Multimodal Models Explained
Unlocking the Power of Multimodal Learning: Techniques, Challenges, and Applications.
Image by Author
Deep learning is a type of intelligence developed to mimic the systems and neurons in the human brain, which play an essential role in the human thinking process.
This technology utilizes deep neural networks, which are composed of layers of artificial neurons that can analyze and process vast amounts of data, enabling them to learn and improve over time.
We, humans, rely on our five senses to interpret the world around us. We use our senses of sight, hearing, touch, taste, and smell to gather information about our environment and make sense of it.
In a similar vein, multimodal learning is an exciting new field of AI that seeks to replicate this ability by combining information from multiple models. By integrating information from diverse sources such as text, image, audio, and video, multimodal models can build a richer and more complete understanding of the underlying data, unlock new insights, and enable a wide range of applications.
The techniques used in multimodal learning include fusion-based approaches, alignments-based approaches, and late fusion.
In this article, we will explore the fundamentals of multimodal learning, including the different techniques used to fuse information from diverse sources, as well as its many exciting applications, from speech recognition to autonomous cars and beyond.
What is Multimodal Learning?
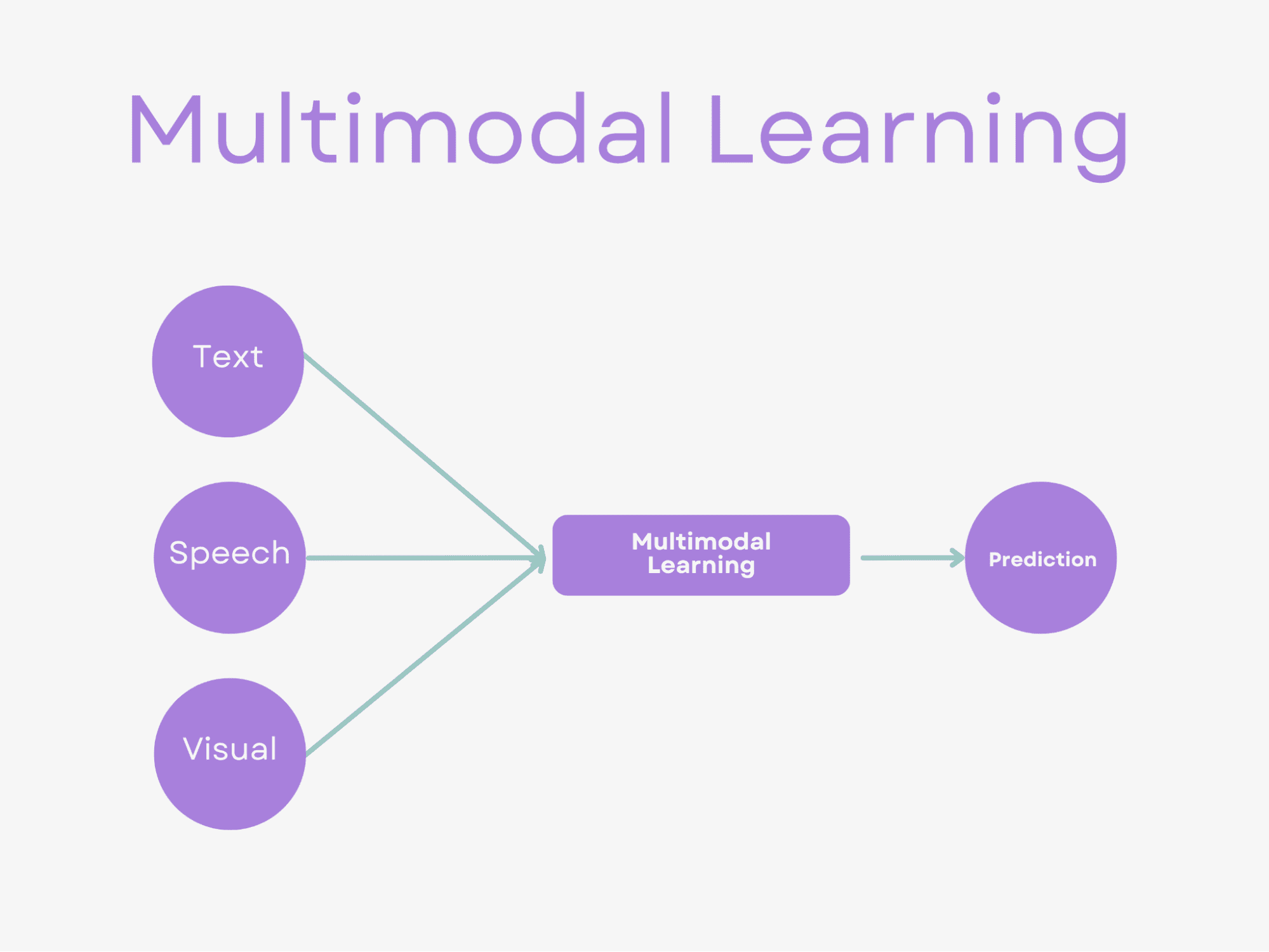
Image by Author
Multimodal learning is a subfield of artificial intelligence that seeks to effectively process and analyze data from multiple modalities.
In simple terms, this means combining information from different sources such as text, image, audio, and video to build a more complete and accurate understanding of the underlying data.
The concept of multimodal learning has found applications in a wide range of subjects, including speech recognition, autonomous car, and emotion recognition. We’ll talk about them in the following sections.
The multimodal learning techniques enable models to process and analyze data from multiple modalities effectively, providing a more complete and accurate understanding of the underlying data.
In the next section, we will mention these techniques, but before doing that, let’s talk about combining models.
These two concepts might look alike, but you’ll soon discover they aren’t.
Combining Models
Combining models is a technique in machine learning that involves using multiple models to improve the performance of a single model.
The idea behind combining models is that one model's strengths can compensate for another's weakness, resulting in a more accurate and robust prediction. Ensemble models, stacking, and bagging are techniques used in combining models.

Image by Author
Ensemble models

Image by Author
Ensemble models involve combining the outputs of multiple base models to produce a better overall model.
One example of an ensemble model is random forests. Random forests are a decision tree algorithm that combines multiple decision trees to improve the model's accuracy. Each decision tree is trained on a different subset of the data, and the final prediction is made by averaging the predictions of all the trees.
You can see how to use the random forests algorithm in the scikit-learn library here.
Stacking

Image by Author
Stacking involves using the outputs of multiple models as inputs to another model.
One real-life example of stacking is in natural language processing, where it can be applied to sentiment analysis.
For instance, the Stanford Sentiment Treebank dataset contains movie reviews with sentiment labels ranging from very negative to very positive. In this case, multiple models such as random forest, Support Vector Machines (SVM), and Naive Bayes can be trained to predict the sentiment of the reviews.
The predictions of these models can then be combined using a meta-model such as logistic regression or neural network, which is trained on the outputs of the base models to make the final prediction.
Stacking can improve the accuracy of sentiment prediction and make sentiment analysis more robust.
Bagging

Image by Author
Bagging is another way of creating ensembles, where several base models are trained on different subsets of data, and their predictions are averaged to make a final decision.
One example of bagging is the bootstrap aggregating method, where multiple models are trained on different subsets of the training data. The final prediction is made by averaging the predictions of all the models.
An example of bagging in real life is in finance. The S&P 500 dataset contains historical data on the stock prices of the 500 largest publicly traded companies in the United States between 2012 and 2018.
Bagging can be used in this dataset by training multiple models in scikit-learn, such as random forests and gradient boosting, to predict the companies' stock prices.
Each model is trained on a different subset of the training data, and their predictions are averaged to make the final prediction. The use of bagging can improve the accuracy of the stock price prediction and make the financial analysis more robust.
Difference Between Combining Models & Multimodal Learning
In combining models, the models are trained independently, and the final prediction is made by combining the outputs of these models using techniques such as ensemble models, stacking, or bagging.
Combining models is particularly useful when the individual models have complementary strengths and weaknesses, as the combination can lead to a more accurate and robust prediction.
In multimodal learning, the goal is to combine information from different modalities to perform a prediction task. This can involve using techniques such as the fusion-based approach, alignment-based approach, or late fusion to create a high-dimensional representation that captures the semantic information of the data from each modality.
Multimodal learning is particularly useful when different modalities provide complementary information that can improve the accuracy of the prediction.
The main difference between combining models and multimodal learning is that combining models involve using multiple models to improve the performance of a single model. In contrast, multimodal learning involves learning from and combining information from multiple modalities such as image, text, and audio to perform a prediction test.
Now, let’s look at multimodal learning techniques.
Multimodal Learning Techniques
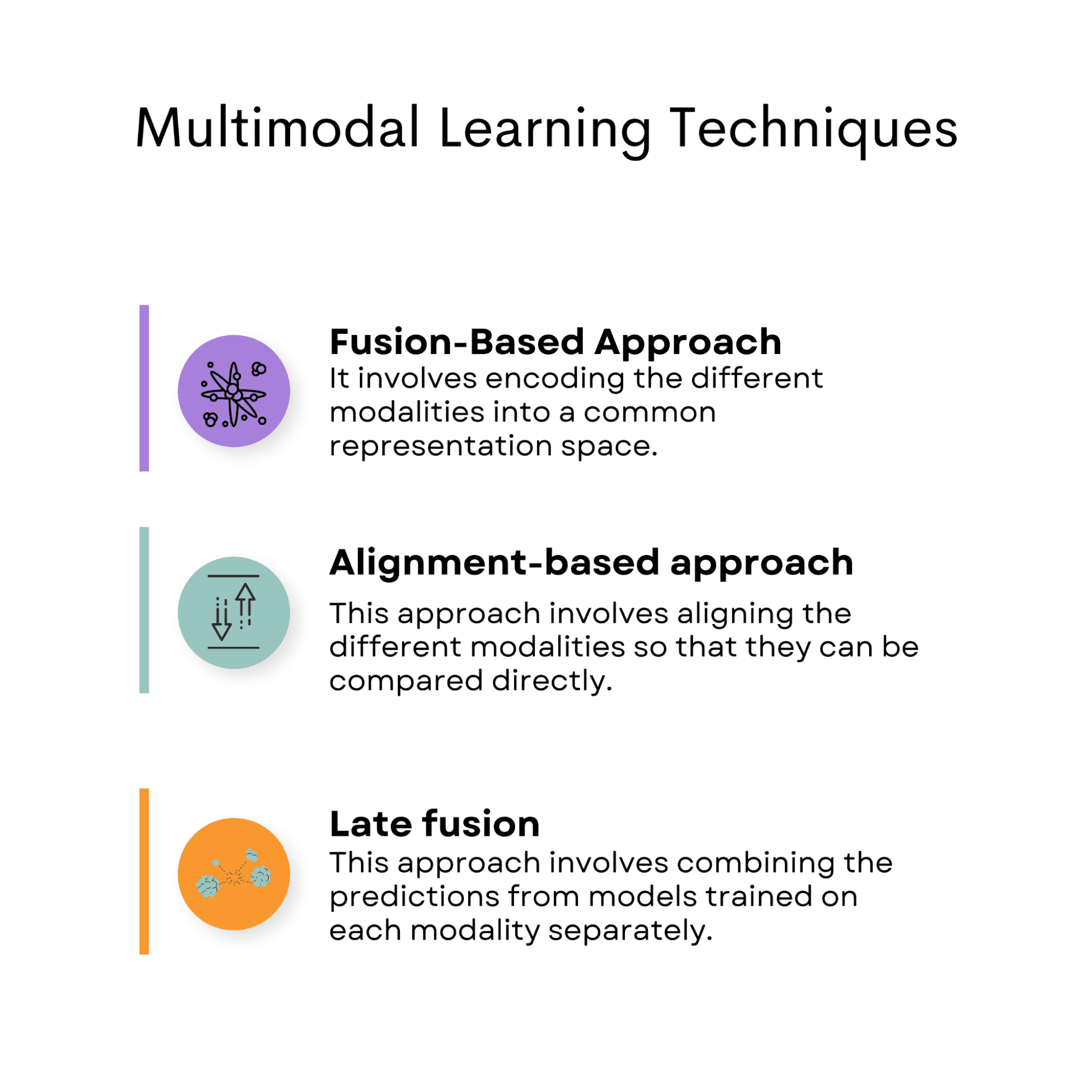
Image by Author
Fusion-Based Approach
The fusion-based approach involves encoding the different modalities into a common representation space, where the representations are fused to create a single modality-invariant representation that captures the semantic information from all modalities.
This approach can be further divided into early fusion and mid-fusion techniques, depending on when the fusion occurs.
Text Captioning
A typical example of a fusion-based approach is an image and text captioning.
It’s the fusion-based approach because the image's visual features and the text's semantic information are encoded into a common representation space and then fused to generate a single modality-invariant representation that captures the semantic information from both modalities.
Specifically, the visual features of the image are extracted using a convolutional neural network (CNN), and the semantic information of the text is captured using a recurrent neural network (RNN).
These two modalities are then encoded into a common representation space. The visual and textual features are fused using concatenation or element-wise multiplication techniques to create a single modality-invariant representation.
This final representation can then be used to generate a caption for the image.
One open-source dataset that can be used to perform image and text captioning is the Flickr30k dataset, which contains 31,000 images along with five captions per image. This dataset contains images of various everyday scenes, with each image annotated by multiple people to provide diverse captions.

Source: https://paperswithcode.com/dataset/flickr30k-cna
The Flickr30k dataset can be used to apply the fusion-based approach for image and text captioning by extracting visual features from pre-trained CNNs and using techniques such as word embeddings or bag-of-words representations for textual features. The resulting fused representation can be used to generate more accurate and informative captions.
Alignment-Based Approach
This approach involves aligning the different modalities so that they can be compared directly.
The goal is to create modality-invariant representations that can be compared across modalities. This approach is advantageous when the modalities share a direct relationship, such as in audio-visual speech recognition.
Sign Language Recognition

Image by Author
One example of an alignment-based approach is in the task of sign language recognition.
This use involves the alignment-based approach because it requires the model to align the temporal information of both visual (video frames) and audio (audio waveform) modalities.
The task is for the model to recognize sign language gestures and translate them into text. The gestures are captured using a video camera, and the corresponding audio and the two modalities must be aligned to recognize the gestures accurately. This involves identifying the temporal alignment between the video frames and the audio waveform to recognize the gestures and the corresponding spoken words.
One open-source dataset for sign language recognition is the RWTH-PHOENIX-Weather 2014T dataset which contains video recordings of German Sign Language (DGS) from various signers. The dataset includes both visual and audio modalities, making it suitable for multimodal learning tasks that require alignment-based approaches.
Late Fusion
This approach involves combining the predictions from models trained on each modality separately. The individual predictions are then combined to create a final prediction. This approach is particularly useful when the modalities are not directly related, or the individual modalities provide complementary information.
Emotion Recognition

Image by Author
A real-life example of late fusion is emotion recognition in music. In this task, the model must recognize the emotional content of a piece of music using both the audio features and the lyrics.
The late fusion approach is applied in this example because it combines the predictions from models trained on separate modalities (audio features and lyrics) to create a final prediction.
The individual models are trained separately on each modality, and the predictions are combined at a later stage.Therefore, late fusion.
The audio features can be extracted using techniques such as Mel-frequency cepstral coefficients (MFCCs), while the lyrics can be encoded using techniques such as bag-of-words or word embeddings. Models can be trained separately on each modality, and the predictions can be combined using late fusion to generate a final prediction.
The DEAM dataset was designed to support research on music emotion recognition and analysis, and it includes both audio features and lyrics for a collection of over 2,000 songs. The audio features include various descriptors such as MFCCs, spectral contrast, and rhythm features, while the lyrics are represented using bag-of-words and word embedding techniques.
The late fusion approach can be applied to the DEAM dataset by combining the predictions from separate models trained on each modality (audio and lyrics).

Source: DEAM Dataset - Emotional Analysis in Music
For example, you can train a separate machine learning model to predict the emotional content of each song using audio features, such as MFCCs and spectral contrast.
Another model can be trained to predict the emotional content of each song using the lyrics, represented using techniques such as bag-of-words or word embeddings.
After training the individual models, the predictions from each model can be combined using the late fusion approach to generate a final prediction.
Multimodal Learning Challenges
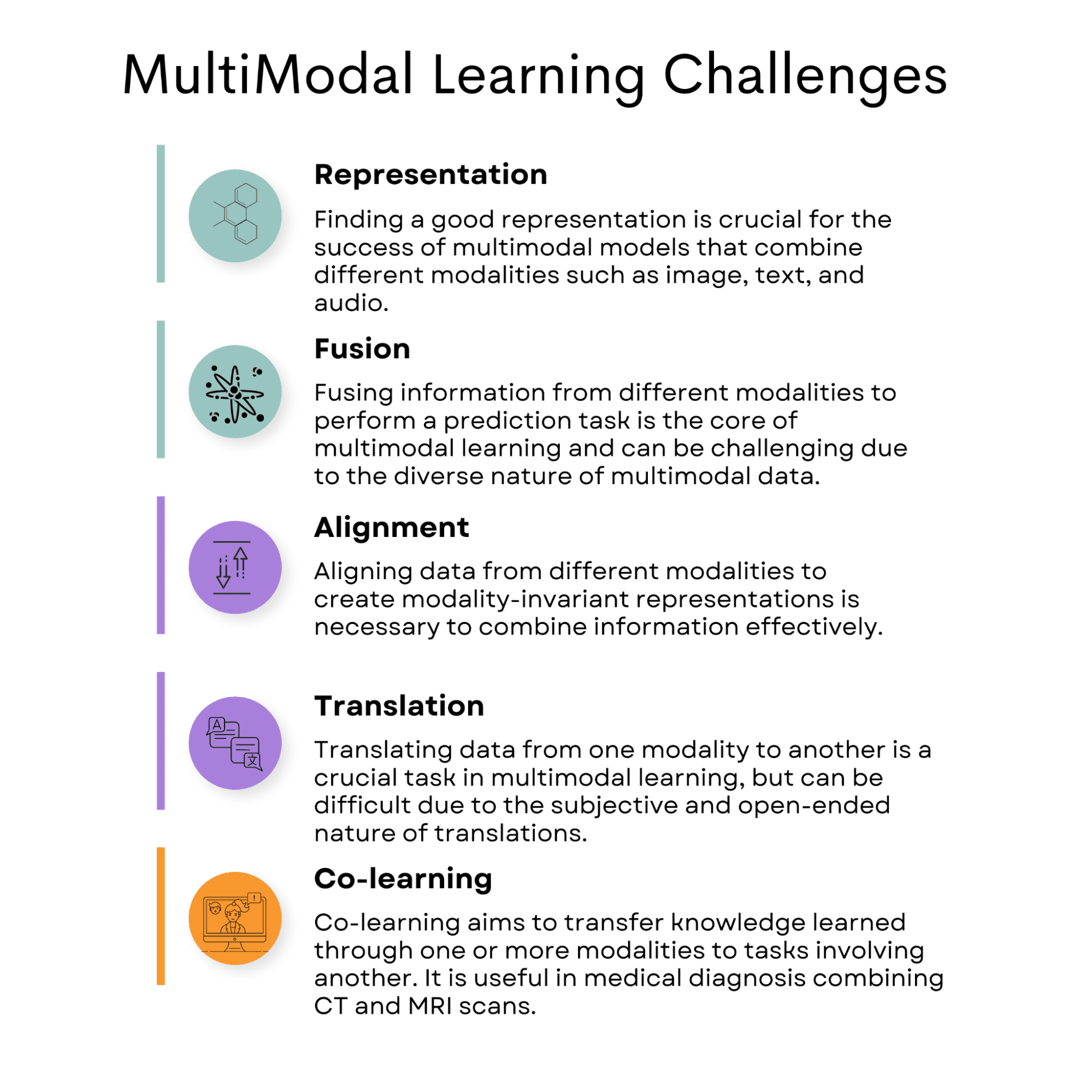
Image by Author
Representation
Multimodal data can come in different modalities, such as text and audio. Combining them in a way that preserves their individual characteristics while still capturing their relationships can be challenging.
This can lead to issues such as the model failing to generalize well, being biased towards one modality, or not effectively capturing the joint information.
To solve representation problems in multimodal learning, several strategies can be employed:
Joint representation: As mentioned earlier, this approach involves encoding both modalities into a shared high-dimensional space. Techniques like deep learning-based fusion methods can be used to learn optimal joint representations.
Coordinated representation: Instead of fusing the modalities directly, this approach maintains separate encodings for each modality but ensures that their representations are related and convey the same meaning. Alignment or attention mechanisms can be used to achieve this coordination.
Image-Caption Pairs
The MS COCO dataset is widely used in computer vision and natural language processing research, containing many images with objects in various contexts, along with multiple textual captions describing the content of the images.
When working with the MS COCO dataset, two main strategies for handling representation challenges are joint representation and coordinated representation.
Joint representation: By combining the information from both modalities, the model can understand their combined meaning. For instance, you can use a deep learning model with layers designed to process and merge features from image and text data. This results in a joint representation that captures the relationship between the image and caption.
Coordinated representation: In this approach, the image and caption are encoded separately, but their representations are related and convey the same meaning. Instead of directly fusing the modalities, the model maintains separate encodings for each modality while ensuring they are meaningfully associated.
Both joint and coordinated representation strategies can be employed when working with the MS COCO dataset to effectively handle the challenges of multimodal learning and create models that can process and understand the relationships between visual and textual information.
Fusion
Fusion is a technique used in multimodal learning to combine information from different data modalities, such as text, images, and audio, to create a more comprehensive understanding of a particular situation or context. The fusion process helps models make better predictions and decisions based on the combined information instead of relying on a single modality.
One challenge in multimodal learning is determining the best way to fuse the different modalities. Different fusion techniques may be more effective than others for specific tasks or situations, and finding the right one can be difficult.
Movie Rating

Image by Author
A real-life example of fusion in multimodal learning is a movie recommendation system. In this case, the system might use text data (movie descriptions, reviews, or user profiles), audio data (soundtracks, dialogue), and visual data (movie posters, video clips) to generate personalized recommendations for users.
The fusion process combines these different sources of information to create a more accurate and meaningful understanding of the user's preferences and interests, leading to better movie suggestions.
One real-life dataset suitable for developing a movie recommendation system with fusion is the MovieLens dataset. MovieLens is a collection of movie ratings and metadata, including user-generated tags, collected by the GroupLens Research project at the University of Minnesota. The dataset contains information about movies, such as titles, genres, user ratings, and user profiles.
To create a multimodal movie recommendation system using the MovieLens dataset, you could combine the textual information (movie titles, genres, and tags) with additional visual data (movie posters) and audio data (soundtracks, dialogue). You can obtain movie posters and audio data from other sources, such as IMDB or TMDB.
How Fusion Might Be a Challenge?
Fusion might be challenging when applying multimodal learning to this dataset because you need to determine the most effective way to combine the different modalities.
For example, you need to find the right balance between the importance of textual data (genres, tags), visual data (posters), and audio data (soundtracks, dialogue) for the recommendation task.
Additionally, some movies may have missing or incomplete data, such as lacking posters or audio samples.
In this case, the recommendation system should be robust enough to handle missing data and still provide accurate recommendations based on the available information.
In summary, using the MovieLens dataset, along with additional visual and audio data, you can develop a multimodal movie recommendation system that leverages fusion techniques.
However, challenges may arise when determining the most effective fusion method and handling missing or incomplete data.
Alignment
Alignment is a crucial task in applications such as audio-visual speech recognition. In this task, audio and visual modalities must be aligned to recognize speech accurately.
Researchers have used alignment methods such as the hidden Markov model and dynamic time warping to achieve this synchronization.
For example, the hidden Markov model can be used to model the relationship between the audio and visual modalities and to estimate the alignment between the audio waveform and the video frames. Dynamic time warping can be used to align the data sequences by stretching or compressing them in time so that they match more closely.
Audio-Visual Speech Recognition

Image by Author
By aligning the audio and visual data in the GRID Corpus dataset, researchers can create coordinated representations that capture the relationships between the modalities and then use these representations to recognize speech accurately using both modalities.
The GRID Corpus dataset contains audio-visual recordings of speakers producing sentences in English. Each recording includes the audio waveform and the video of the speaker's face, which captures the movement of the lips and other facial features. The dataset is widely used for research in audio-visual speech recognition, where the goal is to recognize speech accurately using audio and visual modalities.
Translation
The translation is a common multimodal challenge where different modalities of data, such as text and images, must be aligned to create a coherent representation. One example of such a challenge is the task of image captioning, where an image needs to be described in natural language.
In this task, a model needs to be able to recognize not only the objects and context in an image but also generate a natural language description that accurately conveys the meaning of the image.
This requires aligning the visual and textual modalities to create coordinated representations that capture the relationships between them.
Dall-E
An oil painting of pandas meditating in Tibet

Reference: Dall-E
One recent example of a model that can perform multimodal translation is DALL-E2. DALL-E2 is a neural network model developed by OpenAI that can generate high-quality images from textual descriptions. It can also generate textual descriptions from images, effectively translating between the visual and textual modalities.
DALL-E2 achieves this by learning a joint representation space that captures the relationships between the visual and textual modalities.
The model is trained on a large dataset of the image-caption pairs and learns to associate images with their corresponding captions. It can then generate images from textual descriptions by sampling from the learned representation space and generate textual descriptions from images by decoding the learned representation.
Overall, multimodal translation is a significant challenge that requires aligning different modalities of data to create coordinated representations. Models like DALL-E2 can perform this task by learning joint representation spaces that capture the relationships between the visual and textual modalities and can be applied to tasks such as image captioning and visual question answering.
Co-learning
Multimodal co-learning aims to transfer knowledge learned through one or more modalities to tasks involving another.
Co-learning is especially important in low-resource target tasks, entirely/partly missing or noisy modalities.
However, finding effective methods to transfer knowledge from one modality to another while retaining the semantic meaning is a significant challenge in multimodal learning.
In medical diagnosis, different medical imaging modalities, such as CT scans and MRI scans, provide complementary information for a diagnosis. Multimodal co-learning can be used to combine these modalities to improve the accuracy of the diagnosis.
Multimodal Tumor Segmentation
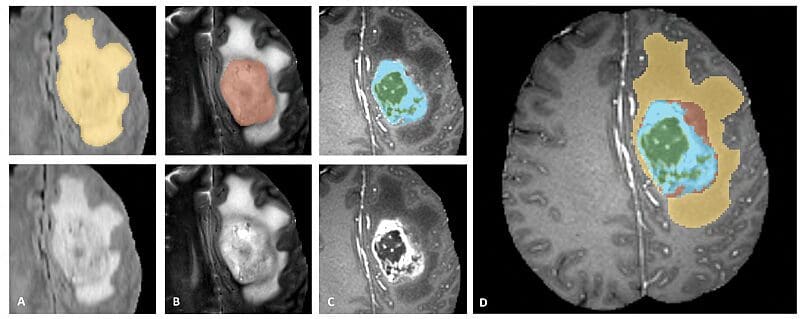
Source: https://www.med.upenn.edu/sbia/brats2018.html
For instance, in the case of brain tumors, MRI scans provide high-resolution images of soft tissues, while CT scans provide detailed images of the bone structure. Combining these modalities can provide a complete picture of the patient's condition and inform treatment decisions.
A dataset that includes MRI and CT scans of brain tumors for use in multimodal co-learning is the multimodal Brain Tumor Segmentation (BraTS) dataset. This dataset includes MRI and CT scans of brain tumors and annotations for segmentation of the tumor regions.
To implement co-learning with the MRI and CT scans of brain tumors, we need to develop an approach that combines the information from both modalities in a way that improves the accuracy of the diagnosis. One possible approach is to use a multimodal deep learning model trained on MRI and CT scans.
Popular Applications of Multimodal Learning
We will mention several other applications of multimodal learning, like speech recognition and autonomous cars.
Speech Recognition

Image by Author
Multimodal learning can improve speech recognition accuracy by combining audio and visual data.
For instance, a multimodal model can analyze both the audio signal of speech and corresponding lip movements to improve speech recognition accuracy. By combining audio and visual modalities, multimodal models can reduce the effects of noise and variability in speech signals, leading to improved speech recognition performance.

Source: CMU-MOSEI Dataset
One example of a multimodal dataset that can be used for speech recognition is the CMU-MOSEI dataset. This dataset contains 23,500 sentences pronounced by 1,000 Youtube speakers and includes both audio and visual data of the speakers.
The dataset can be used to develop multimodal models for emotion recognition, sentiment analysis, and speaker identification.
By combining the audio signal of speech with the visual characteristics of the speaker, multimodal models can improve the accuracy of speech recognition and other related tasks.
Autonomous Car
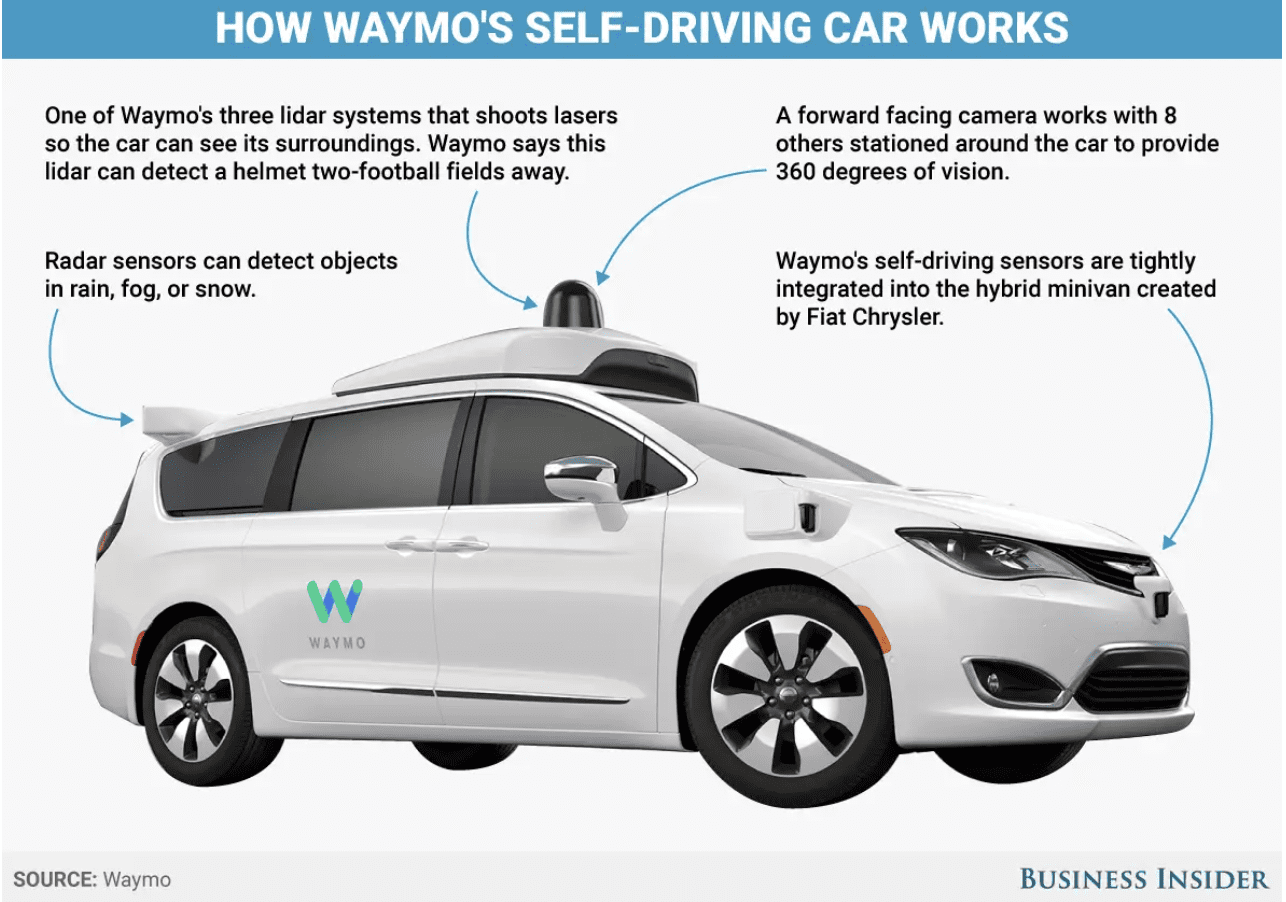
Source: Waymo; Business Insider
Multimodal learning can be used to enhance the capabilities of robots by integrating information from multiple sensors.
For instance, it is essential in developing self-driving cars, which rely on information from multiple sensors such as cameras, lidar, and radar to navigate and make decisions.
Multimodal learning can help to integrate information from these sensors, allowing the car to perceive and react to its environment more accurately and efficiently.
One example of a dataset for self-driving cars is the Waymo Open Dataset, which includes high-resolution sensor data from Waymo's self-driving cars, along with labels for objects such as vehicles, pedestrians, and cyclists. Waymo is Google’s self-driving car company.
The dataset can be used to develop and evaluate multimodal models for various tasks related to self-driving cars, such as object detection, tracking, and predictions.
Voice Recording Analysis

Image by Author
The Voice Recordings Analysis project came up during the interviews for the data science positions at Sandvik. It is an excellent example of a multimodal learning application, as it seeks to predict a person's gender based on vocal features derived from audio data.
In this scenario, the problem involves analyzing and processing information from two distinct modalities: audio signals and textual features. These modalities contribute valuable information that can enhance the accuracy and effectiveness of the predictive model.
Expanding on the multimodal nature of this project:
Audio Signals

Image by Author
The primary data source in this project is the audio recordings of the English-speaking male and female voices. These audio signals contain rich and complex information about the speaker's vocal characteristics. By extracting relevant features from these audio signals, such as pitch, frequency, and spectral entropy, the model can identify patterns and trends that relate to gender-specific vocal properties.
Textual Features

Image by Author
Accompanying each audio recording is a text file that provides crucial information about the sample, such as the speaker's gender, the language spoken, and the phrase uttered by the person. This text file not only offers the ground truth (gender labels) for training and evaluating the machine learning models but can also be used to create additional features in combination with the audio data. By leveraging the information in the text file, the model can better understand the context and content of each audio sample, potentially improving its overall predictive performance.
So, the Voice Recordings Analysis project exemplifies a multimodal learning application by leveraging data from multiple modalities, audio signals, and textual features to predict a person's gender using extracted vocal characteristics.
This approach highlights the importance of considering different data types when developing machine learning models, as it can help uncover hidden patterns and relationships that may not be apparent when analyzing each modality in isolation.
Conclusion
In summary, multimodal learning has become a potent tool for integrating diverse data to enhance the power of the precision of machine learning algorithms. Combining different data types, including text, audio, and visual information, can yield more robust and accurate predictions. This is particularly true in speech recognition, text and image fusion, and the autonomous car industry.
Yet, multimodal learning does come with several challenges, such as those related to representation, fusion, alignment, translation, and co-learning. This necessitates careful consideration and attention.
Nevertheless, as machine learning techniques and computing power continue to evolve, we can anticipate the emergence of even more advanced multimodal in the years to come.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Connect with him on Twitter: StrataScratch or LinkedIn.