 How I Used Deep Learning To Train A Chatbot To Talk Like Me
How I Used Deep Learning To Train A Chatbot To Talk Like Me
 How I Used Deep Learning To Train A Chatbot To Talk Like Me
How I Used Deep Learning To Train A Chatbot To Talk Like MeIn this post, we’ll be looking at how we can use a deep learning model to train a chatbot on my past social media conversations in hope of getting the chatbot to respond to messages the way that I would.

Introduction
Chatbots are “computer programs which conduct conversation through auditory or textual methods”. Apple’s Siri, Microsoft’s Cortana, Google Assistant, and Amazon’s Alexa are four of the most popular conversational agents today. They can help you get directions, check the scores of sports games, call people in your address book, and can accidently make you order a $170 dollhouse.
These products all have auditory interfaces where the agent converses with you through audio messages. In this post, we’ll be looking more at chatbots that operate solely on the textual front. Facebook has been heavily investing in FB Messenger bots, which allow small businesses and organizations to create bots to help with customer support and frequently asked questions. Chatbots have been around for a decent amount of time (Siri released in 2011), but only recently has deep learning been the go-to approach to the task of creating realistic and effective chatbot interaction.
In this post, we’ll be looking at how we can use a deep learning model to train a chatbot on my past social media conversations in hope of getting the chatbot to respond to messages the way that I would.
Problem Space
From a high level, the job of a chatbot is to be able to determine the best response for any given message that it receives. This “best” response should either (1) answer the sender’s question, (2) give the sender relevant information, (3) ask follow-up questions, or (4) continue the conversation in a realistic way. This is a pretty tall order. The chatbot needs to be able to understand the intentions of the sender’s message, determine what type of response message (a follow-up question, direct response, etc.) is required, and follow correct grammatical and lexical rules while forming the response.
It’s safe to say that modern chatbots have trouble accomplishing all these tasks. For all the progress we have made in the field, we too often get chatbot experiences like this.
"Oh no! Artificial Intelligence is totally going to take over the world! Because deep learning models neurons!" pic.twitter.com/5UEpel4k6H
— Reza Zadeh (@Reza_Zadeh) August 17, 2016
Chatbots are too often not able to understand our intentions, have trouble getting us the correct information, and are sometimes just exasperatingly difficult to deal with. As we’ll see in this post, deep learning is one of the most effective methods in tackling this tough task.
Deep Learning Approach
Chatbots that use deep learning are almost all using some variant of a sequence to sequence (Seq2Seq) model. In 2014, Ilya Sutskever, Oriol Vinyals, and Quoc Le published the seminal work in this field with a paper called “Sequence to Sequence Learning with Neural Networks”. This paper showed great results in machine translation specifically, but Seq2Seq models have grown to encompass a variety of NLP tasks.

A sequence to sequence model is composed of 2 main components, an encoder RNN and a decoder RNN (If you’re a little shaky on RNNs, check out my previous blog post for a refresher). From a high level, the encoder’s job is to encapsulate the information of the input text into a fixed representation. The decoder’s is to take that representation, and generate a variable length text that best responds to it.
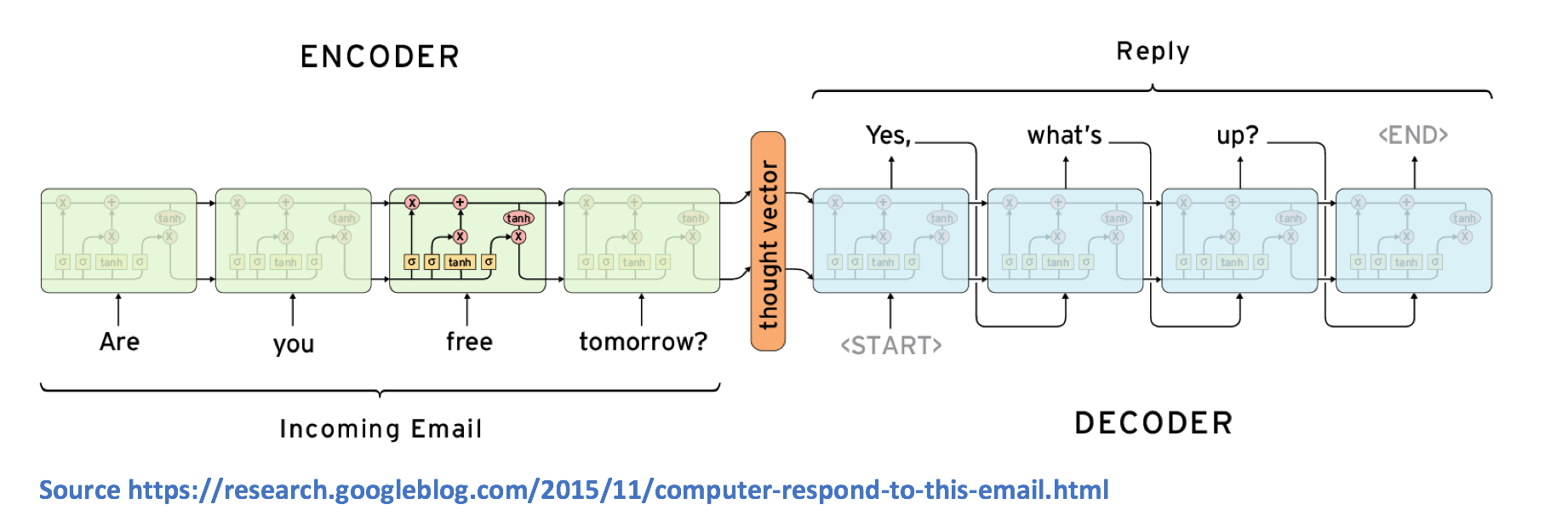
Let’s look at how this works at a more detailed level. As you remember, an RNN contains a number of hidden state vectors, which each represent information from the previous time steps. For example, the hidden state vector at the 3rd time step will be a function of the first 3 words. By this logic, the final hidden state vector of the encoder RNN can be thought of as a pretty accurate representation of the whole input text.
The decoder is another RNN, which takes in the final hidden state vector of the encoder and uses it to predict the words of the output reply. Let's look at the first cell. The cell's job is to take in the vector representation v, and decide which word in its vocabulary is the most appropriate for the output response. Mathematically speaking, this means that we compute probabilities for each of the words in the vocabulary, and choose the argmax of the values.
The 2nd cell will be a function of both the vector representation v, as well as the output of the previous cell. The goal of the LSTM is to estimate the following conditional probability.
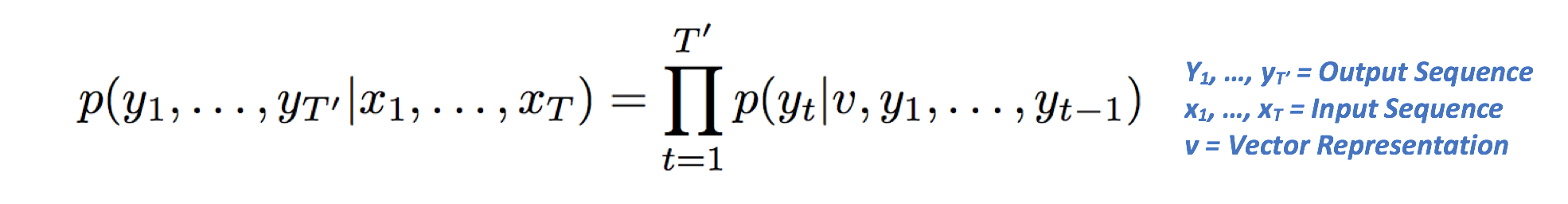
Let's deconstruct what that equation means. The left side refers to the probability of the output sequence, conditioned on the given input sequence. The right side contains the term p(yt|v, y1, …, yt-1), which is a vector of probabilities of all the words, conditioned on the vector representation and the outputs at the previous time steps. The Pi notation is simply the multiplication equivalent of Sigma (or summation). The right hand side can be reduced to p(y1|v) * p(y2|v, y1) * p(y3|v, y1, y2) ... and so on.
Let’s go over a quick example before moving on. Let’s take the input text we saw in the first image. Given the phrase “Are you free tomorrow?”, let’s think about how most people would answer the question. A majority will start with something along the lines of “Yes”, “Yeah”, “No”, etc. After we’re done training our network, the probability p(y1|v) will be a distribution that looks like the following.

The second probability we need to compute, p(y2|v, y1), will be a function of the word this distribution y1 as well as the vector representation v. The result of the Pi (product) operation will give us the most likely sequence of words, which we’ll use as our final response.
One of the most important characteristics of sequence to sequence models is the versatility that it provides. When you think of traditional ML methods (linear regression, SVMs) and deep learning methods like CNNs, these models require a fixed size input, and produce fixed size outputs as well. The lengths of your inputs must be known beforehand. This is a significant limitation to tasks such as machine translation, speech recognition, and question answering. These are tasks where we don't know the size of the input phrase, and we'd also like to be able to generate variable length responses, not just be constrained to one particular output representation. Seq2Seq models allow for that flexibility.
The Seq2Seq model has seen numerous improvements since 2014, and you can head to the ‘Interesting Papers’ section of this post to read more about them.
Dataset Selection
When thinking about applying machine learning to any sort of task, one of the first things we need to do is consider the type of dataset that we would need to train the model. For sequence to sequence models, we need a large number of conversation logs. From a high level, this encoder decoder network needs to be able to understand the type of responses (decoder outputs) that are expected for every query (encoder inputs). Some common datasets are the Cornell Movie Dialog Corpus, the Ubuntu corpus, and Microsoft’s Social Media Conversation Corpus.
While most people train chatbots to answer company specific information or to provide some sort of service, I was more interested in a bit more of a fun application. With this particular post, I wanted to see whether I could use conversation logs from my own life to train a Seq2Seq model that learns to respond to messages the way that I would.
Where's the Data Coming From?

Alright hmm, let’s see how we can do this. We need to create a large dataset of conversations that I’ve had with people online. Over the course of my time on social media, I’ve used Facebook, Google Hangouts, SMS, LinkedIn, Twitter, Tinder, and Slack to stay in touch with people.
- Facebook: This is where the bulk of the training data will come from. Facebook has a cool feature that allows you to download a copy of all of your Facebook data. This download will contain all your messages, your photos, and your all-caps, cringe filled statuses that you wrote as a middle schooler.
- Google Hangouts: I definitely used this a lot with a close set of friends during high school. You can extract of your chat data by following the instructions on this fantastic blog post.
- SMS/Texting: Pretty sure there is a way to get an archive of all prior chats (SMS Backup+ is a good app), but I rarely use text anyway, so don’t think it’ll be worth the effort.
- LinkedIn: LinkedIn does provide a tool to get an archive of your data here.
- Twitter: Not enough private messages for this to be useful.
- Tinder: Ummm, yeah let’s just say that these conversations are not dataset worthy .
- Slack: Just recently started using this, and only having a couple private messages, so just planning to manually copy over the convos.