Understanding Bias-Variance Trade-Off in 3 Minutes
This article is the write-up of a Machine Learning Lighting Talk, intuitively explaining an important data science concept in 3 minutes.

Bias and Variance are the core parameters to tune while training a Machine Learning model.
When we discuss prediction models, prediction errors can be decomposed into two main subcomponents: error due to bias, and error due to variance.
Bias-variance trade-off is tension between the error introduced by the bias and the error produced by the variance. To understand how to make the most of this trade-off and avoid underfit or overfit our model, lets first learn that Bias an Variance.
Errors due to Bias
An error due to Bias is the distance between the predictions of a model and the true values. In this type of error, the model pays little attention to training data and oversimplifies the model and doesn't learn the patterns. The model learns the wrong relations by not taking in account all the features
Errors due to Variance
Variability of model prediction for a given data point or a value that tells us the spread of our data. In this type of error, the model pays an lot of attention in training data, to the point to memorize it instead of learning from it. A model with a high error of variance is not flexible to generalize on the data which it hasn’t seen before.
If Bias vs Variance was the act of reading, it could be like Skimming a Text vs Memorizing a Text
We want our machine model to learn from the data it is exposed to, not to “have an idea of what it is about” or “memorize it word by word.”
Bias — Variance Trade-Off
Bias- Variance trade-off is about balancing and about finding a sweet spot between error due to bias and errors due to variance.
It is an Underfitting vs Overfitting dilemma
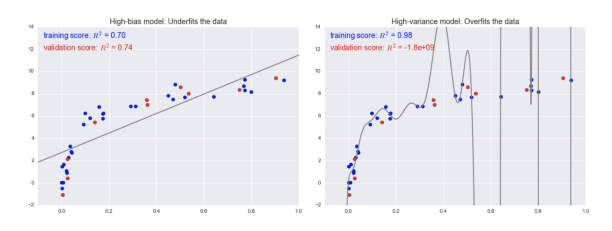
If the model is indicated by the line in grey, we can see that a high bias model is a model that oversimplifies the data, while a high variance model is a model too complicated that overfits the data.
In short:
- Bias is the simplifying assumptions made by the model to make the target function easier to approximate.
- Variance is the amount that the estimate of the target function will change, given different training data.
- Bias-variance trade-off is the sweet spot where our machine model performs between the errors introduced by the bias and the variance.
In this post, we discussed the conceptual meaning of Bias and Variance. Next, we will explore the concept in code.
Future reading
- Understanding the Bias-Variance Tradeoff by Scott Fortmann- Roe
- The Element of Statistical Learning by Trevor Hastie, Robert Tibshirani, and Jerome Friedman
Brenda Hali (LinkedIn) is a Marketing Data Specialist based in Washington, D.C. She is passionate about women's inclusion in technology and data.
Original. Reposted with permission.