How to squeeze the most from your training data
In many cases, getting enough well-labelled training data is a huge hurdle for developing accurate prediction systems. Here is an innovative approach which uses SVM to get the most from training data.
By David Bishop, CTO Love the Sales.
In many cases, the acquisition of well-labelled training data is a huge hurdle for developing accurate prediction systems with supervised learning. At Love the Sales, we had the requirement to apply classification to the textual metadata of 2 million products (mostly fashion and homewares) into 1,000+ different categories – represented in a hierarchy.
In order to achieve this, we have architected a hierarchical tree of chained 2-class linear (Positive vs Negative) Support Vector Machines (LibSVM), each responsible for binary document classification of each hierarchical class.
Data structures
A key learning, is that the way in which these SVM’s are structured can actually have a significant impact on how much training data has to be applied, for example, a naive approach would have been as follows:
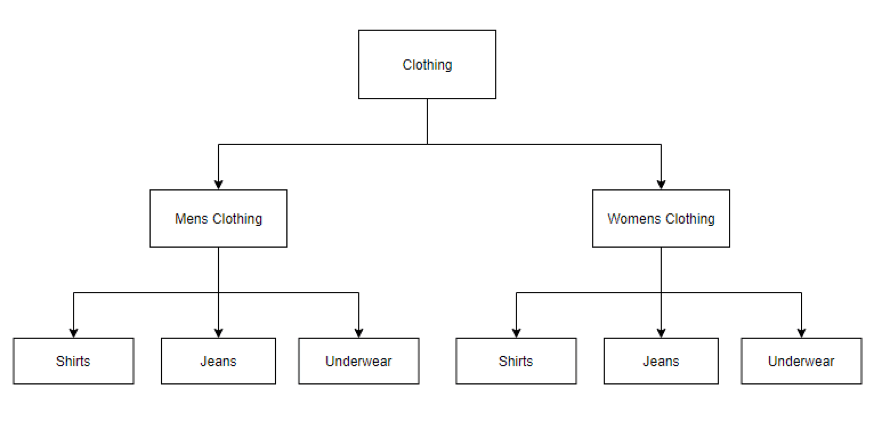
This approach requires that for every additional sub-category, two new SVM’s be trained – for example, the addition of a new class for ‘Swimwear’ would require an additional SVM under Men’s and Women’s – not to mention the potential complexity of adding a ‘Unisex’ class at the top level. Overall, deep hierarchical structures can be too rigid to work with.
We were able to avoid a great deal of labelling& training work, by flattening our data structures into many sub-trees like so:
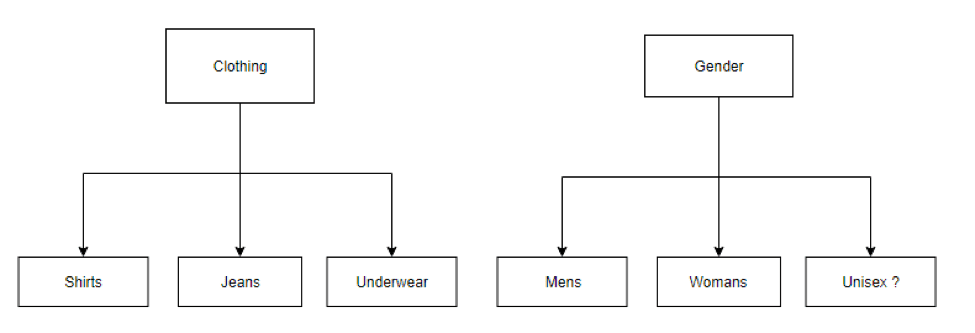
By decoupling our classification structure from the final hierarchy, it is possible to generate the final classification by traversing the SVM hierarchy with each document, and interrogating the results with simple set-based logic such as:
Mens Slim-fit jeans = (Mens and Jeans and Slim Fit) and not Womens
This approach vastly reduces the number of SVM’s required to classify documents, as the resultant sets can be intersected to represent the final classification.

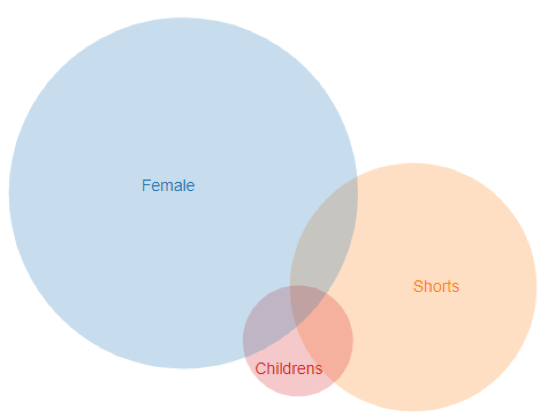
It should also now be evident that adding new classes opens up an exponentially increasing number of final categories. For example – adding a top-level ‘Children’s’ class – would immediately allow the creation of an entire dimension of new Children’s categories (children’s jeans, shirts, underwear, etc), with minimal additional training data (Only one additional SVM):
Data reuse
Because of the structure we chose, one key insight that we were able to leverage, was that of re-using training data, via linked data relationships. Linking data enabled us to re-use our training data by an overall factor of 9x – thus massively reducing the cost and increasing the accuracy of predictions.
For each individual class, we obviously want as many training-data examples as possible, covering both possible outcomes. Even though we built some excellent internal tooling to help with manually labelling training data in bulk – labelling thousands of examples of each kind of product can be laborious, costly and error-prone. We determined the best way to circumvent these issues was to attempt to reuse as much training data as we could, across classes.
For example, given some basic domain knowledge of the categories – we know for certain that ‘Washing machines’ can never be ‘Carpet cleaners’

By adding the ability to link ‘Exclude data’, we can heavily bolster the amount ‘Negative’ training examples for the ‘Washing machines’ SVM by adding to it the ‘Positive’ training data from ‘Carpet cleaners’ SVM. Put more simply, given that we know “Carpet cleaners can never be washing machines” – we may as well re-use that data.
This approach has a nice uptick, in that whenever the need arises to add some additional training data to improve the ‘Carpet Cleaners’ SVM – it inadvertently improves the ‘Washing machines’ class, via linked negative data.
Finally, another chance for reuse, that is apparent when considering a hierarchy, is that the positive training data for any child nodes, is also always positive training data for its parent. For example: ‘Jeans’ are always ‘Clothing’.

This means that for every positive example of training data added to the ‘Jeans’ SVM – an additional positive example is also added to the ‘Clothing’ SVM via the link.
Adding links is far more efficient than manually labelling 1000’s of examples.

When it comes to hierarchical classification systems, decoupling the classification component from the resulting hierarchy, flattening the data structure and enabling the reuse or training data will all be beneficial in gaining as much efficiency as possible. The approaches outlined above have not only helped reduce the amount of training data we needed to label, it has also given us greater flexibility overall.
Reference: LibSVM –https://www.csie.ntu.edu.tw/~cjlin/libsvm/
Bio: David Bishop is CTO at LovetheSales.com – a retail sales aggregator that enables consumers to find and compare every product on sale, from 100s of retailers, to find the best prices on the brands and products they want. Founded in 2013, it is by far the biggest sale in the world, with over 1,000,000 sale items on the site across all of its regions.
Related: