Deep Learning Reading Group: SqueezeNet
This paper introduces a small CNN architecture called “SqueezeNet” that achieves AlexNet-level accuracy on ImageNet with 50x fewer parameters.
By Abhinav Ganesh, Lab41.

The next paper from our reading group is by Forrest N. Iandola, Matthew W. Moskewicz, Khalid Ashraf, Song Han, William J. Dally and Kurt Keutzer. This paper introduces a small CNN architecture called “SqueezeNet” that achieves AlexNet-level accuracy on ImageNet with 50x fewer parameters. As you may have noticed with one of our recent posts we’re really interested in learning more about the compression of neural network architectures and this paper really stood out.
It’s no secret that much of deep learning is tied up in the hell that is parameter tuning. This paper makes a case for increased study into the area of convolutional neural network design in order to drastically reduce the number of parameters you have to deal with. Unlike our previous post on “deep compression”, this paper proposes making a network smaller by starting with a smarter design versus using a clever compression scheme. The authors outline 3 main strategies for reducing parameter size while maximizing accuracy. I’ll walk you through them now.
Strategy 1. Make the network smaller by replacing 3x3 filters with 1x1 filters
This strategy reduces the number of parameters 9x by replacing a bunch of 3x3 filters with 1x1 filters. At first this seemed really confusing to me. By moving 1x1 filters across an image I would think that each filter has less information to look at and would thus perform more poorly, however that doesn’t seem to be the case! Typically a larger 3x3 convolution filter captures spatial information of pixels close to each other. On the other hand, 1x1 convolutional filters zero in on a single pixel and capture relationships amongst its channels as opposed to neighboring pixels. If you are looking to learn more about the use of 1x1 filters check out this blog post.
Strategy 2. Reduce the number of inputs for the remaining 3x3 filters
This strategy reduces the number of parameters by basically just using fewer filters. The systematic way this is done is by feeding “squeeze” layers into what they term “expand” layers as shown below:
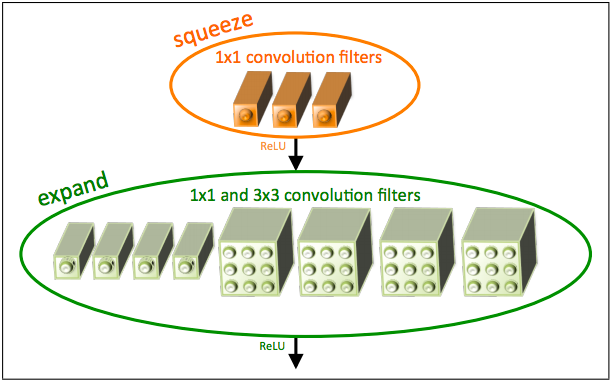
Time to define some terms that are specific only to this paper! As you can see above, “squeeze” layers are convolution layers that are made up of only 1x1 filters and “expand” layers are convolution layers with a mix of 1x1 and 3x3 filters. By reducing the number of filters in the “squeeze” layer feeding into the “expand” layer, they are reducing the number of connections entering these 3x3 filters thus reducing the total number of parameters. The authors of this paper call this specific architecture the “fire module” and it serves as the basic building block for the SqueezeNet architecture.
Strategy 3. Downsample late in the network so that convolution layers have large activation maps.
Now that we have talked about ways to reduce the sheer number of parameters we are working with, how can we get the most out of our remaining set of smaller parameters? The authors believe that by decreasing the stride with later convolution layers and thus creating a larger activation/feature map later in the network, classification accuracy actually increases. Having larger activation maps near the end of the network is in stark contrast to networks like VGG where activation maps get smaller as you get closer to the end of a network. This different approach is very interesting and they cite a paper by K. He and H. Sun that similarly applies a delayed down sampling that leads to higher classification accuracy.
So how does this all fit together?
SqueezeNet takes advantage of the aforementioned “fire module” and chains a bunch of these modules together to arrive at a smaller model. Here are a few variants of this chaining process as shown in their paper:
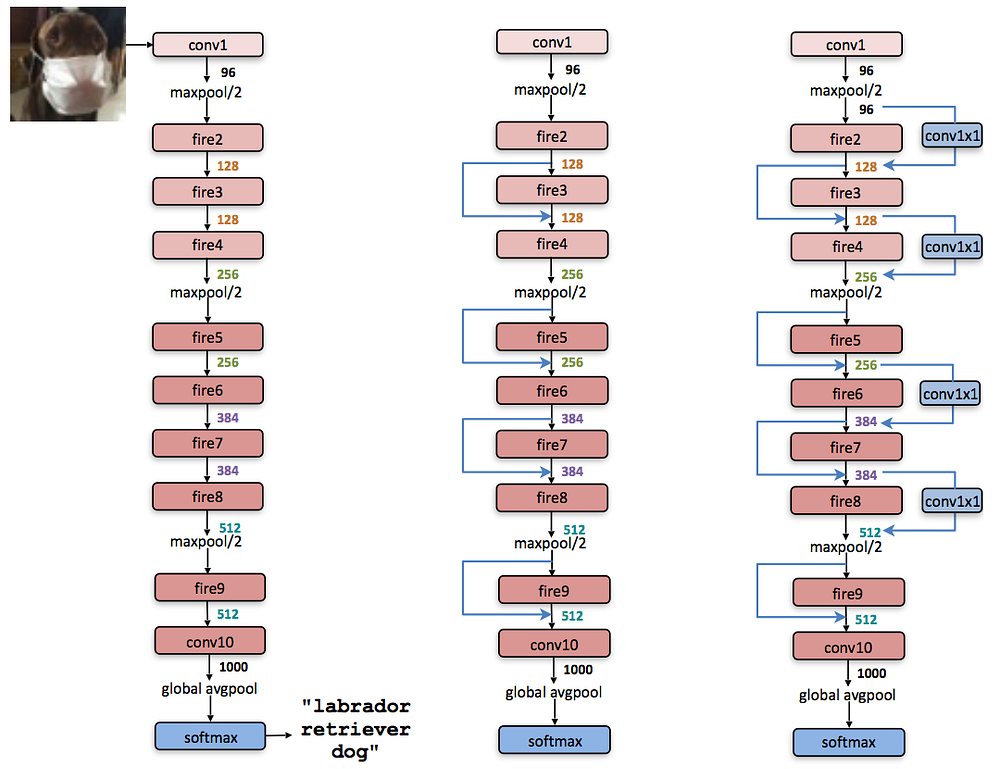
One of the surprising things I found with this architecture is the lack of fully-connected layers. What’s crazy about this is that typically in a network like VGG, the later fully connected layers learn the relationships between the earlier higher level features of a CNN and the classes the network is trying to identify. That is, the fully connected layers are the ones that learn that noses and ears make up a face, and wheels and lights indicate cars. However, in this architecture that extra learning step seems to be embedded within the transformations between various “fire modules”. The authors derived inspiration for this idea from the NiN architecture.
Enough with the details! How does this perform?
The authors of the paper show some impressive results.
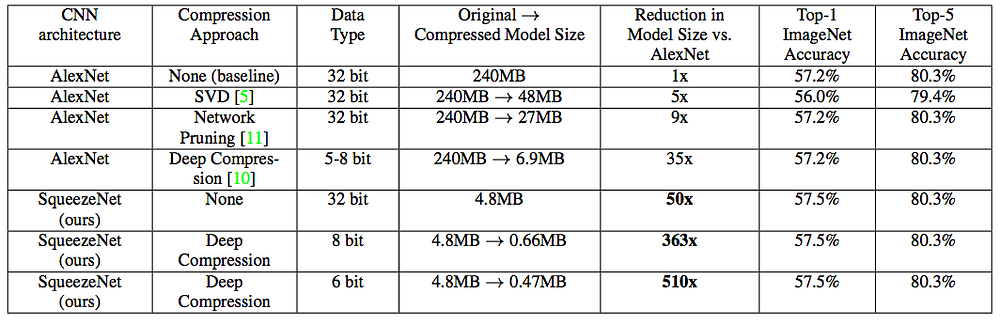
Their SqueezeNet architecture was able to achieve a 50X reduction in model size compared to AlexNet while meeting or exceeding the top-1 and top-5 accuracy of AlexNet. But perhaps the most interesting part of this paper is their application of Deep Compression (explained in our previous post) to their already smaller model. This application of Deep Compression created a model that was 510x smaller than AlexNet! These results are really encouraging because it shows the potential for combining different approaches for compression. As next steps I would love to see how this type of design thinking can apply to other neural network architectures and deep learning applications.
If this paper seems interesting to you, definitely check out their open source code for SqueezeNet on Github. I only had time to cover the highlights but their paper is full of in depth discussions on parameter reducing CNN design.
Abhinav Ganesh is currently a software engineer at Lab41 working on applying machine learning to cybersecurity. He holds a BS and MS in electrical and computer engineering from Carnegie Mellon University.
Lab41 is a “challenge lab” where the U.S. Intelligence Community comes together with their counterparts in academia, industry, and In-Q-Tel to tackle big data. It allows participants from diverse backgrounds to gain access to ideas, talent, and technology to explore what works and what doesn’t in data analytics. An open, collaborative environment, Lab41 fosters valuable relationships between participants.
Original. Reposted with permission.
Related: