Gartner Data Science Platforms – A Deeper Look
Thomas Dinsmore critical examination of Gartner 2017 MQ of Data Science Platforms, including vendors who out, in, have big changes, Hadoop and Spark integration, open source software, and what Data Scientists actually use.
By Thomas Dinsmore, analytics & machine Learning consultant.

Gartner recently released its 2017 Magic Quadrant for Data Science Platforms. You can get a copy directly from Gartner if you’re a client, or you can get one for free here, courtesy of SAS.
The figure below shows the 2016 and 2017 MQs side by side, with changes shown in red.
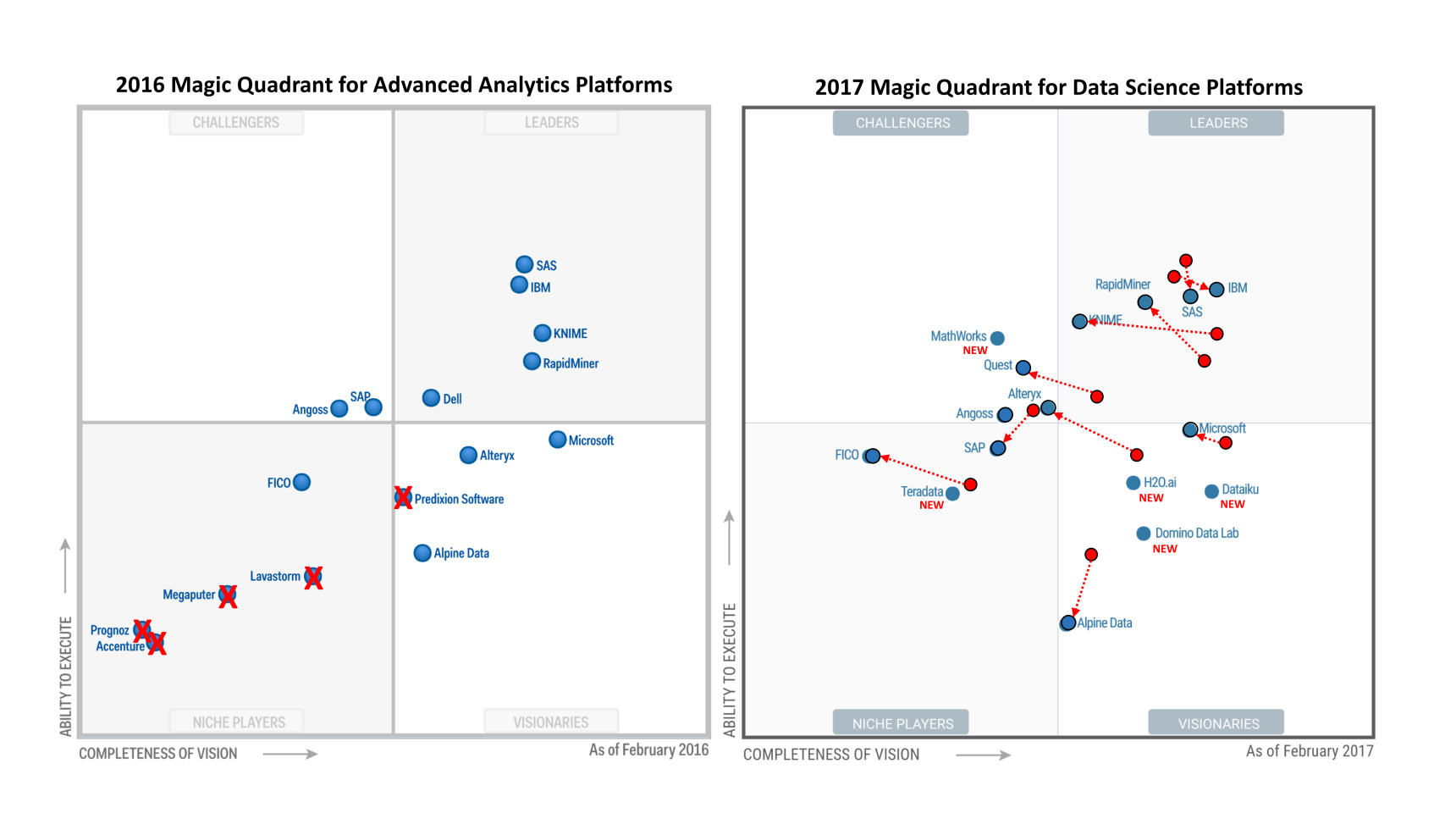
Here are my comments about the 2016 MQ, written last year.
Here is Gregory Piatetsky’s analysis.
And, here are 9 observations about the 2017 version:
(1) Five vendors are out.
Gartner drops the hammer on five of the weaker players.
— Accenture made the analysis last year, according to Gartner, because it acquired Milan-based i4C Analytics, a small Milan-based company. Accenture rebranded the software as the Accenture Analytics Applications Platform. However, it appears that Accenture gives away the software in bundled consulting deals since it reports no revenue from software licensing.
— Lavastorm is an ETL and data blending tool that does not claim to offer native predictive analytics, so its presence in last year’s MQ was and is a mystery.
— Megaputer, a text mining vendor, made it into the MQ for two years running despite being so marginal that they lack a record in Crunchbase. Last year, Gartner noted that “Megaputer scores low on viability and visibility and there is a lack of awareness of the company outside of text analytics in the advanced analytics market.” Which begs the question: why were they included in the first place?
— Prognoz appeared in the MQ for two years running and, like Megaputer, inspired WTF reactions from folks in the know. Primarily a BI tool with some time-series and analytics functionality included, Prognoz lacks the predictive analytics capabilities that Gartner says are minimally required. It also appears to lack customers West of Moscow.
— Predixion Software was acquired by Greenwave Systems in what seems to be a fire sale. So we won’t have Predixion to kick around anymore.
(2) Five new vendors are in.
Three real data science platforms enter the MQ this year as visionaries.
— Dataiku moved headquarters to New York earlier this year, so competitors can no longer dismiss it as “that French company.” The company markets Data Science Studio, a drag-and-drop interface that runs on top of open source platforms and has a slew of database connectors.
— Domino Data Lab is a data science platform with collaboration and reproducibility features. Originally marketed as a cloud-based managed service, Domino now offers its platform for on-premises implementation.
— H2O.ai develops and supports H2O, a scalable machine learning package. H2O.ai operates on a pure open source model, which makes it unique among the vendors included in this year’s MQ.
Mathworks is a welcome addition. According to IDC, it’s the #3 vendor in the advanced and predictive analytics segment, with 10% of the market, and it has held that position for years. Thus, its exclusion from the previous MQs is a mystery. Exactly how do you miss a vendor with a quarter-billion in category revenue? Just asking.
Teradata debuts as a niche vendor, thereby demonstrating the adage that the only thing worse than not making it into the Gartner MQ is to make it in as a niche vendor.
(3) Six vendors’ ratings changed markedly.
Six returning vendors declined markedly on one or both dimensions in Gartner’s assessment.
— Alpine continues to sink towards the bottom of the chart. Alpine’s close ties to Greenplum and EMC were once a feature, now a bug.
Due to its small size, Alpine is struggling to gain significant market visibility, which accounts for the drop in its Ability to Execute score. Of the vendors surveyed, it submitted the fewest reference customers, and 20% of those expressed concern about the small size of the community of users with whom they could network and share knowledge.
Recently, I asked an Alpine executive to disclose the company’s current customer count; he declined to do so. Since Alpine bragged about its 60 customers in 2015, I suspect that the comparison is not favorable.
— Alteryx and KNIME scored significantly lower on “Completeness of Vision” due to limited visualization tools and some scalability issues. These product attributes don’t change from year to year; the implication is that Gartner put more weight on them in this year’s MQ.
— FICO scored poorly on critical capabilities, open source tool support, algorithm selection, and innovation. It makes you wonder why anyone buys the software, or why FICO is still in the MQ.
— Quest (Statistica) declined because it’s hard to learn and use, has performance and stability issues, lacks key features, does not have an elastic cloud capability and lags in Spark integration. Other than that, it’s a winning product.
— RapidMiner‘s rating on “Ability to Deliver” increased, but its score on “Completeness of Vision” declined for no apparent reason.
(4) Hadoop and Spark integration are table stakes.
In the Market Overview section, Gartner writes:
All the vendors in this Magic Quadrant — indeed, in the market as a whole — have moved to include data in the open-source Hadoop ecosystem, which is now considered first-class. As such, it is equal in status to the proprietary stores that are predominantly used for traditional data warehouses.
Of course, while all vendors can use Hadoop as a data source, not all can leverage Hadoop as a computing platform. Moreover, vendors differ widely in their degree of integration with Hadoop.
Spark is becoming a de facto data science foundation for the vendors in this Magic Quadrant, as well as for other participants in this market.
Nick Heudecker, call your office.
Seven vendors in the 2016 MQ had no discernable Spark story. Five of them are now gone from the MQ. Pardon me while I take a victory lap.
(5) Gartner’s standards are strangely “flexible.”
Three examples:
Example 1: You can run an existing Python script in Enterprise Miner, and you can run an existing Python script in Alteryx. Neither application, however, provides authoring tools. This is rarely a problem since people who want to run a Python script usually already have a preferred IDE. Gartner singles out Alteryx, not SAS, however, for “lack of Python integration.”
Example 2: Microsoft Azure Machine Learning runs exclusively in Microsoft Azure cloud. IBM Data Science Experience (DSx) runs only in IBM Cloud. Gartner slams Azure Machine Learning for lacking an on-premises capability while praising DSx as “one of the most attractive platforms.”
Example 3: Statistica cannot push model training into Spark; neither can SAS Enterprise Miner. Gartner singles out Statistica for “lagging behind in Spark capabilities.”
(6) Data scientists don’t use Gartner’s top “data science” platforms.
If you wanted to create a Magic Quadrant based on the tools data scientists actually use, you might produce something like this:
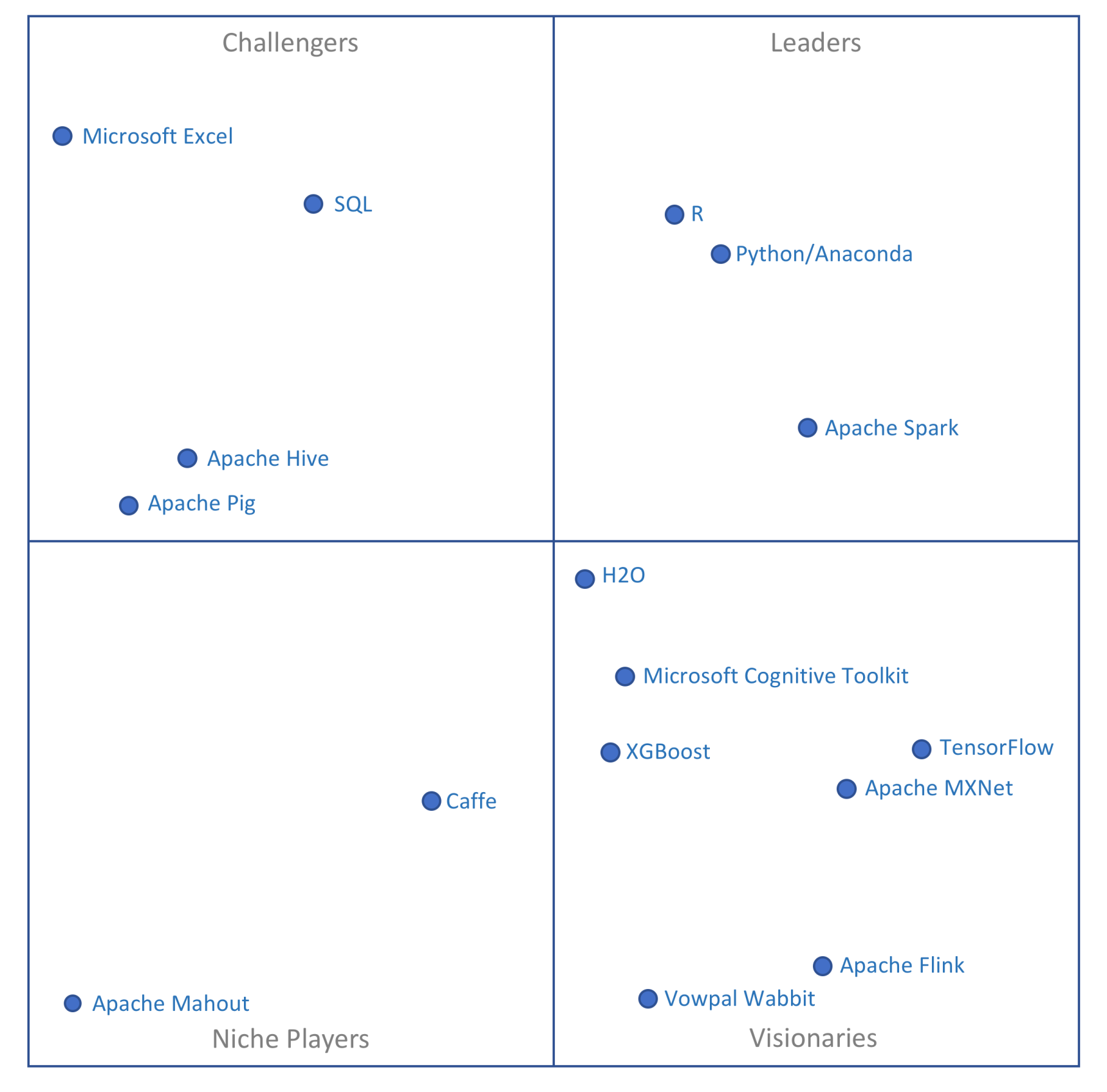
Just 5% of data scientists surveyed by O’Reilly use any SAS software, and 0% use any IBM analytics software. In the slightly broader KDnuggets poll, 6% use SAS Enterprise Miner, and 8% say they use IBM SPSS Modeler.
Gartner’s obsession with “Citizen Data Scientists” leads it to criticize Domino and H2O because they are “hard to use:”
Domino’s code-based approach requires the user to have significant technical knowledge.
Without programming skills, prospective users are likely to struggle to learn the H2O stack of products.
Imagine that! If you want to use a data science platform, you need to know how to do data science.
(7) Gartner is clueless about open source software.
Data scientists use open source software. Gartner seems to get that:
Open-source languages — Python, R and Scala — dominate this market. Almost all data science platform vendors support Python and R, and many of the vendors in this Magic Quadrant also support Scala.
But:
Gartner’s research methodology prevents evaluation of pure open-source platforms (such as Python and R) in a Magic Quadrant, as there are no vendors behind them that offer commercially licensable products.
That is BS on two levels.
First, it’s not true. Continuum Analytics distributes and supports Anaconda, the most widely used Python distribution for data science. Microsoft and Oracle distribute and support R, and there are ample community and vendor support resources. Multiple vendors support Apache Spark.
Second, while you can argue that commercial support is an important attribute of a data science platform, you can’t claim that it is the only attribute that matters. Many data scientists function quite well without vendor support. And some of the vendors Gartner rates as “leaders” offer low-quality support, so it doesn’t seem to carry much weight in the ratings.
(8) The assessments of SAS and IBM are misleading.
Gartner says that for SAS, it evaluated SAS Enterprise Miner and the SAS Visual Analytics suite. What Gartner does not say is that it is impossible for SAS to score highly on the functional assessment of those products alone. SAS’ score depends on many other SAS software products, including:
- SAS/ACCESS
- SAS Rapid Predictive Modeler
- SAS Factory Manager
- SAS High Performance Analytics
- SAS Model Manager
- SAS Scoring Accelerator
The Visual Analytics Suite runs on SAS’ proprietary LASR Server in-memory data store; to get data into that format, customers also need SAS Data Loader or SAS ETL Server.
Customers must license all of these products separately from SAS; doing so will more than triple the cost, and significantly increase the complexity of the architecture. Few SAS customers actually do this; about 15% of all SAS customers license SAS Enterprise Miner, and a tiny fraction of these customers license all of the software reflected in Gartner’s assessment.
The vast majority of SAS customers use its legacy software, whose code base dates to the mid-1990s. Thus, Gartner’s evaluation of SAS assumes a software configuration that hardly anyone uses.
The same story holds for IBM. Gartner rates IBM a leader on the strength of SPSS Modeler and, to a lesser extent, SPSS Statistics. Once again, however, the Gartner assessment depends on other IBM products. For example, Gartner praises IBM for its model management capabilities:
Surveyed IBM customers rated SPSS’s model management highly, with praise for its breadth of models, accuracy and transparency in workflows, model deployment, monitoring for degradation and automatic retuning. SPSS provides excellent features for analytics governance: versioning, metadata and audit capabilities.
That’s nice. Except that those features are not available in SPSS Modeler. To get them, customers must license IBM SPSS Collaboration and Deployment Services, an additional product. In a similar vein, Gartner lauds IBM’s integration with Hadoop. It’s a valuable capability, but it requires another product, IBM SPSS Analytics Server.
In short, by failing to disclose what products the customer must license to realize the attributed functionality, Gartner creates a false impression about the software most customers will actually license.
It’s like rating a hotel based solely on an examination of the Presidential Suite. Or evaluating a Chevrolet by test-driving a Cadillac.
(9) Gartner has a warm and fuzzy for IBM.
This gem lurks in the bowels of the report:
Customers are often confused by mismatches between (IBM’s) marketing messages and actual, purchasable products.
In other words, IBM is a giant hype machine. Gartner quaffs the Kool-Aid about IBM’s new Data Science Experience (DSx):
DSx is likely to be one of the most attractive platforms in the future — modern, open, flexible and suitable for a range of users, from expert data scientists to business people.
Keep in mind that DSx is a managed service for Spark and R in IBM Cloud. It includes Jupyter and RStudio IDEs. That’s all it is — a vanilla managed service, with fewer capabilities than managed services provided by Altiscale, Databricks, Domino, Microsoft Azure, or Qubole.
And, since it runs in IBM Cloud, there is about a 5% chance that any of your organization’s data is there already.
But Gartner thinks it will solve world hunger.
Most of IBM’s customers in this space use the legacy products, about which Gartner says this:
To many new users, IBM SPSS Modeler and Statistics seem outdated and overpriced.
IBM may be expensive, but you get blue-chip technical support, right?
Reference customers expressed dissatisfaction with IBM’s support and bureaucracy; they reported difficulties finding the right liaisons and technical help, despite high maintenance fees.
Okay, so the software is outdated and overpriced, and the support stinks. But you still get “white glove” service from IBM Client Executives, right?
Customers expressed concerns about purchasing products from IBM, as the company reportedly often tries to bring its consulting organization, IBM Global Business Services, into data science projects.
Other than that, IBM is a leader.
Original. Reposted with permission
Bio: Thomas W. Dinsmore, is a consultant, providing machine learning market insight to businesses and investors. He served as an analytics expert for The Boston Consulting Group; Director of Product Management for Revolution Analytics (Microsoft); Solution Architect for IBM Big Data (Netezza), SAS and PriceWaterhouseCoopers.
Related: