Parallelism in Machine Learning: GPUs, CUDA, and Practical Applications
The lack of parallel processing in machine learning tasks inhibits economy of performance, yet it may very well be worth the trouble. Read on for an introductory overview to GPU-based parallelism, the CUDA framework, and some thoughts on practical implementation.
Traditionally (whatever that means in this context), machine learning has been executed in single processor environments, where algorithmic bottlenecks can lead to substantial delays in model processing, from training, to classification, to distance and error calculations, and beyond. Beyond recent technology-harnessing in neural networking training, much of machine learning - including both off-the-shelf libraries like scikit-learn and DIY algorithm implementation - has been approached without the use of parallel processing.
The lack of parallel processing, in this context referring to parallel execution on a shared-memory architecture, inhibits the potential exploitation of large numbers of concurrently-executing threads performing independent tasks in order to achieve economy of performance. The dearth of parallelism is attributable to all sorts of reasons, not the least of which being that parallel programming is hard. It really is.
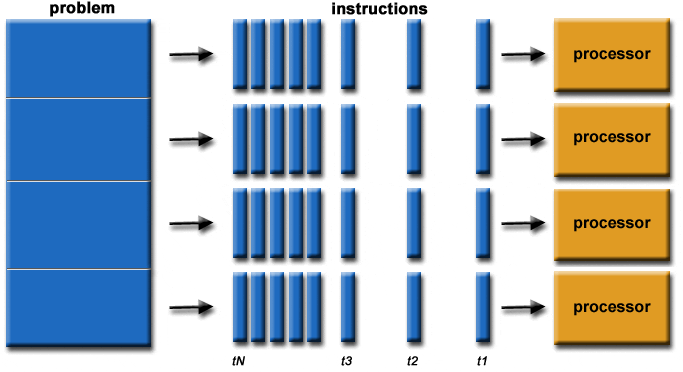
Fig. 1: Parallel Problem Overview.
Also, parallel processing is not magic, and cannot "just be used" in every situation; there are both practical and theoretical algorithmic design issues that must be considered when even thinking about incorporating parallel processing into a project. However, with Big Data encompassing such large amounts of data, sets of which are increasingly being relied upon for routine machine learning tasks, the trouble associated with parallelism may very well be worth it in a given situation due solely to the potential of dramatic time-savings related to algorithm execution.
General Purpose Computing on Graphics Processing Units
A contemporary favorite for parallelism in appropriate situations, and focus of this article, is utilizing general purpose computing on graphics processing units (GPGPU), a strategy exploiting the numerous processing cores found on high-end modern graphics processing units (GPUs) for the simultaneous execution of computationally expensive tasks. While not all machine learning tasks, or any other collection of software tasks for that matter, can benefit from GPGPU, there are undoubtedly numerous computationally expensive and time-monopolizing tasks to which GPGPU could be an asset. Modifying algorithms to allow certain of their tasks to take advantage of GPU parallelization can demonstrate noteworthy gains in both task performance and completion speed.
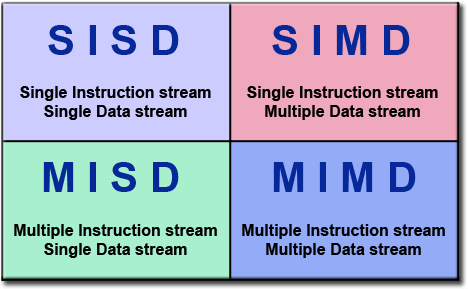
Fig. 2: Flynn's Taxonomy.
The GPGPU paradigm fits into Flynn’s taxonomy as single program, multiple data (SPMD) architecture, which differs from from the traditional multicore CPU computing paradigm.
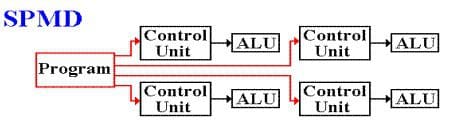
Fig. 3: Single Program Multiple Data (SPMD) subdivision of MIMD.
It should be noted that, while these modifications would undoubtedly benefit the processing of the very large datasets which are the very definition of Big Data, their implementation could have a positive effect on much smaller sets of data as well. A number of particular machine learning tasks can be computationally expensive and time-consuming regardless of data size. Parallelizing those which are not necessarily required to be executed in serial could potentially lead to gains for small datasets as well.
Machine learning algorithms could also see performance gains by parallelizing common tasks which may be shared among numerous algorithms, such as performing matrix multiplication, which is used by several classification, regression, and clustering techniques, including, of particular interest, linear regression.
An interesting sidenote relates to the theoretical expected speedup in task execution latency. Amdahl's Law states that the theoretical speedup of an entire task's execution increases with the incremental improvement of each system resource. However, regardless of the collective improvement's magnitude, theoretical speedup is limited by the consitutent task which cannot benefit from parallel improvements, or improves the least. The chain is only as strong (fast) as its weakest (slowest) link.
For an in-depth introductory treatment of generalized parallel computing, read this.
CUDA Parallel Programming Framework
The CUDA parallel programming framework from NVIDIA is a particular implementation of the GPGPU paradigm. CUDA once was an acronym for Compute Unified Device Architecture, but NVIDIA dropped the expansion and now just uses CUDA. This architecture, facilitating our machine learning parallelization via GPU acceleration (another way to refer to GPGPU), requires particular consideration in order to effectively manage available resources and provide the maximum execution speed benefit.
CUDA is technically a heterogeneous computing environment, meaning that it facilitates coordinated computing on both CPUs and GPUs. The CUDA architecture consists of hosts and devices, with host referring to a traditional CPU, and device referencing processors with large numbers of arithmetic units, typically GPUs. CUDA provides extensions to traditional programming languages (the native CUDA bindings are C, but have been ported or made otherwise available to many additional languages), enabling the creation of kernels, which are parallel-executing functions.
A kernel, when launched, gets simultaneously executed by a large number of CUDA device threads, a collection of which are referred to as a block of threads, blocks being collected into grids. Threads are arranged in 3-dimensional layouts within blocks, which are, in turn, arranged in 3-dimensional layouts within grids. Figure 4 demonstrates these relationships and layouts. The total number of threads, blocks, and grids employed by a particular kernel are strategically dictated by a programmer’s code executing on the host at kernel launch, based on given situational requirements.