Hiring Data Scientists: What to look for?
Know key characteristics of what makes up a good data scientist based upon the three authors’ consulting and research experience, having collaborated with many companies world-wide on the topics of big data and analytics.
Guest post by Bart Baesens, Richard Weber, Cristián Bravo, Sep 9, 2014
 Big data and analytics are all around these days. IBM projects that every day we generate 2.5 quintillion bytes of data. This means that 90% of the data in the world has been created in the last two years. Gartner projects that by 2015, 85% of Fortune 500 organizations will be unable to exploit big data for competitive advantage and about 4.4 million jobs will be created around big data.
Big data and analytics are all around these days. IBM projects that every day we generate 2.5 quintillion bytes of data. This means that 90% of the data in the world has been created in the last two years. Gartner projects that by 2015, 85% of Fortune 500 organizations will be unable to exploit big data for competitive advantage and about 4.4 million jobs will be created around big data.
Although these estimates should not be interpreted in absolute sense, they are a strong indication of the ubiquity of big data and the need for analytical skills and resources, because as the data piles up, managing and analyzing these data resources in the best way become critical success factors in creating competitive advantage and strategic leverage. To address these challenges, companies are hiring data scientists. However, in the industry, there are strong misconceptions and disagreements about what constitutes a good data scientist. Here are the key characteristics of what makes up a good data scientist:
A data scientist should be a good programmer!
 As per definition, data scientists work with data. This involves plenty of activities such as sampling and pre-processing of data, model estimation and post-processing (e.g. sensitivity analysis, model deployment, back-testing, model validation). Although many user-friendly software tools are on the market nowadays to automate this, every analytical exercise requires tailored steps to tackle the specificities of a particular business problem. In order to successfully perform these steps, programming needs to be done. Hence, a good data scientist should possess sound programming skills in e.g. R, Python, SAS … The programming language itself is not that important as such, as long as he/she is familiar with the basic concepts of programming and knows how to use these to automate repetitive tasks or perform specific routines.
As per definition, data scientists work with data. This involves plenty of activities such as sampling and pre-processing of data, model estimation and post-processing (e.g. sensitivity analysis, model deployment, back-testing, model validation). Although many user-friendly software tools are on the market nowadays to automate this, every analytical exercise requires tailored steps to tackle the specificities of a particular business problem. In order to successfully perform these steps, programming needs to be done. Hence, a good data scientist should possess sound programming skills in e.g. R, Python, SAS … The programming language itself is not that important as such, as long as he/she is familiar with the basic concepts of programming and knows how to use these to automate repetitive tasks or perform specific routines.
A data scientist should have solid quantitative skills!
 Obviously, a data scientist should have a thorough background in statistics, machine learning and/or data mining. The distinction between these various disciplines is getting more and more blurred and is actually not that relevant. They all provide a set of quantitative techniques to analyze data and find business relevant patterns within a particular context (e.g. risk management, fraud detection, marketing analytics …). The data scientist should be aware of which technique can be applied when and how. He/she should not focus too much on the underlying mathematical (e.g. optimization) details but rather have a good understanding of what analytical problem a technique solves, and how its results should be interpreted. In this, training of engineers in computer science and business/industrial engineering should aim at an integrated, multidisciplinary view, with recent grads formed in both the use of the techniques, and with the business acumen necessary to bring new endeavors to fruition.
Obviously, a data scientist should have a thorough background in statistics, machine learning and/or data mining. The distinction between these various disciplines is getting more and more blurred and is actually not that relevant. They all provide a set of quantitative techniques to analyze data and find business relevant patterns within a particular context (e.g. risk management, fraud detection, marketing analytics …). The data scientist should be aware of which technique can be applied when and how. He/she should not focus too much on the underlying mathematical (e.g. optimization) details but rather have a good understanding of what analytical problem a technique solves, and how its results should be interpreted. In this, training of engineers in computer science and business/industrial engineering should aim at an integrated, multidisciplinary view, with recent grads formed in both the use of the techniques, and with the business acumen necessary to bring new endeavors to fruition.
Also important in this context is to spend enough time validating the analytical results obtained so as to avoid situations often referred to as data massage and/or data torture whereby data is (intentionally) misrepresented and/or too much focus is spent discussing spurious correlations. When selecting the optimal quantitative technique, the data scientist should take into account the specificities of the business problem. Typical requirements for analytical models are: action-ability (to what extent is the analytical model solving the business problem?), performance (what is the statistical performance of the analytical model?), interpret-ability (can the analytical model be easily explained to decision makers?), operational efficiency (how much efforts are needed to setup, evaluate and monitor the analytical model?), regulatory compliance (is the model in line with regulation?) and economical cost (what is the cost of setting up, running and maintaining the model?). Based upon a combination of these requirements, the data scientist should be capable of selecting the best analytical technique to solve the business problem.
A data scientist should excel in communication and visualization skills!
Like it or not, but analytics is a technical exercise. At this moment, there is a huge gap between the analytical models and the business users. To bridge this gap, communication and visualization facilities are key! Hence, a data scientist should know how to represent analytical models and their accompanying statistics and reports in user-friendly ways using e.g. traffic light approaches, OLAP (on-line analytical processing) facilities, If-then business rules, … He/she should be capable of communicating the right amount of information without getting lost into complex (e.g. statistical) details which will inhibit a model’s successful deployment. By doing so, business users will better understand the characteristics and behavior in their (big) data which will improve their attitude towards and acceptance of the resulting analytical models. Educational institutions must learn to balance, since it is known that many academic degrees prepare students that are skewed to either too much analytical or too much practical knowledge.
visualization facilities are key! Hence, a data scientist should know how to represent analytical models and their accompanying statistics and reports in user-friendly ways using e.g. traffic light approaches, OLAP (on-line analytical processing) facilities, If-then business rules, … He/she should be capable of communicating the right amount of information without getting lost into complex (e.g. statistical) details which will inhibit a model’s successful deployment. By doing so, business users will better understand the characteristics and behavior in their (big) data which will improve their attitude towards and acceptance of the resulting analytical models. Educational institutions must learn to balance, since it is known that many academic degrees prepare students that are skewed to either too much analytical or too much practical knowledge.
A data scientist should have a solid business understanding!
 While this might be obvious, we have witnessed (too) many data science projects that failed since the respective analyst did not understand the business problem at hand. By “business” we refer to the respective application area, which could be e.g. churn prediction or credit scoring in a real business context or astronomy or medicine if the respective data to be analyzed stem from such areas.
While this might be obvious, we have witnessed (too) many data science projects that failed since the respective analyst did not understand the business problem at hand. By “business” we refer to the respective application area, which could be e.g. churn prediction or credit scoring in a real business context or astronomy or medicine if the respective data to be analyzed stem from such areas.
A data scientist should be creative!
 A data scientist needs creativity on at least two levels. First, on a technical level, it is important to be creative with regard to feature selection, data transformation and cleaning. These steps of the standard knowledge discovery process have to be adapted to each particular application and often the “right guess” could make a big difference. Second, big data and analytics is a fast evolving field! New problems, technologies and corresponding challenges pop up on an ongoing basis. It is important that a data scientist keeps up with these new technologies and has enough creativity to see how they can create new business opportunities.
A data scientist needs creativity on at least two levels. First, on a technical level, it is important to be creative with regard to feature selection, data transformation and cleaning. These steps of the standard knowledge discovery process have to be adapted to each particular application and often the “right guess” could make a big difference. Second, big data and analytics is a fast evolving field! New problems, technologies and corresponding challenges pop up on an ongoing basis. It is important that a data scientist keeps up with these new technologies and has enough creativity to see how they can create new business opportunities.
Conclusion:
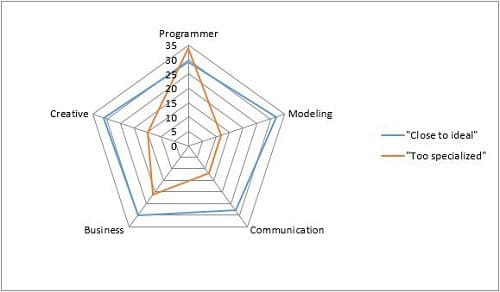
We have provided a brief overview of characteristics to be looked for when hiring data scientists. To summarize, given the multidisciplinary nature of big data and analytics, a data scientist should possess a mix of skills: programming, quantitative modelling, communication and visualization, business understanding, and creativity! The figure below shows how to represent such a profile.
Figure: Profiles of a data scientist.
Authors:
Dr. Bart Baesens is a professor at KU Leuven (Belgium), and a lecturer at the University of Southampton (United Kingdom). He has done extensive research on Big Data and Analytics. His findings have been published in well-known international journals and presented at international top conferences. He is also author of the books: Credit Risk Management: Basic Concepts, and Analytics in a Big Data World published by Wiley in 2014. His research is summarized at www.dataminingapps.com. He also regularly tutors, advises and provides consulting support to international firms with respect to their analytics strategy.
Richard Weber is professor at Universidad de Chile (Chile) and teaches Data Mining and Operations Management at the undergraduate and graduate level as well as for executive education. His research interests are data mining, the respective methodological developments, and applications in areas such as finance, marketing, and security-related topics. The results of his work have been published in leading scientific journals.
Cristián Bravo is an Instructor Professor at the University of Talca, Chile, currently on leave as a Visiting Research Fellow at KU Leuven (Belgium). He is an Industrial Engineer, holds a Master in Operations Research, and a PhD in Engineering Systems from University of Chile. He has served as the Research Director of the Finance Center, U. Chile, and has published in several Data Mining and Operations Research journals. His research interests cover Credit Risk, especially applied to Micro-Entrepreneurs, and Data Mining models in this area.
Related:
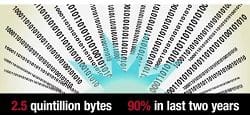 Big data and analytics are all around these days. IBM projects that every day we generate 2.5 quintillion bytes of data. This means that 90% of the data in the world has been created in the last two years. Gartner projects that by 2015, 85% of Fortune 500 organizations will be unable to exploit big data for competitive advantage and about 4.4 million jobs will be created around big data.
Big data and analytics are all around these days. IBM projects that every day we generate 2.5 quintillion bytes of data. This means that 90% of the data in the world has been created in the last two years. Gartner projects that by 2015, 85% of Fortune 500 organizations will be unable to exploit big data for competitive advantage and about 4.4 million jobs will be created around big data.
Although these estimates should not be interpreted in absolute sense, they are a strong indication of the ubiquity of big data and the need for analytical skills and resources, because as the data piles up, managing and analyzing these data resources in the best way become critical success factors in creating competitive advantage and strategic leverage. To address these challenges, companies are hiring data scientists. However, in the industry, there are strong misconceptions and disagreements about what constitutes a good data scientist. Here are the key characteristics of what makes up a good data scientist:
A data scientist should be a good programmer!
 As per definition, data scientists work with data. This involves plenty of activities such as sampling and pre-processing of data, model estimation and post-processing (e.g. sensitivity analysis, model deployment, back-testing, model validation). Although many user-friendly software tools are on the market nowadays to automate this, every analytical exercise requires tailored steps to tackle the specificities of a particular business problem. In order to successfully perform these steps, programming needs to be done. Hence, a good data scientist should possess sound programming skills in e.g. R, Python, SAS … The programming language itself is not that important as such, as long as he/she is familiar with the basic concepts of programming and knows how to use these to automate repetitive tasks or perform specific routines.
As per definition, data scientists work with data. This involves plenty of activities such as sampling and pre-processing of data, model estimation and post-processing (e.g. sensitivity analysis, model deployment, back-testing, model validation). Although many user-friendly software tools are on the market nowadays to automate this, every analytical exercise requires tailored steps to tackle the specificities of a particular business problem. In order to successfully perform these steps, programming needs to be done. Hence, a good data scientist should possess sound programming skills in e.g. R, Python, SAS … The programming language itself is not that important as such, as long as he/she is familiar with the basic concepts of programming and knows how to use these to automate repetitive tasks or perform specific routines.
A data scientist should have solid quantitative skills!
 Obviously, a data scientist should have a thorough background in statistics, machine learning and/or data mining. The distinction between these various disciplines is getting more and more blurred and is actually not that relevant. They all provide a set of quantitative techniques to analyze data and find business relevant patterns within a particular context (e.g. risk management, fraud detection, marketing analytics …). The data scientist should be aware of which technique can be applied when and how. He/she should not focus too much on the underlying mathematical (e.g. optimization) details but rather have a good understanding of what analytical problem a technique solves, and how its results should be interpreted. In this, training of engineers in computer science and business/industrial engineering should aim at an integrated, multidisciplinary view, with recent grads formed in both the use of the techniques, and with the business acumen necessary to bring new endeavors to fruition.
Obviously, a data scientist should have a thorough background in statistics, machine learning and/or data mining. The distinction between these various disciplines is getting more and more blurred and is actually not that relevant. They all provide a set of quantitative techniques to analyze data and find business relevant patterns within a particular context (e.g. risk management, fraud detection, marketing analytics …). The data scientist should be aware of which technique can be applied when and how. He/she should not focus too much on the underlying mathematical (e.g. optimization) details but rather have a good understanding of what analytical problem a technique solves, and how its results should be interpreted. In this, training of engineers in computer science and business/industrial engineering should aim at an integrated, multidisciplinary view, with recent grads formed in both the use of the techniques, and with the business acumen necessary to bring new endeavors to fruition.
Also important in this context is to spend enough time validating the analytical results obtained so as to avoid situations often referred to as data massage and/or data torture whereby data is (intentionally) misrepresented and/or too much focus is spent discussing spurious correlations. When selecting the optimal quantitative technique, the data scientist should take into account the specificities of the business problem. Typical requirements for analytical models are: action-ability (to what extent is the analytical model solving the business problem?), performance (what is the statistical performance of the analytical model?), interpret-ability (can the analytical model be easily explained to decision makers?), operational efficiency (how much efforts are needed to setup, evaluate and monitor the analytical model?), regulatory compliance (is the model in line with regulation?) and economical cost (what is the cost of setting up, running and maintaining the model?). Based upon a combination of these requirements, the data scientist should be capable of selecting the best analytical technique to solve the business problem.
A data scientist should excel in communication and visualization skills!
Like it or not, but analytics is a technical exercise. At this moment, there is a huge gap between the analytical models and the business users. To bridge this gap, communication and
 visualization facilities are key! Hence, a data scientist should know how to represent analytical models and their accompanying statistics and reports in user-friendly ways using e.g. traffic light approaches, OLAP (on-line analytical processing) facilities, If-then business rules, … He/she should be capable of communicating the right amount of information without getting lost into complex (e.g. statistical) details which will inhibit a model’s successful deployment. By doing so, business users will better understand the characteristics and behavior in their (big) data which will improve their attitude towards and acceptance of the resulting analytical models. Educational institutions must learn to balance, since it is known that many academic degrees prepare students that are skewed to either too much analytical or too much practical knowledge.
visualization facilities are key! Hence, a data scientist should know how to represent analytical models and their accompanying statistics and reports in user-friendly ways using e.g. traffic light approaches, OLAP (on-line analytical processing) facilities, If-then business rules, … He/she should be capable of communicating the right amount of information without getting lost into complex (e.g. statistical) details which will inhibit a model’s successful deployment. By doing so, business users will better understand the characteristics and behavior in their (big) data which will improve their attitude towards and acceptance of the resulting analytical models. Educational institutions must learn to balance, since it is known that many academic degrees prepare students that are skewed to either too much analytical or too much practical knowledge.
A data scientist should have a solid business understanding!
 While this might be obvious, we have witnessed (too) many data science projects that failed since the respective analyst did not understand the business problem at hand. By “business” we refer to the respective application area, which could be e.g. churn prediction or credit scoring in a real business context or astronomy or medicine if the respective data to be analyzed stem from such areas.
While this might be obvious, we have witnessed (too) many data science projects that failed since the respective analyst did not understand the business problem at hand. By “business” we refer to the respective application area, which could be e.g. churn prediction or credit scoring in a real business context or astronomy or medicine if the respective data to be analyzed stem from such areas.
A data scientist should be creative!
 A data scientist needs creativity on at least two levels. First, on a technical level, it is important to be creative with regard to feature selection, data transformation and cleaning. These steps of the standard knowledge discovery process have to be adapted to each particular application and often the “right guess” could make a big difference. Second, big data and analytics is a fast evolving field! New problems, technologies and corresponding challenges pop up on an ongoing basis. It is important that a data scientist keeps up with these new technologies and has enough creativity to see how they can create new business opportunities.
A data scientist needs creativity on at least two levels. First, on a technical level, it is important to be creative with regard to feature selection, data transformation and cleaning. These steps of the standard knowledge discovery process have to be adapted to each particular application and often the “right guess” could make a big difference. Second, big data and analytics is a fast evolving field! New problems, technologies and corresponding challenges pop up on an ongoing basis. It is important that a data scientist keeps up with these new technologies and has enough creativity to see how they can create new business opportunities.
Conclusion:
We have provided a brief overview of characteristics to be looked for when hiring data scientists. To summarize, given the multidisciplinary nature of big data and analytics, a data scientist should possess a mix of skills: programming, quantitative modelling, communication and visualization, business understanding, and creativity! The figure below shows how to represent such a profile.
Authors:
Dr. Bart Baesens is a professor at KU Leuven (Belgium), and a lecturer at the University of Southampton (United Kingdom). He has done extensive research on Big Data and Analytics. His findings have been published in well-known international journals and presented at international top conferences. He is also author of the books: Credit Risk Management: Basic Concepts, and Analytics in a Big Data World published by Wiley in 2014. His research is summarized at www.dataminingapps.com. He also regularly tutors, advises and provides consulting support to international firms with respect to their analytics strategy.
Richard Weber is professor at Universidad de Chile (Chile) and teaches Data Mining and Operations Management at the undergraduate and graduate level as well as for executive education. His research interests are data mining, the respective methodological developments, and applications in areas such as finance, marketing, and security-related topics. The results of his work have been published in leading scientific journals.
Cristián Bravo is an Instructor Professor at the University of Talca, Chile, currently on leave as a Visiting Research Fellow at KU Leuven (Belgium). He is an Industrial Engineer, holds a Master in Operations Research, and a PhD in Engineering Systems from University of Chile. He has served as the Research Director of the Finance Center, U. Chile, and has published in several Data Mining and Operations Research journals. His research interests cover Credit Risk, especially applied to Micro-Entrepreneurs, and Data Mining models in this area.
Related: