Risk Management Framework for AI/ML Models
How sound risk management acts as a catalyst to building successful AI/ML models.

Source: Business vector created by jcomp — www.freepik.com (illustrating the make or break concept of managing AI Risk and producing successful AI models)
AI/ML models like any other mathematical and financial models come with their set of risks and require awareness to mitigate them beforehand. The intent of this article is very well summarised in the definition of risk:
Risk is the possibility of something bad happening. Risk involves uncertainty about the effects/implications of activity with respect to something that humans value (such as health, well-being, wealth, property, or the environment), often focusing on negative, undesirable consequences.
Risk needs to be accounted for well in advance, right at the design stage. One can not wait for the consequences to show up, in order to do the damage control. That is where “Risk Management” helps by designing a forward-looking approach, pulling levers to assess the worst-case scenario, and timely acting upon it.
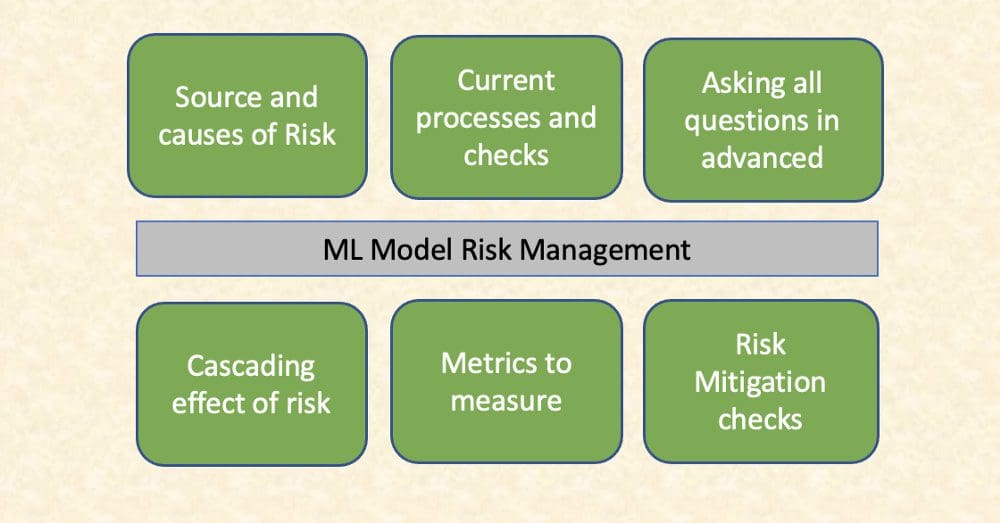
Source: Author
Key measures to manage risks include identifying the sources of risk and checking how they are handled in current processes. This analysis surfaces the gap where current checks may prove insufficient to the unforeseen risks.
The framework by principle involves brainstorming on what can possibly go wrong — one can not wait for a self-driving car to get stuck in the dilemma of whether to save an old man vs a child when on road. There is no one ideal answer to this problem but the worst-case scenario has to be thought through and should be acceptable before implementing the solution.
Risks by nature are not self-contained and have cascading effects by amplifying the nuisance all across. Clear metrics of how to define and measure risks are crucial to assure how risk is capped within acceptable limits. The metrics also prove the effectiveness of risk mitigation measures through pre and post-analysis.
The risks associated with AI are relatively unknown to measure, plan and capture in advance due to its recent technological advancements as against other mature industries like finance and medicine. There are a few lessons that can be directly learned and imported into the AI risk management tool:
- Documentation
- Data Integrity
- Regulations and Compliance
- Explainability
Documentation
ML models may end up solving a revised problem than the one originally conceived. The project starts with a certain expectation (read magic) from the ML model. However, the model’s performance gets restricted due to the lack of relevant attributes or good quality data providing statistical signals for model learning. A number of experiments are performed to calibrate the features, algorithms, data, or even the problem statement itself to assess how the model can best suit the exact or tweaked business task and yet add value.
For example, if the business requirement is to optimize resource allocation in a service center to attend to the bulk queries and calls received throughout the day. The problem can be framed as a multi-class classification where the target variable i.e. the expected number of calls can be divided into 3 categories — low, medium, and high. This implies that businesses will estimate resources as per the ML model’s prediction of the low, medium, or high workload (or the number of expected calls).
On the other hand, the business could be more interested in knowing the expected workload over the next week from the ML model and would apply its own post-processing logic to decide how the resources should be allocated.
We have discussed two ways of framing a problem statement — regression and classification.
While there is no one rule that fits all — it needs to be discussed with the business and well-documented. The assumptions, data availability, the history of the data, any attributes that are only available in real-time and are not shown to model during the learning phase need to be captured in great detail and signed-off with the client before diving deep into the data modeling.
Data Integrity
Covid has drastically changed the dynamics of how the world runs and rendered a lot of ML models becoming irrelevant. No model/AI solution provider would have been able to foresee it considering the black swan effect of this pandemic. But, there are other innumerable ways the model output can deviate from the expected outcome, one of the key reasons being the drift between the training data and inference data characteristics. Now, this is in developers' hands and can be controlled using various statistical methods. One such metric is the KS statistic.
If you want to learn more about how to maintain data quality to build successful machine learning solutions, I would recommend a prior read of this article. It explains how seamless data integration and consistency is crucial to maintaining data pipelines and underlines the importance of adopting data culture.
Reputational, Regulation, and Compliance Risks
Can artificially intelligent robots gain sentience and harm human safety by taking over the world? Such questions predominantly occupy our thoughts and immediately make AI the villain of the wave of digital transformation.
But AI is just a technology that can not do harm on its own unless it is designed and constructed to do so. This leads to an important and often ignored concept— intent.
Echoing Dave Waters, “The potential benefits of artificial intelligence are huge, so are the dangers.”

Source: People vector created by pch.vector — www.freepik.com, with inputs from Author on good and bad intent with examples
AI has huge untapped potential to improve human lives but comes with its own risks.
The moment risks enter the scene, follows the regulations. Yes, regulations are needed to put checks and balances in place and to make sure that they provide the right framework that does not deter the flight of AI benefits but controls the possible harms.
Societal and human-friendly applications that do not compromise or misuse personal data and respect user privacy can only succeed and make their way to market. Regulations like GDPR aim at giving control and rights to individuals over how they allow their personal data to be used.
Timely intervention and updates of such regulation frameworks ensure that our society can continue to reap the benefits of good intent of AI while deterring the mal-intended AI products to hit the ground.
Explainability
Can the AI model explain the predictions. It is imperative for the model developer to explain the internal working of the algorithm without trading off with the model accuracy. There are two ways it can be achieved — interpretable models or auxiliary tools.
Source: Education vector created by freepik — www.freepik.com
The words interpretability and explainability are often used interchangeably. Models like decision trees, linear regression come under the umbrella of interpretable models due to their inherent nature of interpreting the predictions. While black-box models like deep neural networks need the help of auxiliary tools and techniques like LIME and SHAP framework to explain the model output.
The illustration shown below captures the true state the data science community should strive to achieve where we are able to explain why a model outputs a particular class X and not class Y. When does the model succeed and can be trusted with a greater degree of confidence? What changes in the input data would have led to the flip in predictions etc.
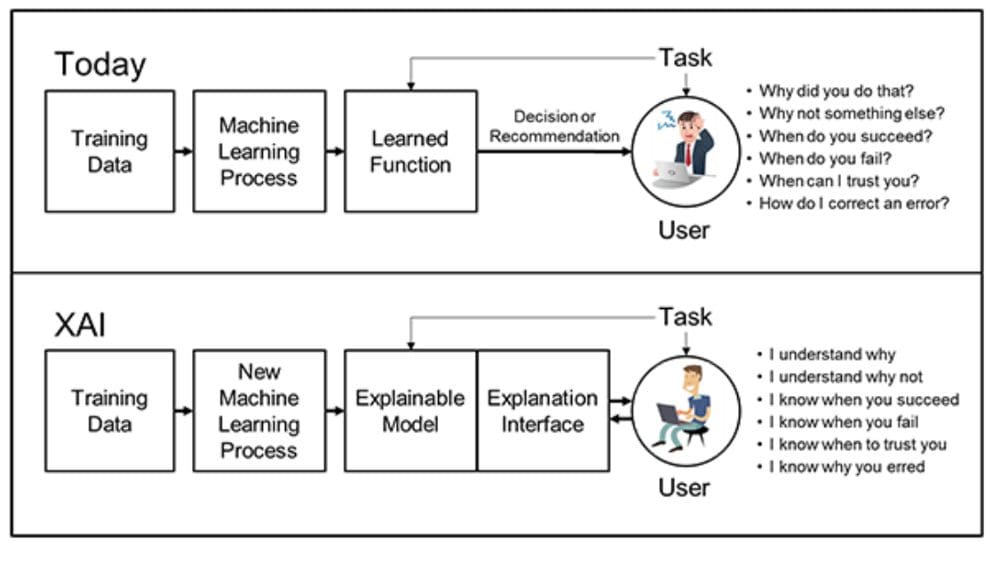
Source: https://www.darpa.mil/program/explainable-artificial-intelligence
There are various tools that help keep the risk in check, including but not limited to model interpretability, bias detection, and mitigation, model monitoring, and maintenance.
I will elaborate more on each of these in my upcoming articles. So stay tuned.
Vidhi Chugh is an award-winning AI/ML innovation leader and an AI Ethicist. She works at the intersection of data science, product, and research to deliver business value and insights. She is an advocate for data-centric science and a leading expert in data governance with a vision to build trustworthy AI solutions.