Contest 2nd Place: Automating Data Science
This post discusses some considerations, options, and opportunities for automating aspects of data science and machine learning. It is the second place recipient (tied) in the recent KDnuggets blog contest.
By Ankit Sharma, DataRPM.
Editor's note: This blog post was an entrant in the recent KDnuggets Automated Data Science and Machine Learning blog contest, where it tied for second place.
Data scientist is the sexiest job of 21st century. But even Data Scientists have to get our hands dirty to get things done. What if some of the manual laborious tasks are automated and we bring the cool factor back to the job by only focusing on the logic and research.
Any generic data science pipeline will have the following components. To automate DS pipeline, we need to automate each individual component separately.

Lot of research has been undergoing in automating Data Cleaning & Feature Generation & Selection aspect of DS pipeline because they consume almost 70% of the data science project time.
For this post we’ll focus on the not much talked about topics: Algorithm Selection and Parameter Tuning. Both of these components are considered manual in nature. Data scientists spend hours applying multiple ML algorithms and then tuning the parameters. For every new problem they follow the same process and over period they develop the intuition of which algorithm will work better for which type of dataset and how best they can tune the parameters. If you look closely this is in itself a learning problem. Lately lot of research & development has been started to automate these components to get best accuracy in least amount of time and efforts.
Automating Algorithm selection can be done using concept called Meta Learning while to automate Parameter tuning there are different techniques like Grid search, bayesian optimization, etc which we’ll be discussing later in the post.
Automating Algorithm Selection using Meta Learning
There are two essential parts of Meta-learning - Meta Store & Meta-model algorithm. Meta store is used to capture metadata of datasets and metadata of algorithm which gave best results after hyper-parameter tuning. As soon as dataset is loaded into the environment, its metadata is generated and stored in the centralized MetaStore. Before running any machine learning algorithm (specially for classification and regression model) Meta-model algorithm will analyze the metadata of this dataset and run algorithm ranking logic which will predict the machine learning model out of 10-20 different models that which model might perform better on this dataset.
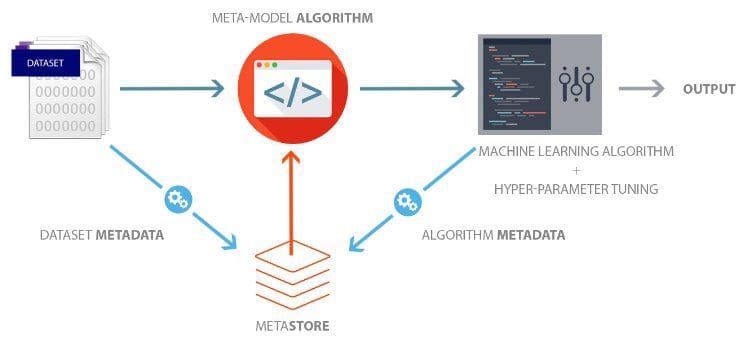
Once the algorithm is selected, next step is to run hyper-parameter tuning algorithms to tune this model. Meta model algorithm will essentially use MetaStore and machine learning algorithm. Meta-model algorithm will also help in reducing the hyper parameter space which boosts convergence rapidly to provide best result.
To set up MetaStore, we need to capture Dataset metadata and Best Algorithm run metadata. Lot of features can be stored for both. Some of the useful feature list is as follows:
Dataset metadata
- No of observations
- Ratio of the number of observations by the number of attributes
- Number of Categorical features
- Number of Numerical features
- Number of Classes
- Class imbalance ratio
- Percentage of missing values
- Multivariate normality
- Skewness of features
- Percentage of the attributes after Feature Selection
- Percentage of outliers
- Decision Tree model characteristics like nodes per feature, maximum tree depth, shape, tree imbalance, etc
- Max fisher’s discriminant ratio
- Maximum (individual) feature efficiency
- Collective feature efficiency
- Fraction of points on the class boundary
- Ratio of average intra/inter class nearest neighbor distance
- Leave-one- out error rate of the one-nearest neighbor classifier
- Non-linearity of the one-nearest neighbor classifier
- Average number of points per dimension
- Number of optimal clusters
- WSSE of clusters
- Domain of the dataset
Algorithm metadata
- Dataset ID
- Algorithm ID
- Hyperparameters
- Runtime
Meta-model algorithm
This is the brain of Meta-learning. This itself is a machine learning algorithm which basically learns from the various run of different algorithms on a lot of datasets. Algorithm metadata which we derived from best algorithm run on a particular dataset and stored it in MetaStore, and dataset metadata are combined together to form a new dataset which is fed to machine learning algorithm which ranks section of ML algorithms for a particular dataset.

Hyper parameter tuning
Almost all machine learning algorithm have hyper-parameters. SVM has Regularization parameter( C ), k-means has Number of clusters(k), Neural network has Number of hidden layers, dropout, etc as hyperparameters.
Efficiently finding the best solution of these hyper-parameters is the key to any ML solution. There are basically three famous techniques to tune the hyper-parameters of any machine learning algorithms:

- Manual Search: Data Scientists try different values and by Luck may end up getting the best solution. It is very common among DS community.
- Grid Search: Machine does all the work by evaluating each parameters combinations and checking for best result. It works only for less feature; as the feature set increases so does the number of combination and thereby computation time.
- Random Search: Works with large features
There has been some recent advancements in this field where data scientists are using Bayesian approach to optimize hyper-parameters. This approach works well with very large number of features but can be an overkill for less data and dataset with less features. The goal is to maximize some true unknown function f. Information about this function is gained by making observations, which are evaluations of the function at specific hyper-parameter values. These observations are used to infer a posterior distribution over the function values representing the distribution of possible functions. This approach takes less number of iterations to optimize the values of hyperparameters. It may not find the best solution always but will give relatively close to best solution in amazingly less number of iterations.
There has been lot of buzz in this field lately. There are some commercial and open source tools available which trying to make lives of Data Scientist easier.
Open source tools to look for:
Further reading and references:
- Metalearning for Data Mining and KDD
- MLA Bergstra, James S., et al. "Algorithms for hyperparameter optimization." Advances in Neural Information Processing Systems. 2011.
- TPOT: A Python tool for automating data science
- Bayesian Optimization for Hyperparameter Tuning
Bio: Ankit Sharma is a Data Scientist at DataRPM.
Related:
- Data Science Automation: Debunking Misconceptions
- And the Winner is… Stepwise Regression
- TPOT: A Python Tool for Automating Data Science