Let Me Hear Your Voice and I’ll Tell You How You Feel
This post provides an overview of a voice tone analyzer implemented as part of a cohesive emotion detection system, directly from the researcher and architect.
By Carlos Argueta, Soul Hacker Labs.
Creating mood sensing technology has become very popular in recent years. There is a wide range of companies trying to detect your emotions from what you write, the tone of your voice, or from the expressions on your face. All of these companies offer their technology online through cloud-based programming interfaces (APIs).

As part of my offline emotion sensing hardware (Project Jammin), I have already built early prototypes of facial expression and speech content recognition for emotion detection. In this short article I describe the missing part, a voice tone analyzer.
In order to build a tone analyzer, it is necessary to study the properties of the speech waveform (a two dimensional representation of a sound). Waveforms are also known as time domain representations of sound as they are representations of changes in intensity over time. For more details about the waveform you can refer to this interesting page.
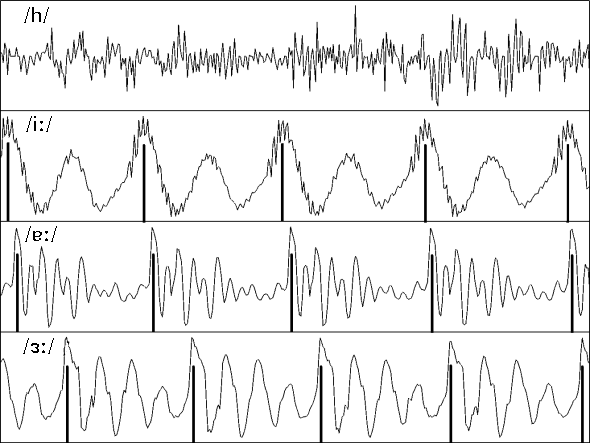
Using software specifically designed to analyze speech, the idea is to extract certain characteristics of the waveform that can be used as features to train a machine learning classifier. Given a collection of speech recordings, manually labelled with the emotion expressed, we can construct vector representations of each recording using the extracted features.
The features used in emotion detection from speech vary from work to work, and sometimes even depend on the language analyzed. In general, many research and applied works used a combination of pitch, Mel Frequency Cepstral Coefficients (MFCC), and Formants of speech.
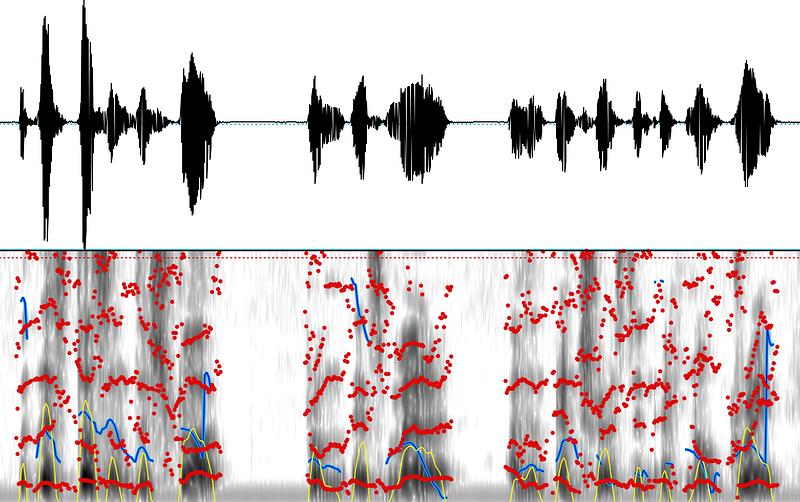
Below the pitch in blue, intensity in yellow, and formants in red.
Once the features are extracted and the vector representations of speech constructed, a classifier is trained to detect emotions. Several types of classifiers have been utilized in previous works. Among the most popular are Support Vector Machines (SVM), Logistic Regressions (Logit), Hidden Markov Models (HMM), and Neural Networks (NN).
As an early prototype I have implemented a simplified version of an emotion detection classifier. Instead of detecting several emotions like joy, sadness, anger, etc., my tone analyzer performs a binary classification to detect the level of arousal of a user. A high level of arousal is associated with emotions like joy, surprise, and anger whereas a low level of arousal is associated with emotions like sadness and boredom. The video below shows my tone analyzer running on a Raspberry Pi. Enjoy!
Bio: Carlos Argueta is a Honduran entrepreneur residing in Taiwan. He holds a Ph.D. in Information Systems and Applications and is the co-founder of Veryfast Inc. and Soul Hackers Labs.
Related:
- Deep Feelings On Deep Learning
- What To Expect from Deep Learning in 2016 and Beyond
- 11 things to know about Sentiment Analysis