How Feature Engineering Can Help You Do Well in a Kaggle Competition – Part 3
In this last post of the series, I describe how I used more powerful machine learning algorithms for the click prediction problem as well as the ensembling techniques that took me up to the 19th position on the leaderboard (top 2%)
By Gabriel Moreira, CI&T.

In the first and second parts of this series, I introduced the Outbrain Click Prediction machine learning competition and my initial tasks to tackle the challenge. I presented the main techniques used for exploratory data analysis, feature engineering, cross-validation strategy and modeling of baseline predictors using basic statistics and machine learning.
In this last post of the series, I describe how I used more powerful machine learning algorithms for the click prediction problem as well as the ensembling techniques that took me up to the 19th position on the leaderboard (top 2%).
Follow-the-Regularized-Leader
One of the popular approaches for CTR Prediction is Logistic Regression with a Follow-the-Regularized-Leader (FTRL) optimizer, which have been used in production by Google to predict billions of events per day, using a correspondingly large feature space.
It is a linear model with a lazy representation of the coefficients (weights) and, in conjunction with L1 regularization, it leads to very sparse coefficient vectors. This sparsity property shrinks memory usage, making it scalable for feature vectors with billions of dimensions, because each instance will typically have only a few hundreds of nonzero values. FTRL provides efficient training on large datasets by streaming examples from disk or over the network — each training example only needs to be processed once (online learning).
I tried two different FTRL implementations, available in Kaggler and Vowpal Wabbit (VW) frameworks.
For CTR prediction, it is important to understand the interactions between the features. For example, the average conversion of an ad from “Nike” advertiser might be very different, depending on the publisher that is displaying the ad (e.g. ESPN vs. Vogue).
I considered all categorical features for models trained on Kaggler FTRL. The feature interactions option was enabled, meaning that for all possible two-paired feature combinations, feature values were multiplied and hashed (read about Feature Hashing in the first post) to a position in a sparse feature vector with dimension of 2²⁸. This was my slowest model and the training time took more than 12 hours. But my LB score jumped to 0.67659 for this Approach #6.
I also tried FTRL on VW, which is a very fast and efficient framework in the usage of CPU and memory resources. The input data was again categorical features, with the addition of some selected numeric binned features (read about Feature Binning in the first post). My best model was trained in two hours and lead to a LB score of 0.67512 in this Approach #7. The accuracy was a little bit lower, but much faster than the previous model.
In a second FTRL model on VW, I used a VW hyperparameter to configure interactions (feature pairing) of only a subset of features (namespace). In this case, interactions paired only categorical features and some selected numeric features (without binning transformation). That change lead to a better mode in this Approach #8: 0.67697.
All those three FTRL models were ensembled for my final submissions, as we’ll describe in next sections.
Field-aware Factorization Machines
A recent variant of Factorization Machines, named Field-aware Factorization Machines (FFM) was used in winning solutions for two CTR prediction competitions in 2014. FFM tries to model feature interactions by learning latent factors for each features interaction pair. This algorithm was made available as the LibFFM framework and used by many competitors. LibFFM makes a very efficient usage of parallel processing and memory for large datasets.
In the Approach #9, I used categorical features with paired-interactions hashed to a dimensionality of 700,000. My best model took me only 37 minutes to train and it turned out to be my best single model, with a LB score of 0.67932.
In Approach #10, the input data contained some selected binned numeric features in addition to categorical features. Training data increased to 214 minutes, and LB score was 0.67841.
For Approach #11, I tried to train a FFM model considering only the last 30% of events of the training set, under the hypothesis that training on the last days could improve the prediction of the next two days (50%) of test set. The LB score was 0.6736, increasing accuracy for those two last days, but decreasing accuracy for previous events of test set.
In Machine Learning projects it is not rare that some promising approaches end up failing miserably. That happened with some FFM models. I tried to transfer learning from a GBDT model to a FFM model with leaf encoding, a winning approach in a Criteo competition. However, the FFM model accuracy dropped, probably because the GBDT model was not accurate enough in this context, adding more noise than signal.
Another unsuccessful approach was to train separate FFM models, specific for geographic regions with more events in test dataset, like some countries (US ~ 80%, CA ~ 5%, GB ~ 5%, AU ~ 2%, Others ~ 8%) and U.S. states (CA ~ 10%, TX ~ 7%, FL ~ 5%, NY ~ 5%). To generate predictions, each event of test set was sent to the model specialized on those region. Models specialized to the U.S. performed well predicting clicks for that region, but for other regions the accuracy was lower. Thus, using world-wide FFM models performed better.
The three selected FFM approaches were used in my final ensemble, as I show next.
Ensembling methods
Ensembling methods consist of combining predictions from different models to increase accuracy and generalization. The less correlated models' predictions are, the better the ensemble accuracy may be. The main idea behind ensembling is that individual models are influenced not only by signal, but also by random noise. Taking a diverse set of models and by combining their predictions, considerable noise may be cancelled, leading to better model generalization, like shown below.
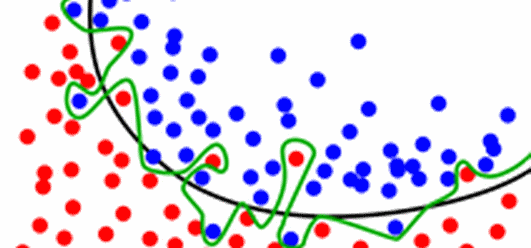
From the competition Don’t overfit
A simple, yet powerful, ensembling approach is to merge models predictions by averaging. For this competition, I tested many types of weighted averages types like Arithmetic, Geometric, Harmonic and Ranking averages, among others.
The best approach I could find was to use a Weighted Arithmetic Average of the logit (inverse of sigmoidal logistic) of predicted CTR (probabilities), shown in Equation 1. It considered predictions of the three selected FFM models (Approaches #9, #10, and #11) as well as one the FTRL models (Approach #6). Such averaging gave me a LB score of 0.68418 for this Approach #12, a nice jump from my best single model (Approach #10, with a score of 0.67932).
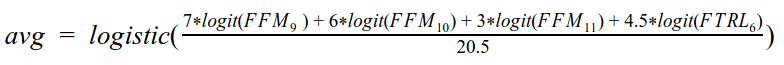
Equation 1 — Ensembling by Weighted Average of logit of models predictions
At that time, competition submission deadline was only a few days away. My choice for the remaining time was to ensemble using a Learning-to-Rank model to merge up best models predictions.
That model was a GBDT with 100 trees and ranking objective using XGBoost. This ensemble considered as input features the best 3 FFM and 3 FTRL model predictions as well as 15 selected engineered numeric features (like user views count, user preference similarity and average CTR by categories).
That ensemble layer was trained only using validation set data (described in the second post), in a setting named Blending. The reason for that approach is that if predictions for train set were also considered by ensemble model, it would prioritize more overfitted models, reducing its ability to generalize for the test set. In the last competition day, Approach #13 gave me my best Public LB score (0.68688). The competition then finished, my Private LB Score was revealed (0.68716) and kept me at 19th position in the final leaderboard, as illustrated below.
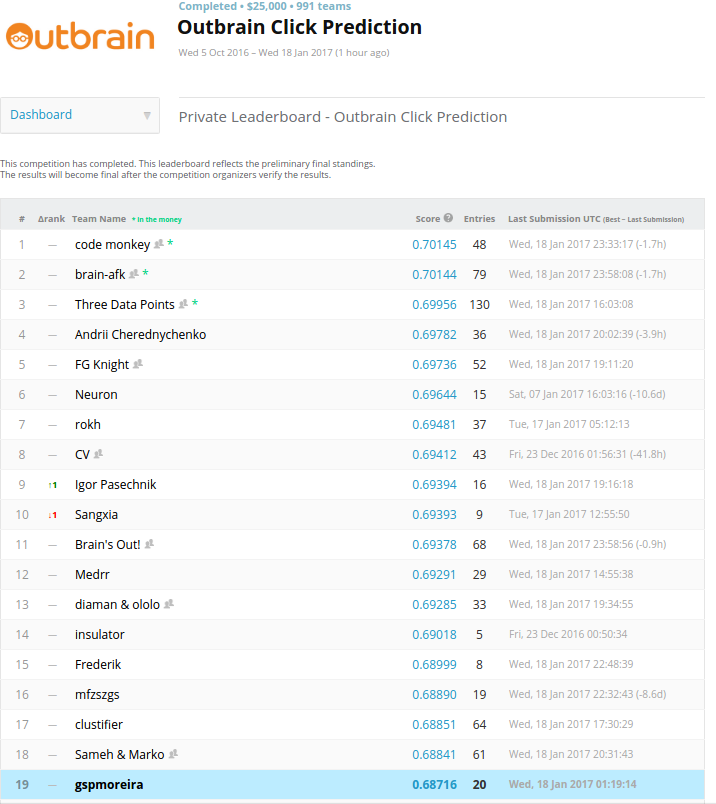
Kaggle’s Outbrain Click Prediction final leaderboard
I have not tracked the exact submission days, but the graph below gives a sense of how my LB scores evolved during the competition. It can be seen that first submissions provided nice jumps on the score, but improving upon that became harder, which is quite common in machine learning projects.
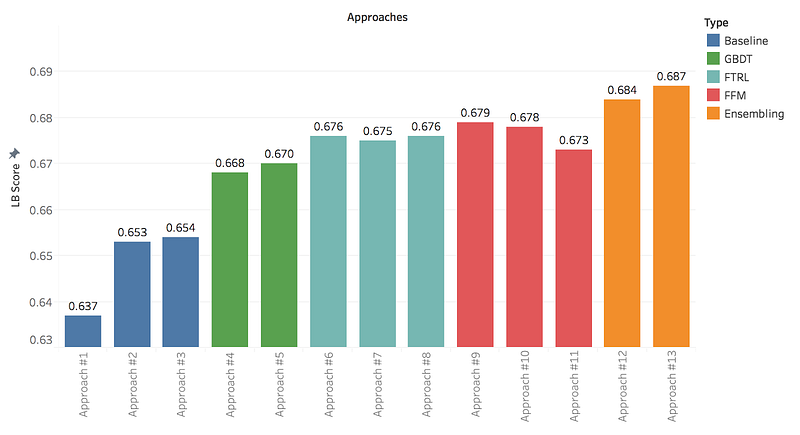
LB scores for my approaches during competition
Conclusions
Some of the things I learned from this competition were:
- A good Cross-Validation strategy is essential for competing.
- One should spend a good chunk of time in feature engineering. Adding new features on datasets afterwards requires much more effort and time.
- Hashing is a must for sparse data. In fact, it performed better than One-Hot Encoding (OHE) in terms of simplicity and efficient.
- OHE categorical features were not optimal for decision trees ensembles. Based on competitors shared experiences, tree ensembles could perform better with original categorical values (ids) with enough trees, because it would reduce feature vectors to a much lower dimensionality, increasing the chance that the random feature sets contained more predictive features.
- Testing many different frameworks is great for learning, but usually takes tons of time to transform data to the required format, read documentation and tune hyperparameters.
- Reading scientific papers about the main techniques (FTRL and FFM) were essential for guidance on hyperparameter tuning.
- Studying forums posts, public Kernels (shared code) and past solutions shared by competitors was great way to learn and is essential for competing. Everyone should share something back!
- Ensembling based on average improves accuracy a lot, blending with ML models leverages the bar, and stacking is a must. I had not time to explore stacking, but according to other competitors, using out-of-fold predictions on fixed folds increases the available data for ensemble training (full train set) and improves final ensemble accuracy.
- One shouldn't leave generating one's submission files until the final hours of the competition!
Kaggle is like a university for cutting-edge machine learning, for those who decide to embrace the challenges and learn from the process and peers. It was a highly engaging experience to compete against and learn from world-class data scientists.
Google Cloud Platform was a great hiking partner during that journey, providing all the necessary climbing tools to overcome cliffs of big data and distributed computing, while my focus and effort was directed to get to the top of the mountain.
Bio: Gabriel Moreira is a scientist passionate about solving problems with data. He is a Doctoral student at Instituto Tecnológico de Aeronáutica - ITA, researching on Recommender Systems and Deep Learning. Currently, he is Lead Data Scientist at CI&T, leading the team in the solution of customer's challenging problems using machine learning on big and unstructured data.
Original. Reposted with permission.
Related: