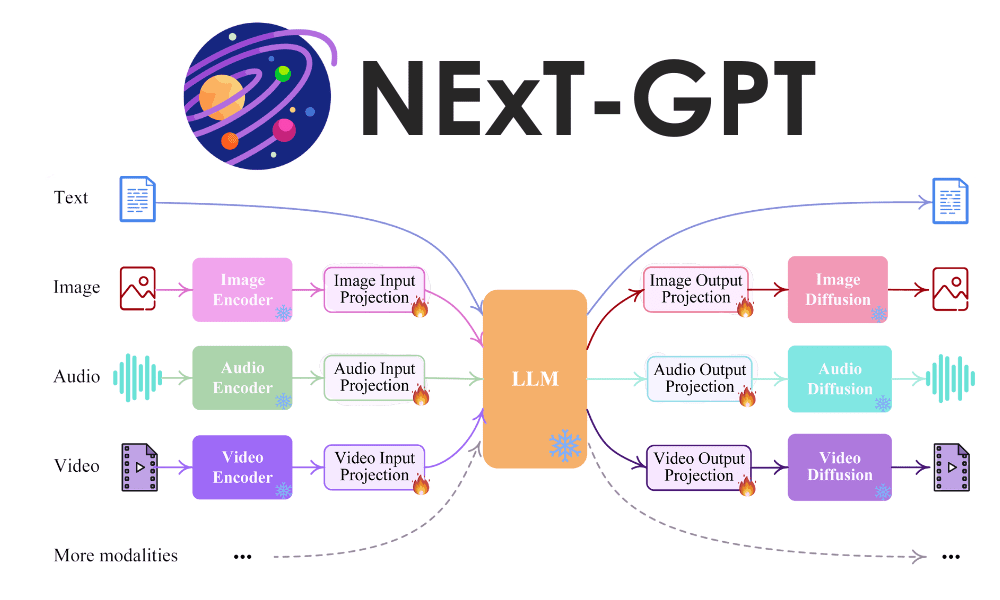
Image by Editor
In recent years, Generative AI research has evolved in a way that has changed how we work. From developing content, planning our work, and finding answers to creating artwork, it’s all possible now with Generative AI. However, each model usually works for certain use cases, e.g., GPT for text-to-text, Stable Diffusion for text-to-image, and many others.
The model capable of performing multiple tasks is called the multimodal model. Much state-of-the-art research is moving in the multimodal direction as it’s proven useful in many conditions. This is why one of the exciting research regarding multimodal people need to know is the NExT-GPT.
NExT-GPT is a multimodal model that could transform anything into anything. So, how does it work? Let’s explore it further.
NExT-GPT Introduction
NExT-GPT is an any-to-any multimodal LLM that can handle four different kinds of input and output: text, images, videos, and audio. The research was initiated by the research group called NExT++ of the National University of Singapore.
The overall representation of the NExT-GPT model is shown in the image below.
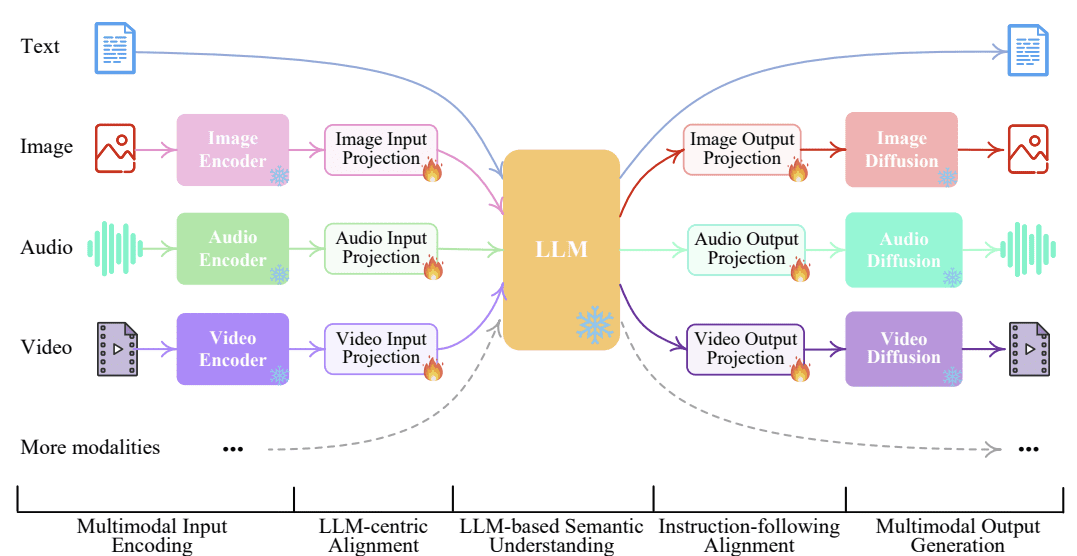
NExT-GPT LLM Model (Wu et al. (2023))
NExT-GPT model consists of three parts of works:
- Establish encoders for input from various modalities and represent them into a language-like input that LLM could accept,
- Utilizing the open-source LLM as the core to process the input for both semantic understanding and reasoning with additional unique modality signal,
- Provide multimodal signal into different encoders and generate the result to the appropriate modalities.
An example of the NExT-GPT inferences process can be seen in the image below.
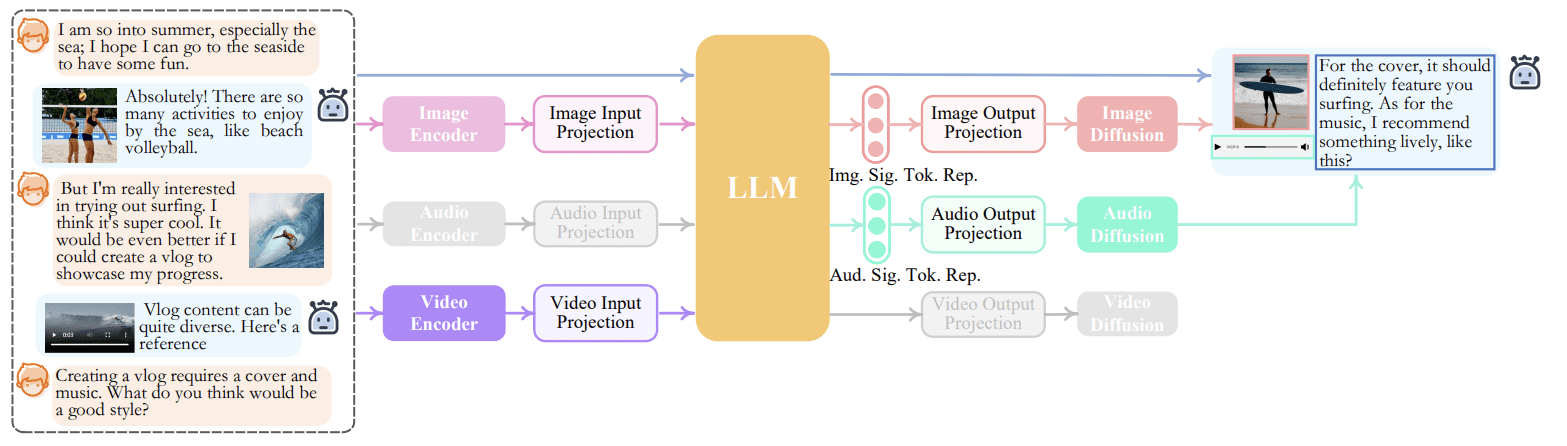
NExT-GPT inference Process (Wu et al. (2023))
We can see in the image above that depending on the tasks that we want, the encoder and decoder would switch to the appropriate modalities. This process can only happen because NExT-GPT utilizes a concept called modality-switching instruction tuning so the model can conform with the user's intention.
The researchers have tried to experiment with various combinations of modalities. Overall, the NExT-GPT performance can be summarized in the graph below.
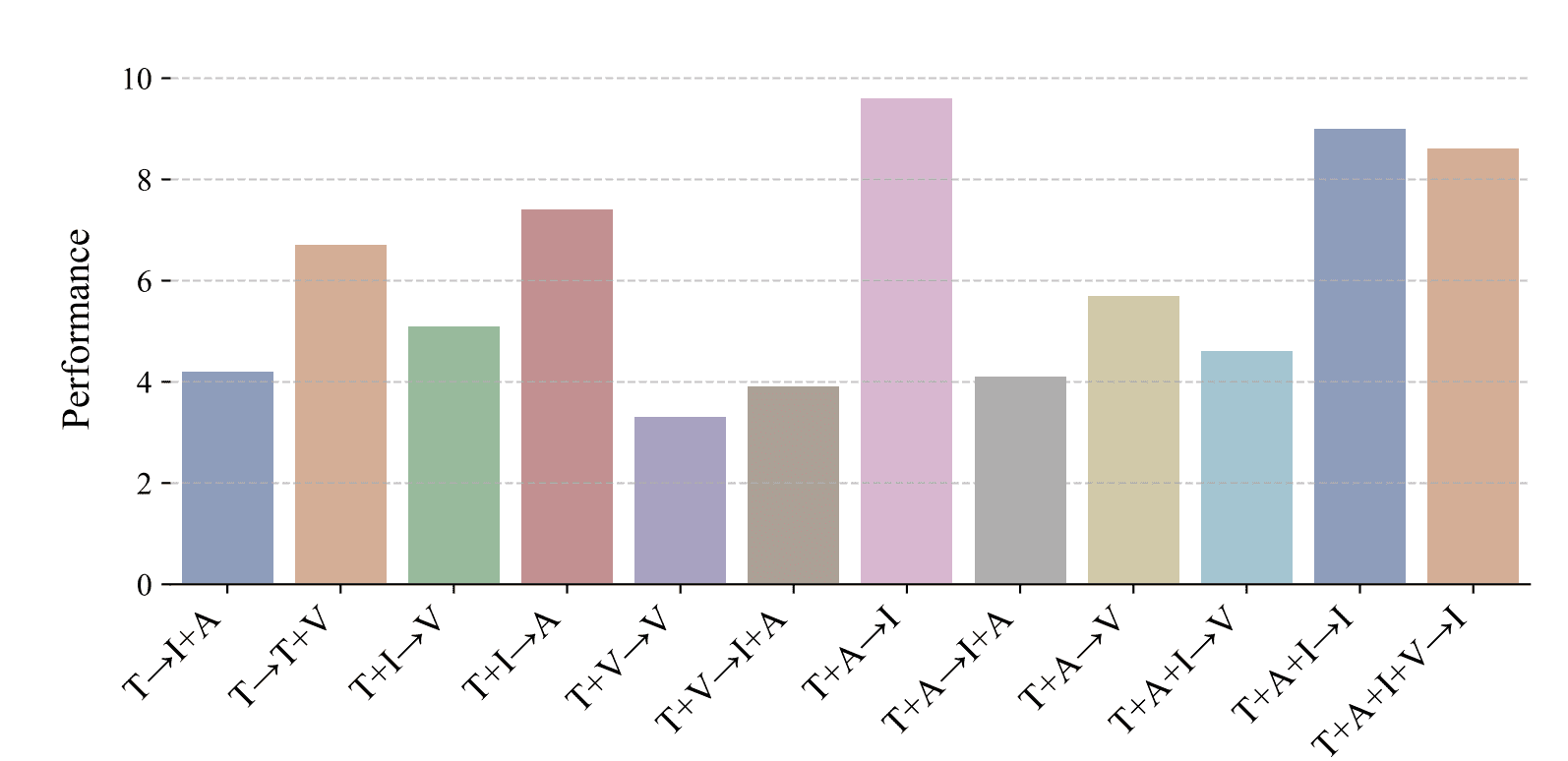
NExT-GPT Overall Performance Result (Wu et al. (2023))
NExT-GPT's best performance is the Text and Audio input to produce Images, followed by the Text, Audio, and Image input to produce Image results. The least performing action is the Text and Video input to produce Video output.
An example of the NExT-GPT capability is shown in the image below.
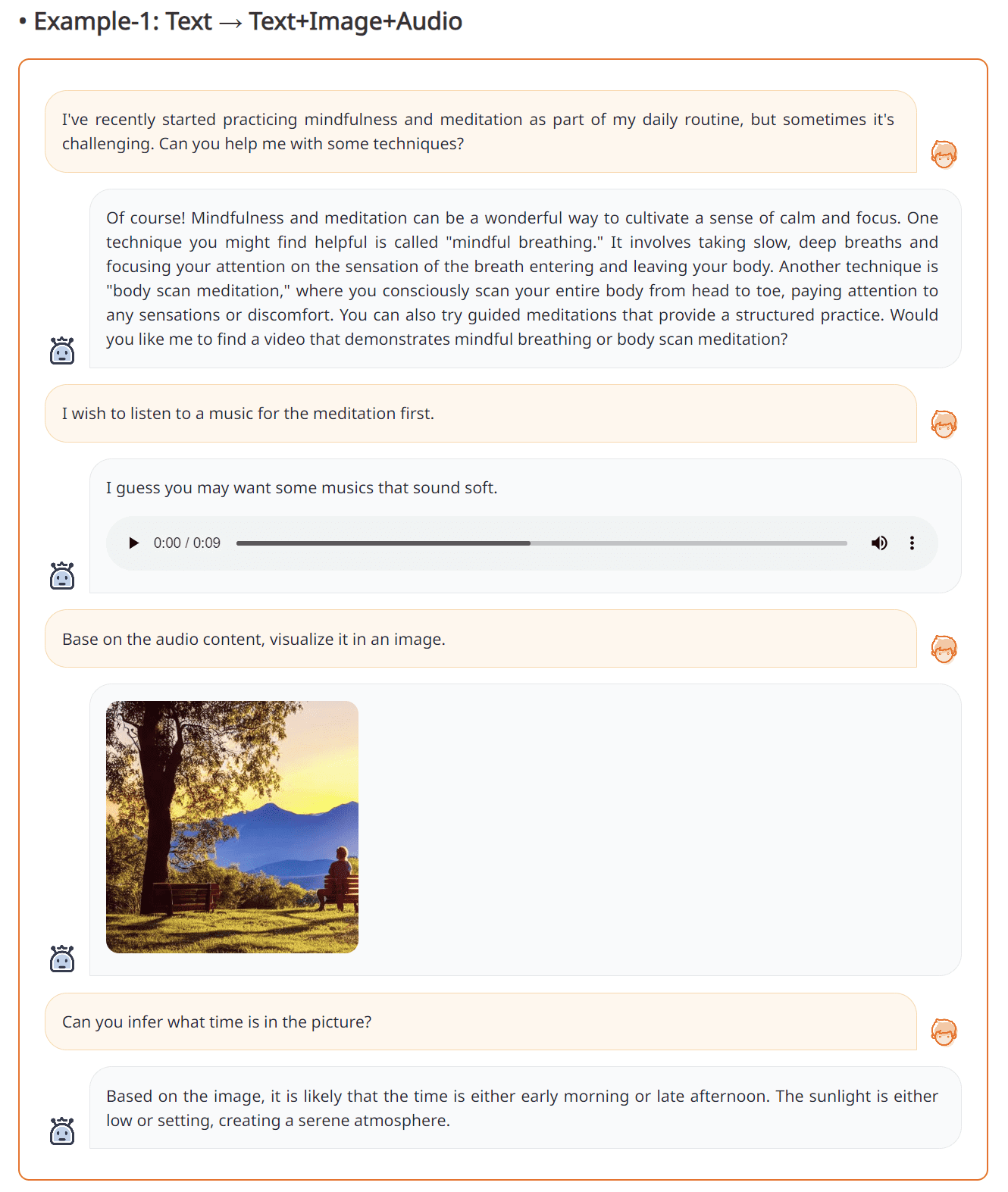
Text-to-Text+Image+Audio from NExT-GPT (Source: NExT-GPT web)
The result above shows that interacting with the NExT-GPT can produce Audio, Text, and Images appropriate to the user's intention. It’s shown that NExT-GPT can act quite well and is pretty reliable.
Another example of NExT-GPT is shown in the image below.
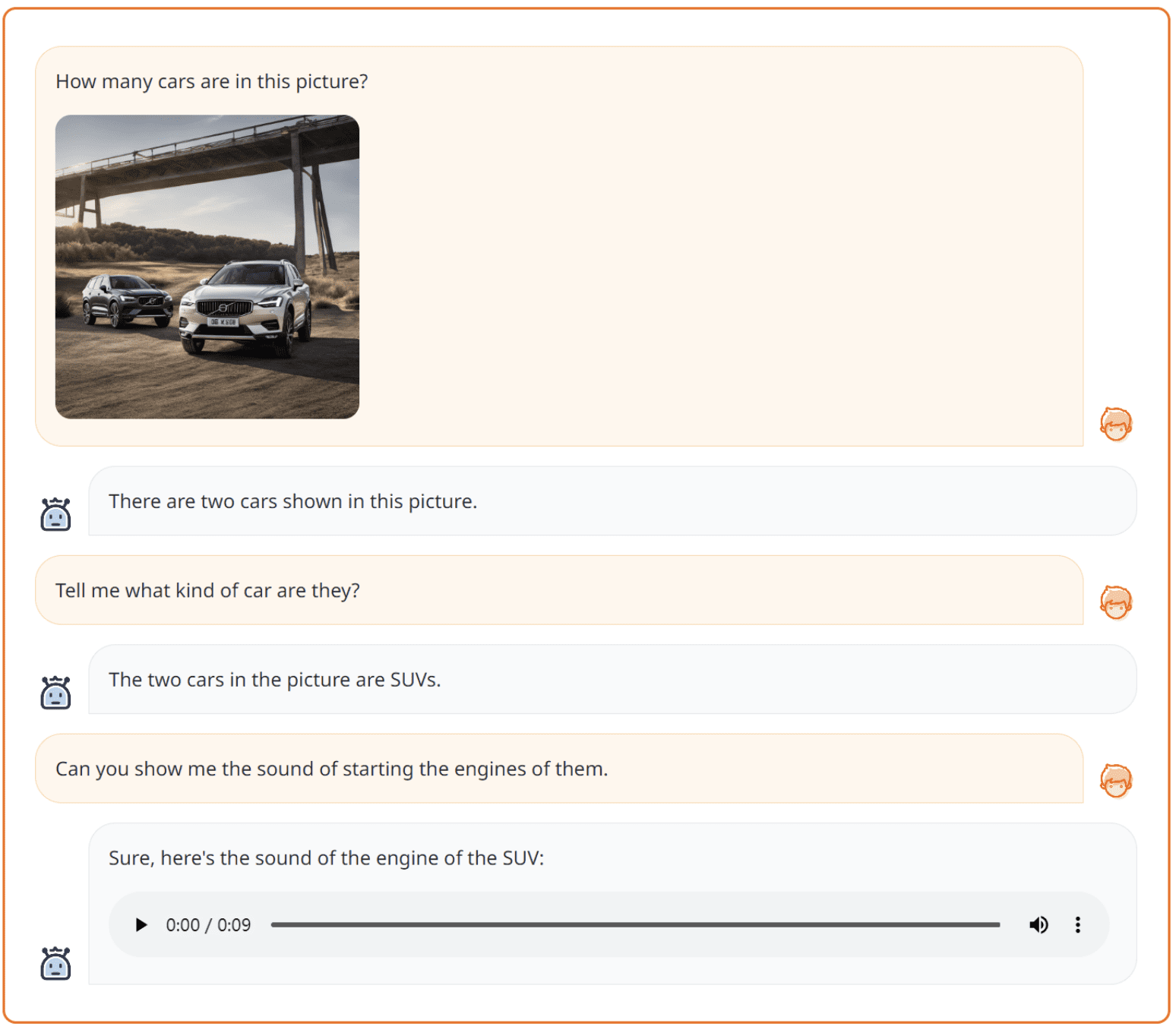
Text+Imaget-to-Text+Audio from NExT-GPT (Source: NExT-GPT web)
The image above shows that NExT-GPT can handle two kinds of modalities to produce Text and Audio output. It’s shown how the model is versatile enough.
If you want to try the model, you can set up the model and environment from their GitHub page. Additionally, you can try out the demo on the following page.
Conclusion
NExT-GPT is a multimodal model that accepts input data and produces output in text, image, audio, and video. This model works by utilizing a specific encoder for the modalities and switching to appropriate modalities according to the user's intention. The performance experiment result shows a good result and promising work that can be used in many applications.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and data tips via social media and writing media. Cornellius writes on a variety of AI and machine learning topics.