Interview: Arno Candel, H2O.ai on the Basics of Deep Learning to Get You Started
We discuss how Deep Learning is different from the other methods of Machine Learning, unique characteristics and benefits of Deep Learning, and the key components of H2O architecture.
 Dr. Arno Candel is a Physicist & Hacker at H2O.ai. Prior to that, he was a founding Senior MTS at Skytree where he designed and implemented high-performance machine learning algorithms. He has over a decade of experience in high-performance computing and had access to the world’s largest supercomputers as a Staff Scientist at SLAC National Accelerator Laboratory where he participated in U.S. DOE scientific computing initiatives and collaborated with CERN. Arno has authored dozens of scientific papers and is a sought-after conference speaker.
Dr. Arno Candel is a Physicist & Hacker at H2O.ai. Prior to that, he was a founding Senior MTS at Skytree where he designed and implemented high-performance machine learning algorithms. He has over a decade of experience in high-performance computing and had access to the world’s largest supercomputers as a Staff Scientist at SLAC National Accelerator Laboratory where he participated in U.S. DOE scientific computing initiatives and collaborated with CERN. Arno has authored dozens of scientific papers and is a sought-after conference speaker.
He holds a PhD and Masters summa cum laude in Physics from ETH Zurich. Arno was named 2014 Big Data All-Star by Fortune Magazine.
Here is my interview with him:
Anmol Rajpurohit: Q1. How do you define Deep Learning? How do you differentiate it from the rest of Machine Learning technologies?
 Dr. Arno Candel: Deep Learning methods use a composition of multiple non-linear transformations to model high-level abstractions in data. Multi-layer feed-forward artificial neural networks are some of the oldest and yet most useful such techniques. We are now reaping the benefits of over 60 years of evolution in Deep Learning that began in the late 1950s when the term Machine Learning was coined. Large parts of the growing success of Deep Learning in the past decade can be attributed to Moore’s law and the exponential speedup of computers, but there were also many algorithmic breakthroughs that enabled robust training of deep learners.
Dr. Arno Candel: Deep Learning methods use a composition of multiple non-linear transformations to model high-level abstractions in data. Multi-layer feed-forward artificial neural networks are some of the oldest and yet most useful such techniques. We are now reaping the benefits of over 60 years of evolution in Deep Learning that began in the late 1950s when the term Machine Learning was coined. Large parts of the growing success of Deep Learning in the past decade can be attributed to Moore’s law and the exponential speedup of computers, but there were also many algorithmic breakthroughs that enabled robust training of deep learners.
Compared to more interpretable Machine Learning techniques such as tree-based methods, conventional Deep Learning (using stochastic gradient descent and back-propagation) is a rather “brute-force” method that optimizes lots of coefficients (it is a parametric method) starting from random noise by continuously looking at examples from the training data. It follows the basic idea of “(good) practice makes perfect” (similar to a real brain) without any strong guarantees on the quality of the model.
Today’s typical Deep Learning models have thousands of neurons and learn millions of free parameters (connections between neurons), and yet are not even rivaling the size of a fruit fly’s brain in terms of neurons (~100,000). The most advanced dedicated Deep Learning systems are learning tens of billions of parameters, which is still about 10,000x less than the number of neuron connections in a human brain.
However, even some remarkably small Deep Learning models already outperform humans in many tasks, so the space of Artificial Intelligence is definitely getting more interesting.
AR: Q2. What characteristics enable Deep Learning to deliver such superior results for standard Machine Learning problems? Is there a specific subset of problems for which Deep Learning is more effective than other options?
AC: Deep Learning is really effective at learning non-linear derived features from the raw input features, unlike standard Machine Learning methods such as linear or tree-based methods. For example, if age and income are the two features used to predict spending, then a linear model would greatly benefit from manually splitting age and income ranges into distinct groups; while a tree-based model would learn to automatically dissect the two-dimensional space.
A Deep Learning model builds hierarchies of (hidden) derived non-linear features that get composed to approximate arbitrary functions such as sqrt((age-40)^2+0.3*log(income+1)-4) with much less effort than with other methods. Traditionally, data scientists perform many of these transformations explicitly based on domain knowledge and experience, but Deep Learning has been shown to be extremely effective at coming up with those transformations, often outperforming standard Machine Learning models by a substantial margin.
Deep Learning is also very good at predicting high-cardinality class memberships, such as in image or voice recognition problems, or in predicting the best item to recommend to a user. Another strength of Deep Learning is that it can also be used for unsupervised learning where it just learns the intrinsic structure of the data without making predictions (remember the Google cat?). This is useful in cases where there are no training labels, or for various other use cases such as anomaly detection.

AR: Q3. What are the key components of H2O architecture? What are the unique advantages of using H2O for Deep Learning pursuits?
 AC: H2O is unique in that it’s the #1 Java-based open-source Machine Learning project on GitHub (and we’re in the final phases of a more developer-friendly rewrite). It is built on top of a distributed key-value store that’s based on the world’s fastest non-blocking hash table, written by our CTO and co-founder Cliff Click, who is known for his contributions to the fast Java HotSpot compiler.
AC: H2O is unique in that it’s the #1 Java-based open-source Machine Learning project on GitHub (and we’re in the final phases of a more developer-friendly rewrite). It is built on top of a distributed key-value store that’s based on the world’s fastest non-blocking hash table, written by our CTO and co-founder Cliff Click, who is known for his contributions to the fast Java HotSpot compiler.
H2O is designed to process large datasets (e.g., from HDFS, S3 or NFS) at FORTRAN speeds using a highly efficient (fine-grain) in-memory implementation of the famous Mapreduce paradigm with built-in lossless columnar compression (that often beats gzip on disk). H2O doesn’t require Hadoop, but it can be launched on Hadoop clusters by MRv1, YARN or Mesos, for seamless data ingest from HDFS.
 Sparkling Water tightly integrates the data pipelines in Apache Spark with H2O. In addition to native Java and Scala APIs, H2O also provides a powerful REST API to connect from R, Python, or Tableau clients. It also powers our easy-to-use Web API for interactive exploration of H2O’s capabilities. There's also auto-generated Java code to take the models directly into production (e.g., with Storm), which many enterprise customers find useful.
Sparkling Water tightly integrates the data pipelines in Apache Spark with H2O. In addition to native Java and Scala APIs, H2O also provides a powerful REST API to connect from R, Python, or Tableau clients. It also powers our easy-to-use Web API for interactive exploration of H2O’s capabilities. There's also auto-generated Java code to take the models directly into production (e.g., with Storm), which many enterprise customers find useful.
H2O and its methods are also backed by venture capital and some of the most knowledgeable experts in Machine Learning: Stanford professors Trevor Hastie, Rob Tibshirani and Steven Boyd. Other independent mentors include Java API expert Josh Bloch and Founder of S and R-core member John Chambers. We’ve literally spent days discussing algorithms, APIs and code together, which is a great honor and privilege. Of course, customers and users from the open source community are constantly validating our algorithms as well.
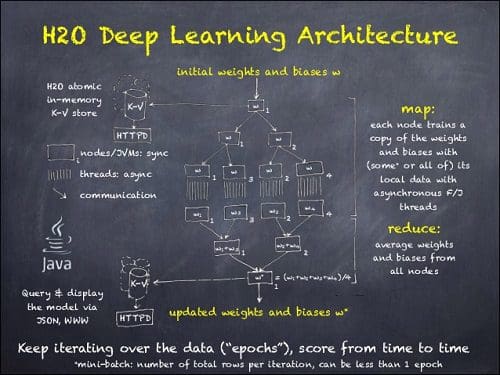
For H2O Deep Learning, we put lots of little tricks together to make it a very powerful method right out of the box. For example, it features automatic adaptive weight initialization, automatic data standardization, expansion of categorical data, automatic handling of missing values, automatic adaptive learning rates, various regularization techniques, automatic performance tuning, load balancing, grid-search, N-fold cross-validation, checkpointing, and different distributed training modes on clusters for large datasets. And the best thing is that the user doesn’t need to know anything about Neural Networks, there’s no complicated configuration files. It’s just as easy to train as a Random Forest and simply makes predictions for supervised regression or classification problems. For power users, there’s also quite a few (well-documented) options that enable fine-control of the learning process. By default, H2O Deep Learning will fully utilize every single CPU core on your entire cluster and is highly optimized for maximum performance.
I share our CEO and co-founder SriSatish Ambati’s vision that a whole ecosystem of smart applications can emerge from these recent advances in machine intelligence and fundamentally enrich our lives.
Second part of the interview.
Related: