One Deep Learning Virtual Machine to Rule Them All
The frontend code of programming languages only needs to parse and translate source code to an intermediate representation (IR). Deep Learning frameworks will eventually need their own “IR.”

Credit: https://unsplash.com/search/machinery?photo=PmrwuizKUq0
The current state of Deep Learning frameworks is similar to the fragmented state before the creation of common code generation backends like LLVM. In the chaotic good old days, every programming language had to re-invent its way of generating machine code. With the development of LLVM, many languages now share the same backend code. Many programming languages use LLVM as their backend. Several well known examples of this are Ada, C#, Common Lisp, Delphi, Fortran, Haskell, Java bytecode, Julia, Lua, Objective-C, Python, R, Ruby, Rust, and Swift. The frontend code only needs to parse and translate source code to an intermediate representation (IR).
Deep Learning frameworks will eventually need their own “IR”. The IR for Deep Learning is of course the computational graph. Deep learning frameworks like Caffe and Tensorflow have their own internal computational graphs. These frameworks are all merely convenient fronts to the internal graph. These graphs specify the execution order of mathematical operations, analogous to what a dataflow graph does. The graph specifies the orchestration of collections of CPUs and GPUs. This execution is highly parallel. Parallelism is the one reason why GPUs are ideal for this kind of computation. There are however plenty of untapped opportunities to improve the orchestration between the CPU and GPU.
New research is exploring ways to optimize the computational graph in way that go beyond just single device optimization and towards more global multi-device optimization. An example of this is the research project XLA (Accelerated Linear Algebra) from Google. XLA supports both Just in Time (JIT) or Ahead of Time (AOT) compilation. It is a high level optimizer that performs its work in optimizing the interplay of GPUs and CPUs. The optimizations that are planned include the fusing of pipelined operations, aggressive constant propagation, reduction of storage buffers and fusing of low-level operators.

Google’s XLA
Not to be outdone, two other open source projects that are also exploring computational graph optimization. NNVM from MXNet (Supported by Amazon) is another computation graph optimization framework that similar to XLA focuses on the need for an intermediate representation. The goal of the NNVM optimizer is to reduce memory and device allocation while preserving the original computational semantics.

MxNet’s NNVM: http://tqchen.github.io/2016/10/01/build-your-own-tensorflow-with-nnvm-and-torch.html
NGraph from Intel is also exploring optimizations that include an even more extensive optimizations: kernel fusion, buffer allocation, training optimizations, inference optimizations, data layout and distributed training. There are certainly plenty of ideas of how to improve the performance and the space is heating up with a lot of activity.

Intel’s NGraph
In addition to these approaches that originate from the DL community, other approaches to optimizing machine learning algorithms have been developed by other companies. HP has developed the Cognitive Computing Toolkit(CCT) and IBM has developed SystemML.
HP’s CCT simplifies the development of HPC routines by compiling high-level abstractions down to optimized GPU kernels. Typically, the development of GPU kernels is a laborious process. However, if the algorithms can be expressed using combinations of high-level operators then it should be possible to generate the GPU kernel. This is what CCT is designed to do.
An offshoot of CCT is the Operator Vectorization Library (OVL). OVL is a python library that does the same a CCT but for TensorFlow framework. Custom TensorFlow operators are written in C++. OVL enables TensorFlow operators to be written in Python without sacrificing performance. This improves productivity and avoids the cumbersome process of implementing, building, and linking custom C++ and CUDA code.
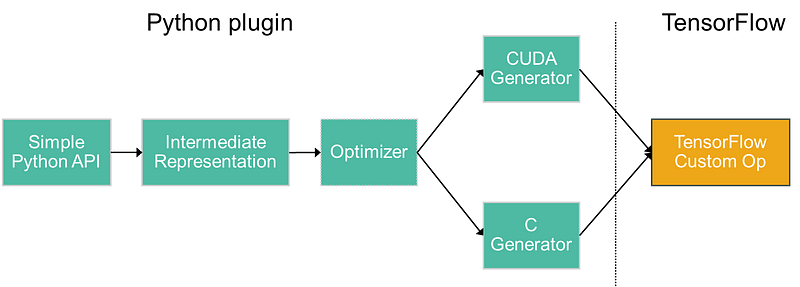
OVL
IBM’a SystemML is a high-level declarative language with an R-like and Python-like syntax. Developers express machine learning algorithms using these declarative language. SystemML takes care of generating the execution plan. The system supports optimizations on single nodes as well as distributed computations on platforms like Hadoop and Spark. Rule-based and cost-based optimization techniques are used to optimize the execution plan. SystemML comes with an existing suite of algorithms that include Descriptive Statistics, Classification, Clustering, Regression, Matrix Factorization, and Survival Analysis.
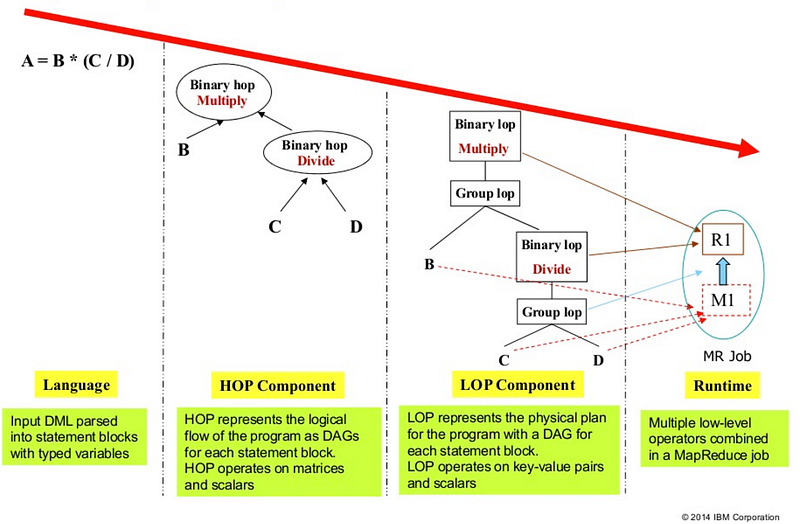
SystemML: source: https://www.slideshare.net/YunyaoLi/20140829declarative-thinkingfinal
These five open source projects (XLA, NNVM, NGraph, CCT and SystemML) all perform optimizations in a global manner across either the computational graph or an alternative declarative specification. The current DL frameworks however have code generation and execution all intertwined with their code base, making opportunities to develop optimization solutions less portable. Ideally, one would like to see a common standard, a DL virtual machine instruction set, where the community can collective contribute optimization routines. Right now however is is a competitive race to become the ruling standard. That is, one computational graph to rule them all. Can we not all band together for the common good?
A common standard deep learning virtual machine is a futuristic dream. One obvious idea is to leverage deep learning itself to optimize its own computations. That is, deep learning to “Learn to Optimize” itself. There have been current Meta-level research that are exploring this self-improvement approach, however, not at the level of fine-grained memory access and assembly level code.
Keep up with the updates in Deep Learning by signing up with our newsletter: https://www.getrevue.co/profile/intuitionmachine.
P.S. Should have included https://weld-project.github.io/ in this list.
Bio: Carlos Perez is a software developer presently writing a book on "Design Patterns for Deep Learning". This is where he sources his ideas for his blog posts.
Original. Reposted with permission.
Related: