WebDataCommons – the Data and Framework for Web-scale Mining
The WebDataCommons project extracts the largest publicly available hyperlink graph, large product-, address-, recipe-, and review corpora, as well as millions of HTML tables from the Common Crawl web corpus and provides the extracted data for public download.
By Robert Meusel and Christian Bizer (WebDataCommons).
Being able to mine the complete World Wide Web is a longstanding dream of many data miners. Until recently, only people working for large companies such as Google and Microsoft were able to realize this dream, as only these companies possessed large Web crawls. This has changed in 2012 with the nonprofit Common Crawl Foundation starting to crawl the Web and making large Web corpora accessible to anyone on Amazon S3.
Still, a corpus of several billion HTML pages is not exactly the right input for many mining algorithms and a fair amount of pre-processing and large data management expertise is required to extract the relevant pieces of data from the corpus. This is where the WebDataCommons project jumps in and supports data miners by extracting structured data from the Common Crawl and providing this data for public download. Beside one of the largest - if not the largest - publicly available hyperlink graph, the project extracts product-, address-, recipe-, and review data from HTML pages that use the Microdata, Microformats, and RDFa markup standards.
With 287 million product records originating from over 100,000 different websites, 48 million addresses from 130,000 websites, as well as 42 million customer reviews and 22 million job postings, each data corpus is amongst the largest that are available to the public in its category. In the following, we describe the WebDataCommons data corpora in more detail:

Fig. 1: Graph snapshot that shows how websites (not pages) from different top-level domains are linked (click on the image to see a very large 2000x2000 px version).
In addition to the page level graph, we also provide host-level and TLD-level aggregations of the graph for download. The graphs can be used to analyze the overall structure of the Web and reveal new insights, such as the falsification of the long-standing belief that the in-degree distribution of hyperlinks follows a power-law (Source). On the other hand, the graph can be used to evaluate the performance of graph databases and graph mining tools.
Bio: Robert Meusel is Ph.D. candidate at the Data and Web Science Group of the University of Mannheim. Before joining the research group in 2012, he was working for a Web personalization startup. His research focuses on Web data profiling where he is specialized in the analysis of entities in web pages annotated with markup languages such as RDFa, Microformats, and Microdata. He is one of the key persons behind the WebDataCommons project, mainly responsible for the structured data and hyperlink graph datasets and their analysis.
Robert Meusel is Ph.D. candidate at the Data and Web Science Group of the University of Mannheim. Before joining the research group in 2012, he was working for a Web personalization startup. His research focuses on Web data profiling where he is specialized in the analysis of entities in web pages annotated with markup languages such as RDFa, Microformats, and Microdata. He is one of the key persons behind the WebDataCommons project, mainly responsible for the structured data and hyperlink graph datasets and their analysis.
Prof. Christian Bizer is part of the Data and Web Science Group at the University of Mannheim. He explores technical and empirical questions concerning the development of global, decentralized information environments. Christian Bizer has initialized the W3C Linking Open Data effort which is interlinking large numbers of data sources on the Web and has co-founded the DBpedia project which derives a comprehensive knowledge base from Wikipedia.
Related:
Being able to mine the complete World Wide Web is a longstanding dream of many data miners. Until recently, only people working for large companies such as Google and Microsoft were able to realize this dream, as only these companies possessed large Web crawls. This has changed in 2012 with the nonprofit Common Crawl Foundation starting to crawl the Web and making large Web corpora accessible to anyone on Amazon S3.
Still, a corpus of several billion HTML pages is not exactly the right input for many mining algorithms and a fair amount of pre-processing and large data management expertise is required to extract the relevant pieces of data from the corpus. This is where the WebDataCommons project jumps in and supports data miners by extracting structured data from the Common Crawl and providing this data for public download. Beside one of the largest - if not the largest - publicly available hyperlink graph, the project extracts product-, address-, recipe-, and review data from HTML pages that use the Microdata, Microformats, and RDFa markup standards.
With 287 million product records originating from over 100,000 different websites, 48 million addresses from 130,000 websites, as well as 42 million customer reviews and 22 million job postings, each data corpus is amongst the largest that are available to the public in its category. In the following, we describe the WebDataCommons data corpora in more detail:
Hyperlink Graph
We have extracted a hyperlink graph covering 3.5 billion web pages and 128 billion hyperlinks from the 2012 version of the Common Crawl (Link).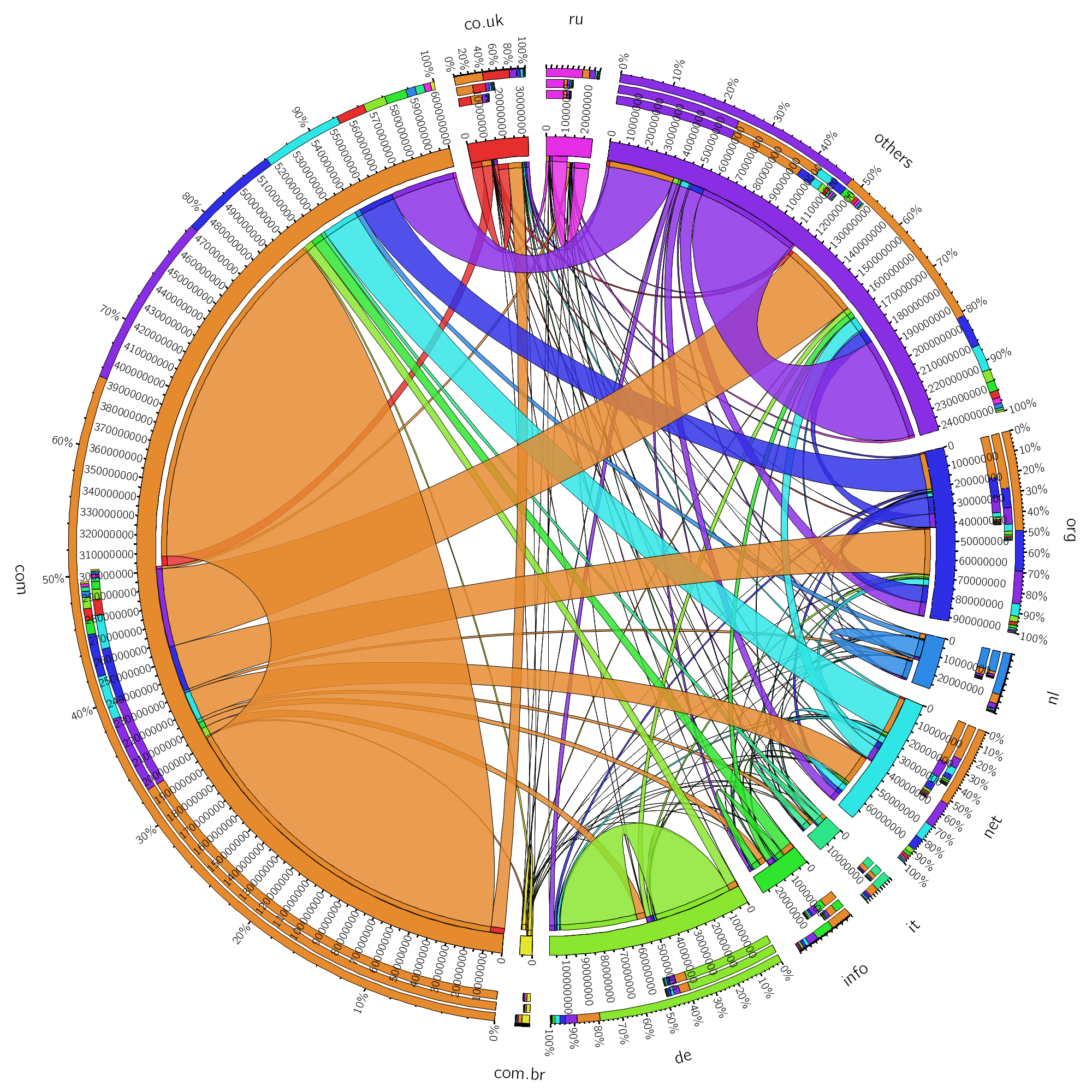
Fig. 1: Graph snapshot that shows how websites (not pages) from different top-level domains are linked (click on the image to see a very large 2000x2000 px version).
In addition to the page level graph, we also provide host-level and TLD-level aggregations of the graph for download. The graphs can be used to analyze the overall structure of the Web and reveal new insights, such as the falsification of the long-standing belief that the in-degree distribution of hyperlinks follows a power-law (Source). On the other hand, the graph can be used to evaluate the performance of graph databases and graph mining tools.
RDFa, Microdata and Microformats Data
We have extracted data from HTML pages that use one of the markup languages RDFa, Microdata, and Microformats (Link). So far, we offer data from the years 2010 to 2014. Altogether, the extracted data describes 13 billion products, local businesses, addresses, persons, organizations, recipes, and job postings, to name just a view. More detailed insights can be found in our paper. The data can, for example, be used to analyze price differences in e-shops on global scale, or the skills that are in high demand by employers in different regions.HTML Tables
We have also extracted a corpus of 147 million HTML tables that contain structured data describing countries, cities, artists, movies, songs, products, as well as other types of entities (Link to web tables). This table corpus can be useful input for generating large-scale knowledge bases, such as the Google Knowledge Graph, or for improving NLP methods.Extraction Framework
As we are strong believers in the potential of the Common Crawl, we also provide the extraction framework for download that we used to generate the datasets. In addition to the data that we provide, any interested party can adapt the framework to their needs and extract the data form the Common Crawl that is required for its task at hand.Bio:
 Robert Meusel is Ph.D. candidate at the Data and Web Science Group of the University of Mannheim. Before joining the research group in 2012, he was working for a Web personalization startup. His research focuses on Web data profiling where he is specialized in the analysis of entities in web pages annotated with markup languages such as RDFa, Microformats, and Microdata. He is one of the key persons behind the WebDataCommons project, mainly responsible for the structured data and hyperlink graph datasets and their analysis.
Robert Meusel is Ph.D. candidate at the Data and Web Science Group of the University of Mannheim. Before joining the research group in 2012, he was working for a Web personalization startup. His research focuses on Web data profiling where he is specialized in the analysis of entities in web pages annotated with markup languages such as RDFa, Microformats, and Microdata. He is one of the key persons behind the WebDataCommons project, mainly responsible for the structured data and hyperlink graph datasets and their analysis.
 Prof. Christian Bizer is part of the Data and Web Science Group at the University of Mannheim. He explores technical and empirical questions concerning the development of global, decentralized information environments. Christian Bizer has initialized the W3C Linking Open Data effort which is interlinking large numbers of data sources on the Web and has co-founded the DBpedia project which derives a comprehensive knowledge base from Wikipedia.
Prof. Christian Bizer is part of the Data and Web Science Group at the University of Mannheim. He explores technical and empirical questions concerning the development of global, decentralized information environments. Christian Bizer has initialized the W3C Linking Open Data effort which is interlinking large numbers of data sources on the Web and has co-founded the DBpedia project which derives a comprehensive knowledge base from Wikipedia.
Related: