Machine Learning Key Terms, Explained
Read this overview of 12 important machine learning concepts, presented in a no frills, straightforward definition style.

Photo by Markus Winkler on Unsplash
There are many posts on KDnuggets covering the explanation of key terms and concepts in the areas of Data Science, Machine Learning, Deep Learning, Big Data, etc. In fact, it's one of the tasks that KDnuggets takes quite seriously: introducing and clarifying concepts in the minds of new and seasoned practitioners alike. In many of these posts, concepts and terminology are often expounded upon and fit into The Big Picture, sometimes miring down the key concept in exchange for defining some greater notion.
This is the first in a series of such posts on KDnuggets which will offer concise explanations of a related set of terms (machine learning, in this case), specifically taking a no-frills approach for those looking to isolate and define. After some thought, it was determined that these foundational-yet-informative types of posts have not been given enough exposure in the past, with future iterations likely to include:
- Deep Learning
- Natural Language Processing
- Databases
- Other interesting topics we can think of :)
So, let's start with a look at machine learning and related topics.
1. Machine Learning
According to Mitchell, machine learning is "concerned with the question of how to construct computer programs that automatically improve with experience." Machine learning is interdisciplinary in nature, and employs techniques from the fields of computer science, statistics, and artificial intelligence, among others. The main artefacts of machine learning research are algorithms which facilitate this automatic improvement from experience, algorithms which can be applied in such diverse fields as computer vision, artificial intelligence, and data mining.
2. Classification
Classification is concerned with building models that separate data into distinct classes. These models are built by inputting a set of training data for which the classes are pre-labelled in order for the algorithm to learn from. The model is then used by inputting a different dataset for which the classes are withheld, allowing the model to predict their class membership based on what it has learned from the training set. Well-known classification schemes include decision trees and support vector machines. As this type of algorithm requires explicit class labelling, classification is a form of supervised learning.
3. Regression
Regression is very closely related to classification. While classification is concerned with the prediction of discrete classes, regression is applied when the "class" to be predicted is made up of continuous numerical values. Linear regression is an example of a regression technique.
4. Clustering
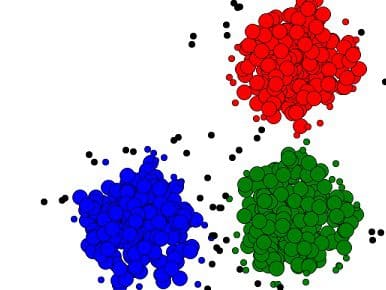
Clustering is used for analyzing data which does not include pre-labeled classes, or even a class attribute at all. Data instances are grouped together using the concept of "maximizing the intraclass similarity and minimizing the interclass similarity," as concisely described by Han, Kamber & Pei. This translates to the clustering algorithm identifying and grouping instances which are very similar, as opposed to ungrouped instances which are much less-similar to one another. k-means clustering is perhaps the most well-known example of a clustering algorithm. As clustering does not require the pre-labeling of instance classes, it is a form of unsupervised learning, meaning that it learns by observation as opposed to learning by example.
5. Association
Association is most easily explained by introducing market basket analysis, a typical task for which it is well-known. Market basket analysis attempts to identify associations between the various items that have been chosen by a particular shopper and placed in their market basket, be it real or virtual, and assigns support and confidence measures for comparison. The value of this lies in cross-marketing and customer behavior analysis. Association is a generalization of market basket analysis, and is similar to classification except that any attribute can be predicted in association. Apriori enjoys success as the most well-known example of an association algorithm. Association is another example of unsupervised learning.
6. Decision Trees
Decision trees are top-down, recursive, divide-and-conquer classifiers. Decision trees are generally composed of 2 main tasks: tree induction and tree pruning. Tree induction is the task of taking a set of pre-classified instances as input, deciding which attributes are best to split on, splitting the dataset, and recursing on the resulting split datasets until all training instances are categorized. While building our tree, the goal is to split on the attributes which create the purest child nodes possible, which would keep to a minimum the number of splits that would need to be made in order to classify all instances in our dataset. This purity is measured by the concept of information, which relates to how much would need to be known about a previously-unseen instance in order for it to be properly classified.
A completed decision tree model can be overly-complex, contain unnecessary structure, and be difficult to interpret. Tree pruning is the process of removing the unnecessary structure from a decision tree in order to make it more efficient, more easily-readable for humans, and more accurate as well. This increased accuracy is due to pruning’s ability to reduce overfitting.
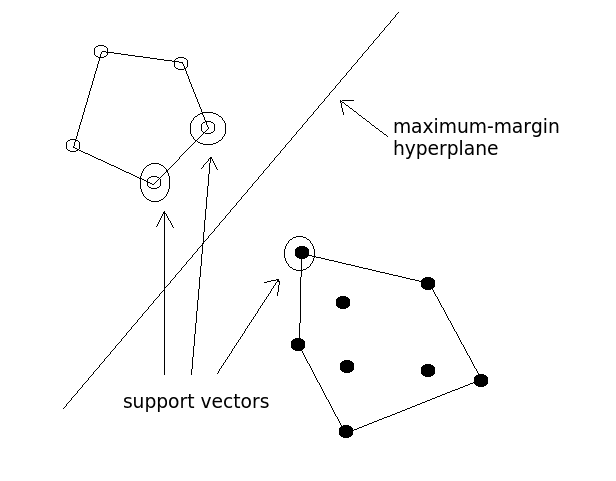
7. Support Vector Machines
SVMs are able to classify both linear and nonlinear data. SMVs work by transforming the training dataset into a higher dimension, a higher dimension which is then inspected for the optimal separation boundary, or boundaries, between classes. In SVMs, these boundaries are referred to as hyperplanes, which are identified by locating support vectors, or the instances that most essentially define classes, and their margins, which are the lines parallel to the hyperplane defined by the shortest distance between a hyperplane and its support vectors.
The grand idea with SVMs is that, with a high enough number of dimensions, a hyperplane separating 2 classes can always be found, thereby delineating dataset member classes. When repeated a sufficient number of times, enough hyperplanes can be generated to separate all classes in n-dimension space.
8. Neural Networks
Neural networks are algorithms inspired by the biological brain, although the extent to which they capture actual brain functionality is highly controversial, and claims that they model the biological brain are patently false. Neural networks are made up of numerous interconnected conceptualized artificial neurons, which pass data between themselves, and which have associated weights which are tuned based upon the newtork's "experience." Neurons have activation thresholds which, if met by a combination of their associated weights and data passed to them, are fired; combinations of fired neurons result in "learning."
9. Deep Learning
Deep learning is a relatively new term, although it has existed prior to the dramatic uptick in online searches of late. Enjoying a surge in research and industry, due mainly to its incredible successes in a number of different areas, deep learning is the process of applying deep neural network technologies - that is, neural network architectures with multiple hidden layers of neurons - to solve problems. Deep learning is a process, like data mining, which employs deep neural network architectures, which are particular types of machine learning algorithms.
10. Reinforcement Learning
Bishop best describes reinforcement learning in a single concise sentence: "Reinforcement learning is concerned with the problem of finding suitable actions to take in a given situation in order to maximize a reward." Reinforcement algorithms are not given explicit goals; instead, they are forced to learn these optimal goals by trial and error. Think of the classic Mario Bros. video game; reinforcement learning algorithms would, by trial and error, determine that certain movements and button pushes would advance the player's standing in the game, and trial and error would aim to result in an optimal state of game play.
11. Cross-validation
Cross-validation is a deterministic method for model building, achieved by leaving out one of k segments, or folds, of a dataset, training on all k-1 segments, and using the remaining kth segment for testing; this process is then repeated k times, with the individual prediction error results being combined and averaged in a single, integrated model. This provides variability, with the goal of producing the most accurate predictive models possible.
12. Bayesian
When referring to probability, there are 2 major schools of thought: classical, or frequentist, probability interpretation views probabilities in terms of the frequencies of random events. In somewhat of a contrast, the Bayesian view of probability aims to quantify uncertainty, and updates a given probability as additional evidence is available. If these probabilities are extended to truth values, and are assigned to hypotheses, we then have "learning" to varying degrees of certainty.
Matthew Mayo (@mattmayo13) is a Data Scientist and the Editor-in-Chief of KDnuggets, the seminal online Data Science and Machine Learning resource. His interests lie in natural language processing, algorithm design and optimization, unsupervised learning, neural networks, and automated approaches to machine learning. Matthew holds a Master's degree in computer science and a graduate diploma in data mining. He can be reached at editor1 at kdnuggets[dot]com.