Generative Adversarial Networks – Hot Topic in Machine Learning
What is Generative Adversarial Networks (GAN) ? A very illustrative explanation of GAN is presented here with simple examples like predicting next frame in video sequence or predicting next word while typing in google search.
By Al Gharakhanian.
NIPS2016 (Neural Information Processing System) is an annual event that attracts the best and the brightest of the field of Machine Learning both from academia as well as industry. I attended this event last week for the very first time and was blown away by the volume and diversity of the presentations. One unusual observation was that a large chunk of exhibitors were hedge funds in search of ML talent.
Some of the papers were highly abstract and theoretical while others quite pragmatic from the likes of Google, Facebook. The topics were wide-ranging but there were two topics stood out attracting a sizable attention.
The first was “Generative Adversarial Networks” (GANs for short), while the second was “Reinforcement Learning” (RL for short). My plan is to cover GANs in this post and hope to do the same for RL in a future post.
GAN is a relatively new Machine Learning architecture for neural networks pioneered by Ian Goodfellow and his colleagues at University of Montreal in 2014. In order to fully understand GANs, one has to understand the difference between Supervised and Unsupervised learning machines. Supervised machines are trained and tested based on large quantities of “labeled” samples. In other words, they require large datasets containing the “features” or “predictors” as well as its corresponding labels. As an example, a supervised image classifier engine would require a set of images with correct labels (e.g. cars, flowers, tables, . . .). Unsupervised learners don’t have this luxury and they learn on the job as they go. They learn from mistakes and try not to make similar errors in the future.
The disadvantage of supervised machines is their need for large sums of labeled data. Labeling large number of samples is costly and time consuming. Unsupervised learners don’t have this disadvantage but they tend to be less accurate. Naturally there is a strong motivation to improve the unsupervised machines and to lessen the reliance on the supervised ones. You can view GANs and RLs means of improving unsupervised machines (neural networks).
The second useful concept to remember is the concept of “Generative Models”. These are models that predict by generating the most likely outcome given a sequence of input samples. As an example, a generative model can generate the next likely video frame based on the previous frames. Another example is search engines that try to predict the next likely word before it is entered by the user.
Keeping these two concepts in mind, we now can tackle GANs. You can view a GAN as a new architecture for an unsupervised neural network able to achieve far better performance compared to traditional nets. To be more precise GANs are a new way of training a neural net. GANs contain not one but two independent nets that work separately and act as adversaries (see the diagram below). The first neural net is called the Discriminator (D) and is the net that has to undergo training. D is the classifier that will do the heavy lifting during the normal operation once the training is complete. The second network is called the Generator (G) and is tasked to generate random samples that resemble real samples with a twist rendering them as fake samples.
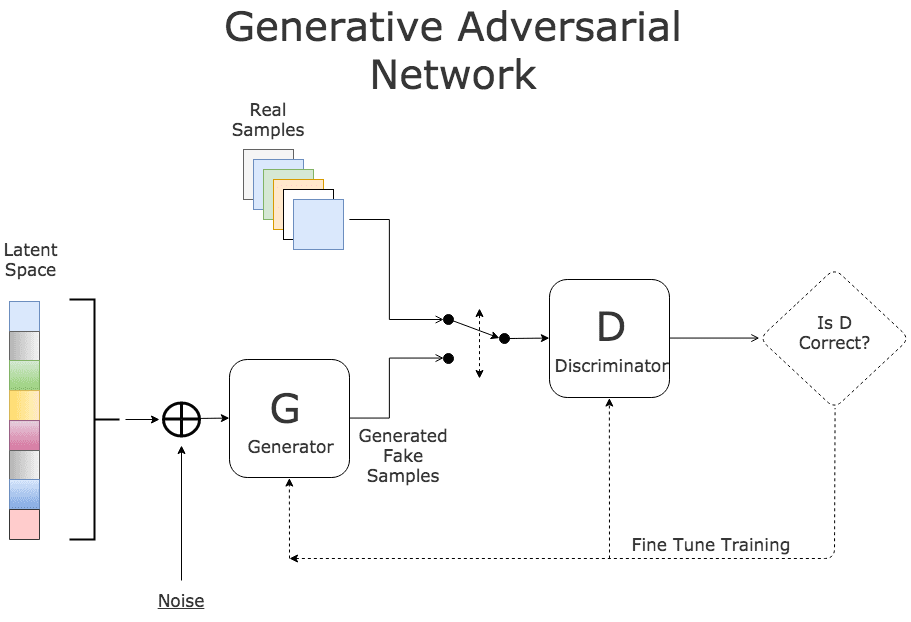
As an example, consider an image classifier D designed to identify a series of images depicting various animals. Now consider an adversary (G) with the mission to fool D using carefully crafted images that look almost right but not quite. This is done by picking a legitimate sample randomly from training set (latent space) and synthesizing a new image by randomly altering its features (by adding random noise). As an example, G can fetch the image of a cat and can add an extra eye to the image converting it to a false sample. The result is an image very similar to a normal cat with the exception of the number of eye.
During training, D is presented with a random mix of legitimate images from training data as well as fake images generated by G. Its task is to identify correct and fake inputs. Based on the outcome, both machines try to fine-tune their parameters and become better in what they do. If D makes the right prediction, G updates its parameters in order to generate better fake samples to fool D. If D’s prediction is incorrect, it tries to learn from its mistake to avoid similar mistakes in the future. The reward for net D is the number of right predictions and the reward for G is the number D’s errors. This process continues until an equilibrium is established and D’s training is optimized.
One of the weaknesses of early GANs was stability but we have seen very promising work that can alleviate this problem (details are beyond the scope of this post). In a way of an analogy, GANs act like the political environment of a country with two rival political parties. Each party continuously attempts to improve on its weaknesses while trying to find and leverage vulnerabilities in their adversary to push their agenda. Over time both parties become better operators.
As for the impact of RLs and GANs on semiconductors, both new architectures need significantly more gates, more CPU cycles, and more Memory. Nothing to complain about.
Original. Reposted by Permission.
Bio: Al Gharakhanian is well-rounded executive with extensive experience in Product Marketing, Sales, and Business Development in Semiconductors, Machine Learning, and Data Science.
Related: