Opening Up Deep Learning For Everyone
Opening deep learning up to everyone is a noble goal. But is it achievable? Should non-programmers and even non-technical people be able to implement deep neural models?
By Jason Toy, Founder of Somatic.
Machine learning, the act of computers learning without being explicitly programmed,has typically been thought of as magic that only mathematicians and programmers could perform. That has been the case for a while and that is due to several reasons.
Not only do you need to be able to write code, but you need to have strong math skills. There is no way around it, but you can still do a lot of meaningful work if you don’t have the full math background.
I believe we are on a path where everyone who programs now will be building some form of machine learning models in the future. People who have never programmed before will be building machine learning models in the future.
Feature engineering
Typically with machine learning, you must get the data to the computer in a form that it can understand. That usually means converting all of your data into a large spreadsheet of numbers consisting of many rows and columns. Each row is called an instance or an example and each column is called a feature. So then you feed those numbers into the machine learning algorithm and it tries to learn from the data. Since engineering the features is very time consuming, we need to be try and be smart and only extract the features that would improve the model. But since you don’t actually know if those features are useful until you train and test your model, you get into this cycle where you develop new features, rebuild the model, measure results, and repeat until you are satisfied with the results. This is an extremely time consuming task and could end up taking most of your time.
Feature extraction with deep learning
Deep Learning is just another name for artificial neural networks (or ANN for short). They have been around for 40+ years, but it wasn’t until the early 2000’s that NVIDIA brought their chips to scientific computing, this has essentially rekindled the use of neural networks. The reason deep learning is “deep” is because of the structure of ANNs. ANNs are essentially layers of neurons stacked like a pyramid. 40 years ago, neural networks were doing at most 2 layers. This was because it was not computationally feasible to build larger networks, it would take months or years to compute! Now it is common to see ANNs with 10+ layers. Engineers have started to build 100+ layer ANNs.
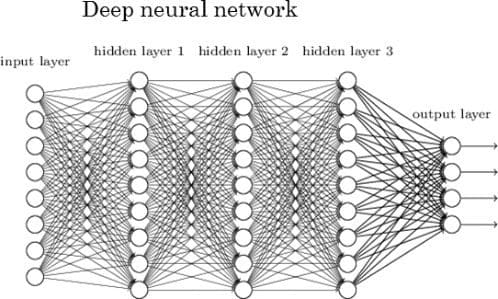
This is considered deep
You can essentially stack layers of neurons on top of each other. The lowest layer takes raw data: images, text, sound, etc and then each neuron stores some information about the data they saw. Each neuron in the layer sends information up to the next layer of neurons which learn a more abstract version of the data below it. So the higher up you go , the more abstract features you learn. You can see in the picture below has 5 layers, 3 are hidden layers.
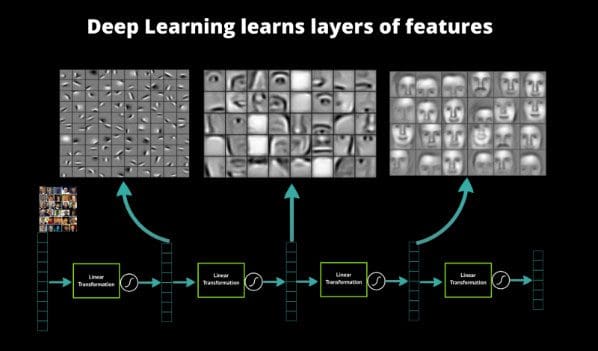
Features learned in a deep neural network
So why is this important? Well, it means that the ANNs are automatically extracting features. Instead of us having to take an image and hand compute features like distribution of colors, image histograms,unique color count, etc, we just feed the raw images in. ANN’s have typically performed best on images, but now they are being applied to all kinds of other datasets like raw text. This completely changes the game. Now if you are building a machine learning model, you can focus on more important things like the algorithms.
Open source and open science
Open source got really big thanks to linux. There are so many open source projects created every single day. And fortunately in deep learning, there is still a lot of open source going on. Tensorflow, Torch, keras, Big Sur hardware, DIGITS,and Caffe are some of the bigger open source deep learning projects. In academic research, we have lots of papers that are still coming out. I don’t know for sure, but I believe that more papers are including algorithm source code with their findings. Arxiv.org has open access to over 1 million papers. As long as research remains fairly open, more people will build deep learning algorithms.
Data and data acquisition
So I mentioned earlier that we don’t need to do as much feature engineering anymore. That is true, but deep learning algorithms are data hungry, so we need access to large amounts of data to feed into our models.
There are large data sources available that we didn’t have 20 years ago: the internet, wikipedia, emails, flickr, google, project guttenburg, etc.
Although there is so much data available for us to process, it still needs to be collected and cleaned up for processing. This will remain the main bottleneck.
For now, realistically it will only be large companies that have the resources to be able to collect and process the data needed to power these machine learning models.
I see in the near future people opening up more data sets for public consumption. Almost every time we open up a new data set, new benchmarks in machine learning are broken.
Conclusion
Yes there is a lot of deep learning hype, but it is justified.
Just as more and more people are learning computer science, more and more people will be building deep learning models. If you have studied “STEM” or done any programming, you already have most of the skills necessary to build deep learning models.
With the opening up of machine learning frameworks, access to larger data sets, and better machine learning algorithms, I see a lot more people going into machine learning.
To further accelerate machine learning’s progress, we have to work on the essentials: make it easier for people to learn about deep learning and create better software tools for people to play around.
If you have any interest in building machine learning models, I implore you to start playing and building now. If you have any questions on how to get involved or ideas for cool machine models to build, feel free to contact me.
Bio: Jason Toy is a serial entrepreneur and engineer, who founded socmetrics, truelens, and is the former CEO of filepicker and CTO of backchannelmedia. He builds machine learning models, researches artificial intelligence, and starts companies. He likes to build it.
Original. Reposted with permission.
Related:
- Deep Feelings On Deep Learning
- 7 Steps to Understanding Deep Learning
- What To Expect from Deep Learning in 2016 and Beyond