5 Machine Learning Projects You Can No Longer Overlook, May
In this month's installment of Machine Learning Projects You Can No Longer Overlook, we find some data preparation and exploration tools, a (the?) reinforcement learning "framework," a new automated machine learning library, and yet another distributed deep learning library.
More overlooked machine learning and/or machine learning-related projects? Sounds great!
Let's do without the wordy intro this time, and simply say that projects are selected by no criteria other than they have caught my eye over time; really, any objective set of criteria would not work in this case. The only requriements are that the projects are open source and have Github repositories.
So here they are: 5 more... well, you know the rest. You may also remember that they are numbered not our of necessity related to relative ordering, but because my therapist suggests it's the best way to deal with my phobia of non-numbered lists.
"Create HTML profiling reports from pandas DataFrame objects," because the pandas describe() function is a bit under-powered. From the repo readme:
For each column the following statistics - if relevant for the column type - are presented in an interactive HTML report:
- Essentials: type, unique values, missing values
- Quantile statistics like minimum value, Q1, median, Q3, maximum, range, interquartile range
- Descriptive statistics like mean, mode, standard deviation, sum, median absolute deviation, coefficient of variation, kurtosis, skewness
- Most frequent values
- Histogram
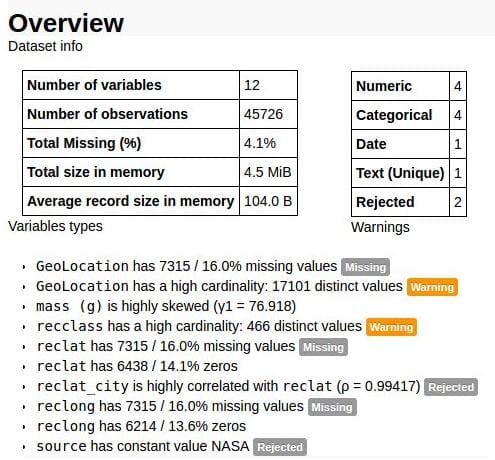
Easy to install and straight-forward to use, pandas-profiling could be a useful addition to any Pythonista's data exploration toolbox. Find a simple example using Jupyter notebook here. Alternatively, output can be piped to an HTML file for posterity.
Definitely worth consideration anyone wrangling and exploring data on a regular basis in the Python ecosystem and looking for some quick and dirty summarization.
2. Gym
You've heard of OpenAI's Gym... but what is it?
OpenAI Gym is a toolkit for developing and comparing reinforcement learning algorithms. This is the gym open-source library, which gives you access to an ever-growing variety of environments.
If you're serious about reinforcement learning, you already know. But if not:
gymmakes no assumptions about the structure of your agent, and is compatible with any numerical computation library, such as TensorFlow or Theano. You can use it from Python code, and soon from other languages.
OpenAI supplies the framework for your algorithms. It's scalable and flexible, and allows for playing everything from simple Flash and Atari games to board games and beyond. Find out more about Gym here. Find its docs here and a FAQ here. You can also read a whitepaper, found here.
If you don't know -- and really, why would you? -- I'm a fan of automated machine learning (AutoML). It's an area of machine learning (and data science) which shows massive future promise, and which is already paying dividends today. Projects like TPOT and auto-sklearn are great places to get your feet wet, and some of the first major steps in the direction of automating automation (though AutoML has been around for a long time).

Paypal's autosklearn-zeroconf is another project in this vein (and is actually based on the aforementioned auto-sklearn):
autosklearn-zeroconf is a fully automated binary classifier based on the AutoML challenge winner auto-sklearn. Give it a dataset with known outcomes (labels) and it tunes massively parallel ensembles of data sicence machine learning pipelines. As a result you get a list of predicted outcomes for your new data and an estimated prediction precision.
While I have not yet played with this project, I plan on doing so in the very near future and sharing what I find. In the meantime, I'm interested in hearing from anyone who has anything to say about it -- beyond that it looks like something we all want to try.
4. Dora
Dora. The Explorer. Right?
Directly from the Github readme:
Dora is a Python library designed to automate the painful parts of exploratory data analysis.
The library contains convenience functions for data cleaning, feature selection & extraction, visualization, partitioning data for model validation, and versioning transformations of data.
The library uses and is intended to be a helpful addition to common Python data analysis tools such as pandas, scikit-learn, and matplotlib.
It's simple to use, too. While it covers a lot of data prep ground, its versioning of data transformations looks especially novel. Check out Dora's easy-to-follow example code in the repo's readme.
5. BigDL
From Intel comes a(nother) deep learning framework, optimized for distribution over Apache Spark. From the readme:
BigDL is a distributed deep learning library for Apache Spark; with BigDL, users can write their deep learning applications as standard Spark programs, which can directly run on top of existing Spark or Hadoop clusters.
- Rich deep learning support
- Extremely high performance
- Efficiently scale-out
Need some reason as to why you might choose BigDL over the plethora of other already available deep learning libraries? This slide from a presentation on the topic might help:

Check out the Getting Started guide for a quick overview. The API guide can be found here.
Related: