 When Does Deep Learning Work Better Than SVMs or Random Forests®?
When Does Deep Learning Work Better Than SVMs or Random Forests®?
 When Does Deep Learning Work Better Than SVMs or Random Forests®?
When Does Deep Learning Work Better Than SVMs or Random Forests®?Some advice on when a deep neural network may or may not outperform Support Vector Machines or Random Forests.
If we tackle a supervised learning problem, my advice is to start with the simplest hypothesis space first. I.e., try a linear model such as logistic regression. If this doesn't work "well" (i.e., it doesn't meet our expectation or performance criterion that we defined earlier), I would move on to the next experiment.
Random Forests vs. SVMs
I would say that random forests are probably THE "worry-free" approach - if such a thing exists in ML: There are no real hyperparameters to tune (maybe except for the number of trees; typically, the more trees we have the better). On the contrary, there are a lot of knobs to be turned in SVMs: Choosing the "right" kernel, regularization penalties, the slack variable, ...
Both random forests and SVMs are non-parametric models (i.e., the complexity grows as the number of training samples increases). Training a non-parametric model can thus be more expensive, computationally, compared to a generalized linear model, for example. The more trees we have, the more expensive it is to build a random forest. Also, we can end up with a lot of support vectors in SVMs; in the worst-case scenario, we have as many support vectors as we have samples in the training set. Although, there are multi-class SVMs, the typical implementation for mult-class classification is One-vs.-All; thus, we have to train an SVM for each class -- in contrast, decision trees or random forests, which can handle multiple classes out of the box.
To summarize, random forests are much simpler to train for a practitioner; it's easier to find a good, robust model. The complexity of a random forest grows with the number of trees in the forest, and the number of training samples we have. In SVMs, we typically need to do a fair amount of parameter tuning, and in addition to that, the computational cost grows linearly with the number of classes as well.
Deep Learning
As a rule of thumb, I'd say that SVMs are great for relatively small data sets with fewer outliers. Random forests may require more data but they almost always come up with a pretty robust model. And deep learning algorithms... well, they require "relatively" large datasets to work well, and you also need the infrastructure to train them in reasonable time. Also, deep learning algorithms require much more experience: Setting up a neural network using deep learning algorithms is much more tedious than using an off-the-shelf classifiers such as random forests and SVMs. On the other hand, deep learning really shines when it comes to complex problems such as image classification, natural language processing, and speech recognition. Another advantage is that you have to worry less about the feature engineering part. Again, in practice, the decision which classifier to choose really depends on your dataset and the general complexity of the problem -- that's where your experience as machine learning practitioner kicks in.
If it comes to predictive performance, there are cases where SVMs do better than random forests and vice versa:
- Caruana, Rich, and Alexandru Niculescu-Mizil. "An empirical comparison of supervised learning algorithms." Proceedings of the 23rd international conference on Machine learning. ACM, 2006.
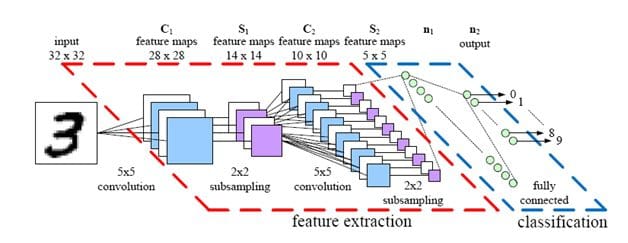
The same is true for deep learning algorithms if you look at the MNIST benchmarks (http://yann.lecun.com/exdb/mnist/): The best-performing model in this set is a committee consisting of 35 ConvNets, which were reported to have a 0.23% test error; the best SVM model has a test error of 0.56%. The ConvNet ensemble may reach a better accuracy (for the sake of this ensemble, let's pretend that these are totally unbiased estimates), but without a question, I'd say that the 35 ConvNet committee is far more expensive (computationally). So, if you make that decision: Is a 0.33% improvement worth it? In some cases, it's maybe worth it (e.g., in the financial sector for non-real time predictions), in other cases it perhaps won't be worth it, though.
So, my practical advice is:
- Define a performance metric to evaluate your model
- Ask yourself: What performance score is desired, what hardware is required, what is the project deadline
- Start with the simplest model
- If you don't meet your expected goal, try more complex models (if possible)
Bio: Sebastian Raschka is a 'Data Scientist' and Machine Learning enthusiast with a big passion for Python & open source. Author of 'Python Machine Learning'. Michigan State University.
Original. Reposted with Permission.
RANDOM FORESTS and RANDOMFORESTS are registered marks of Minitab, LLC.
Related:
- 7 Steps to Understanding Deep Learning
- What To Expect from Deep Learning in 2016 and Beyond
- Top 10 Deep Learning Projects on Github