 Apache Flink: The Next Distributed Data Processing Revolution?
Apache Flink: The Next Distributed Data Processing Revolution?
 Apache Flink: The Next Distributed Data Processing Revolution?
Apache Flink: The Next Distributed Data Processing Revolution?Will Apache Flink displace Apache Spark as the new champion of Big Data Processing? We compare Spark and Apache Flink performance for batch processing and stream processing.
By Kevin Jacobs, Data Blogger.
Disclaimer: The results are valid only in the case when network attached storage is used in the computing cluster.
The amount of data is growing significantly over the past few years. It is not feasible for only one machine to process large amounts of data. Therefore, the need of distributed data processing frameworks is growing. It all started back in 2011 when the first version of Apache Hadoop was released (version 1.0.0). The Hadoop framework is capable of storing a large amount of data on a cluster. This is known as the Hadoop File System (HDFS) and it is used at almost every company which has the burden to store Terabytes of data every day. Then the next problem arose: how can companies process all the stored data? Here is where Distributed Data Processing frameworks come into play. In 2014, Apache Spark was released and it now has a large community. Almost every IT section has implemented at least some lines of Apache Spark code. Companies gathered more and more data and the demand for faster data processing frameworks is growing. Apache Flink (released in March 2016) is a new face in the field of distributed data processing and is one answer to the demand for faster data processing frameworks.
Fundamental difference: Streams versus Batches
There are two different types of data. Most people are familiar with data batches. It are finite chunks of data and one example of a batch is a file. Let’s take a look at the following example:

It visualizes a batch as beer. The beer (or the batch) can only be consumed when the glass is full. This introduces latency for consuming the drink.
The other type of data are data streams. Data streams can be visualized by water flowing from a tap to a sink. This process is not ending. The nice property of streams is that you can consume the stream while it is flowing. There is almost no latency involved for consuming a stream.
Apache Spark is fundamentally based on batches of data. By that, for all processing jobs at least some latency is introduced. Apache Flink on the other hand is fundamentally based on streams. Let’s take a look at some evidence for the difference in latency.
Comparing Stream Performance
What makes a good data processing framework? One term for measuring the performance of such a framework is latency. The lower the latency, the faster the framework processes new information in a data stream. I performed an experiment in which I captured the latency for both Apache Flink and Apache Spark.
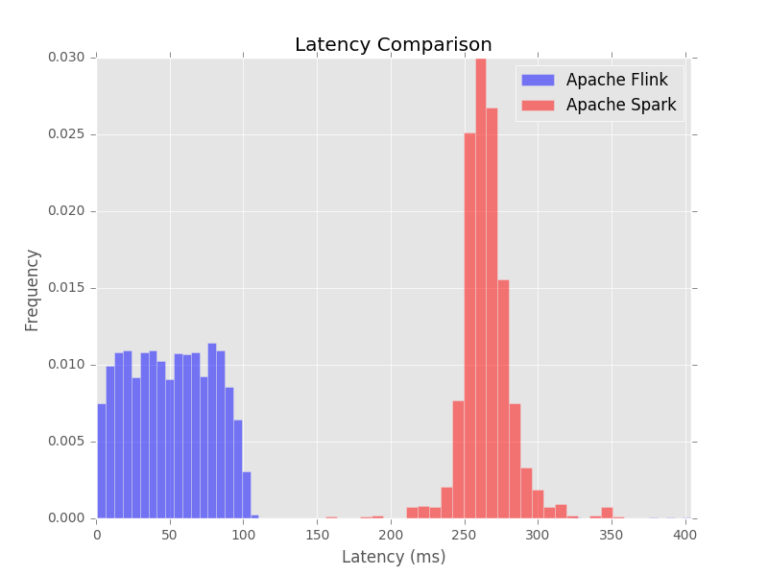
As expected, from the graph can be seen that Apache Spark has more latency than Apache Flink. This is mainly due to the fact that Apache Spark is based on batches. Apache Flink almost immediately processes the data and for Apache Spark it takes about 260 milliseconds to process data.
In the experiment I generated streams bitstrings. Bitstrings are sequences of “0” and “1”s. For example, a bitstring of length 3 could be “011”. Many bitstrings were generated and a very basic Apache Spark job and Apache Flink job where processing the bitstrings. The jobs are functionally equivalent. Then, I measured how long it took for both Apache Spark and Apache Flink to process a bitstring from the stream of bitstrings. The full details of the latency experiment can be found in the report.
Comparing Batch Performance
Some tasks are based on data batches. Therefore, it is good to know the performance of a data processing framework in terms of execution time for a batch processing job.
TeraSort is such a task in which jobs have to sort a large amount of data. In my setup, I used a cluster consisting of 11 nodes (44 CPUs, 2.5TB of HDFS storage and 77GB of memory) to measure the execution time for sorting 100GB of data. Network attached storage is used in the cluster. I used Ganglia for measuring the resource usage during the experiment. One note here is that the cluster is also used for other purposes by other people. I made multiple measurements to reduce the noise introduced by this fact.
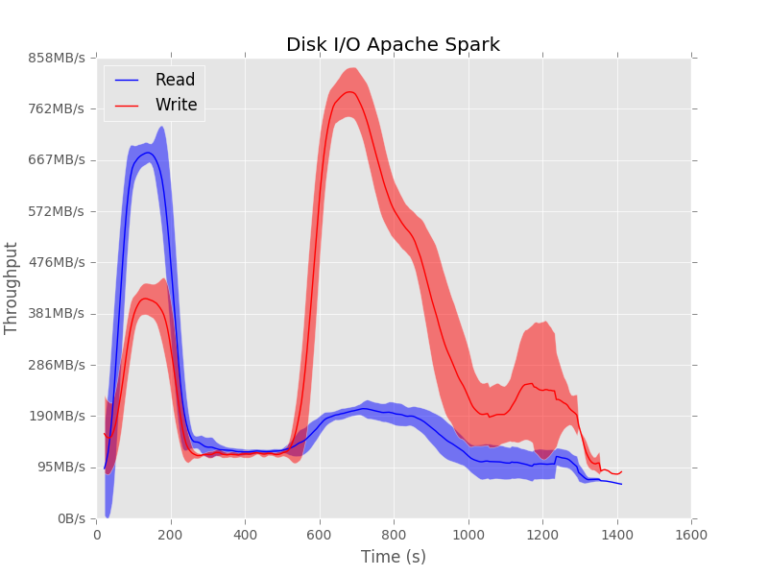
For Apache Spark, it can be seen that it is reading and writing a lot in the beginning of the job. Then, the data is send over the network and sorted and finally written back to disk.
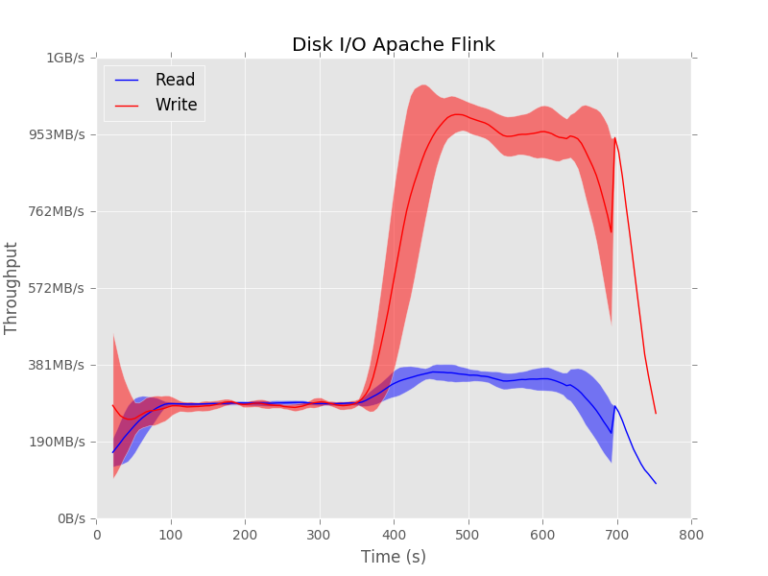
Apache Flink uses the disk more consistently. It can be seen that there is a constant amount of reading and that the writing only takes place when the sorted data is received.
The same patterns can be seen for the network usage:
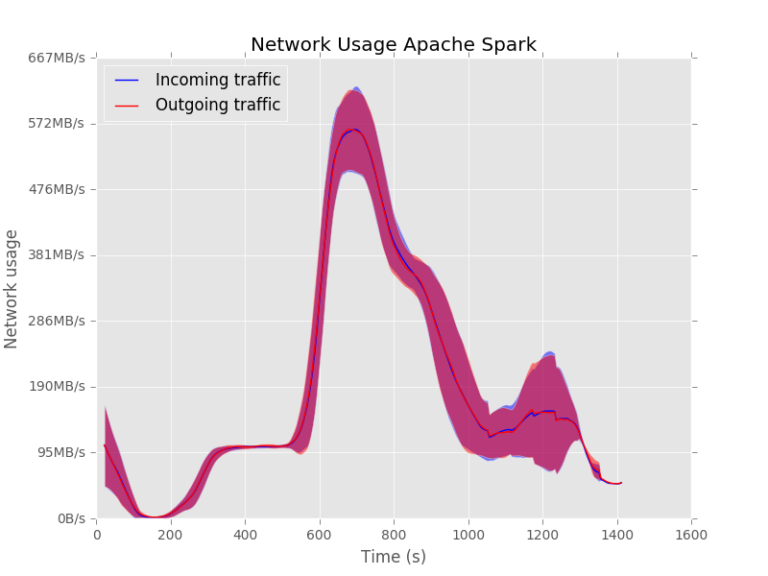
Apache Spark is not sending anything over the network in the beginning. This causes some delay in the execution of the task since it is not using the resources optimally.
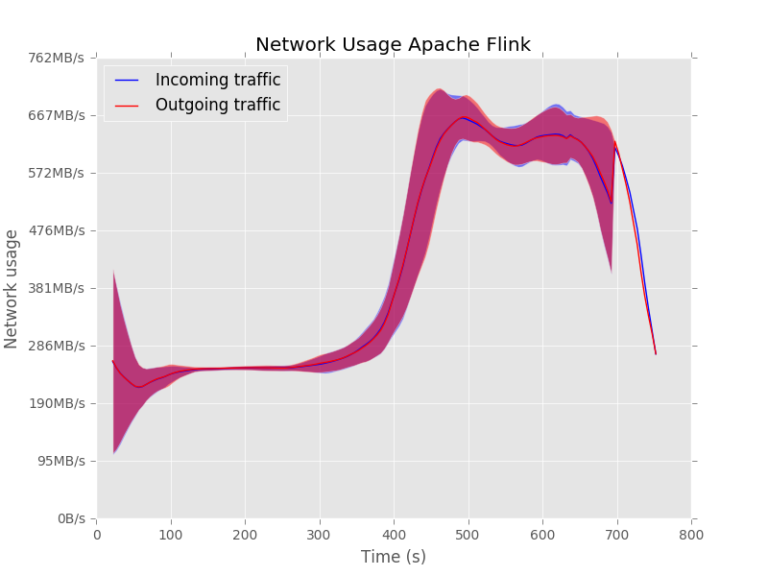
Apache Flink uses the network from the beginning.
To summarize, it is clear that Apache Flink uses its resources better than Apache Spark does. This also results in a smaller execution time for Apache Flink for the same job. This is summarized in the next graph. Please keep in mind that network attached storage is used during the experiment.

The whole environment is the same. The only difference is the data processing framework that was used. Apache Flink does the job in almost half of the time compared to Apache Spark.
The complete results of the experiment and the setup of the experiment can be found in the report.
Conclusion
Besides the fact that the API of Apache Flink is in my opinion easier to use than the API of Apache Spark and besides the fact that Apache Flink has a more flexible windowing system than Apache Spark it is also much faster then Apache Spark when network attached storage (NAS) is used in the computing cluster. In terms of batch processing, Apache Flink is also faster and it is about twice as fast as Apache Spark with NAS. Apache Flink has almost no latency in processing elements from a stream compared to Apache Spark.
Therefore I would like to conclude with the words that you should start using Apache Flink as main distributed datastream processing framework! Or at least have a look at it. If you have any questions or if you would like to start a discussion, feel free to give your opinion in the discussion section.
Original. Reposted with permission.
Bio: Kevin Jacobs is a certified Data Scientist and blog writer for Data Blogger. He is passionate about any project that involves large amounts of data and statistical data analysis. Kevin can be reached using Twitter (@kmjjacobs), LinkedIn or via e-mail:
mail@kevinjacobs.nl.
Related: