7 Steps to Understanding Deep Learning
There are many deep learning resources freely available online, but it can be confusing knowing where to begin. Go from vague understanding of deep neural networks to knowledgeable practitioner in 7 steps!
Deep learning is a branch of machine learning, employing numerous similar, yet distinct, deep neural network architectures to solve various problems in natural language processing, computer vision, and bioinformatics, among other fields. Deep learning has experienced a tremendous recent research resurgence, and has been shown to deliver state of the art results in numerous applications.
In essence, deep learning is the implementation of neural networks with more than a single hidden layer of neurons. This is, however, a very simplistic view of deep learning, and not one that is unanimously agreed upon. These "deep" architectures also vary quite considerably, with different implementations being optimized for different tasks or goals. The vast research being produced at such a constant rate is revealing new and innovative deep learning models at an ever-increasing pace.
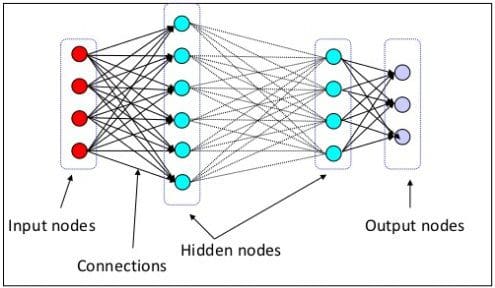
The layers of neural networks.
Currently a white hot research topic, deep learning seems to be impacting all areas of machine learning and, by extension, data science. A look over recent papers in the relevant arXiv categories makes it easy to see that a large amount of what is being published is deep learning-related. Given the impressive results being produced, many researchers, practitioners, and laypeople alike are wondering if deep learning is the edge of "true" artificial intelligence.
This collection of reading materials and tutorials aims to provide a path for a deep neural networks newcomer to gain some understanding of this vast and complex topic. Though I do not assume any real understanding of neural networks or deep learning, I will assume your familiarity with general machine learning theory and practice to some degree. To overcome any deficiency you may have in the general areas of machine learning theory or practice you can consult the recent KDnuggets post 7 Steps to Mastering Machine Learning With Python. Since we will also see examples implemented in Python, some familiarity with the language will be useful. Introductory and review resources are also available in the previously mentioned post.
This post will utilize freely-available materials from around the web in a cohesive order to first gain some understanding of deep neural networks at a theoretical level, and then move on to some practical implementations. As such, credit for the materials referenced lie solely with the creators, who will be noted alongside the resources. If you see that someone has not been properly credited for their work, please alert me to the oversight so that I may swiftly rectify it.
A stark and honest disclaimer: deep learning is a complex and quickly-evolving field of both breadth and depth (pun unintended?), and as such this post does not claim to be an all-inclusive manual to becoming a deep learning expert; such a transformation would take greater time, many additional resources, and lots of practice building and testing models. I do, however, believe that utilizing the resources herein could help get you started on just such a path.
Step 1: Introducing Deep Learning
If you are reading this and interested in the topic, then you are probably already familiar with what deep neural networks are, if even at a basic level. Neural networks have a storied history, but we won't be getting into that. We do, however, want a common high level of understanding to begin with.
First, have a look at the fantastic introductory videos from DeepLearning.tv. At the time of this writing there are 14 videos; watch them all if you like, but definitely watch the first 5, covering the basics of neural nets and some of the more common architectures.
Next, read over the NIPS 2015 Deep Learning Tutorial by Geoff Hinton, Yoshua Bengio, and Yann LeCun for an introduction at a slightly lower level.
To round out our first step, read the first chapter of Neural Networks and Deep Learning, the fantastic, evolving online book by Michael Nielsen, which goes a step further but still keeps things fairly light.
Step 2: Getting Technical
Deep neural nets rely on a mathematical foundation of algebra and calculus. While this post will not produce any theoretical mathematicians, gaining some understanding of the basics before moving on would be helpful.
First, watch Andrew Ng's linear algebra review videos. While not absolutely necessary, for those finding they want something deeper on this subject, consult the Linear Algebra Review and Reference from Ng's Stanford course, written by Zico Kolter and Chuong Do.
Then look at this Introduction to the Derivative of a Function video by Professor Leonard. The video is succinct, the examples are clear, and it provides some understanding of what is actually going on during backpropagation from a mathematical standpoint. More on that soon.
Next have a quick read over the Wikipedia entry for the Sigmoid function, a bounded differentiable function often employed by individual neurons in a neural network.
Finally, take a break from the maths and read this Deep Learning Tutorial by Google research scientist Quoc Le.
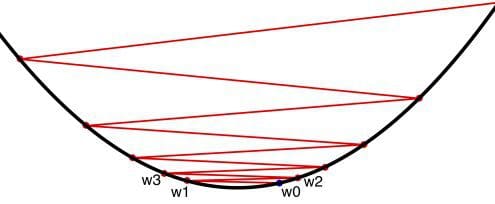
Gradient descent, visualized.
Step 3: Backpropagation and Gradient Descent
An important part of neural networks, including modern deep architectures, is the backward propagation of errors through a network in order to update the weights used by neurons closer to the input. This is, quite bluntly, from where neural networks derive their "power," for lack of better term. Backpropagation for short (or even "backprop"), is paired with an optimization method which acts to minimize the weights that are subsequently distributed (via backpropagation), in order to minimize the loss function. A common optimization method in deep neural networks is gradient descent.
First, read these introductory notes on gradient descent by Marc Toussaint of the University of Stuttgart.
Next, have a look at this step by step example of backpropagation in action written by Matt Mazur.
Moving on, read Jeremy Kun's informative blog post on coding backpropagation in Python. Having a look over the complete code is also suggested, as is attempting to replicate it yourself.
Finally, read the second part of the Deep Learning Tutorial by Quoc Le, in order to get introduced to some specific common deep architectures and their uses.