How Convolutional Neural Networks Accomplish Image Recognition?
Image recognition is very interesting and challenging field of study. Here we explain concepts, applications and techniques of image recognition using Convolutional Neural Networks.
By Savaram Ravindra, Mindmajix.com
What is Image Recognition and why is it Used?
In the context of machine vision, image recognition is the capability of a software to identify people, places, objects, actions and writing in images. To achieve image recognition, the computers can utilise machine vision technologies in combination with artificial intelligence software and a camera.
While it is very easy for human and animal brains to recognize objects, the computers have difficulty with the same task. When we look at something like a tree or a car or our friend, we usually don’t have to study it consciously before we can tell what it is. However, for a computer, identifying anything(be it a clock, or a chair, human beings or animals) represents a very difficult problem and the stakes for finding a solution to that problem are very high.
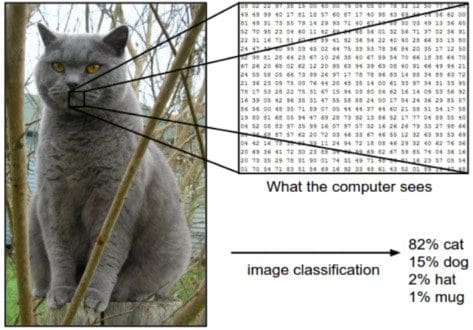
Image: CS231.github
Image recognition is a machine learning method and it is designed to resemble the way a human brain functions. With this method, the computers are taught to recognize the visual elements within an image. By relying on large databases and noticing emerging patterns, the computers can make sense of images and formulate relevant tags and categories.
Popular Application of Image Recognition
Image recognition has various applications. The most common as well as popular among them is personal photo organization. Who wouldn’t like to better manage a huge library of photo memories according to visual topics, from particular objects to wide landscapes?
The user experience of photo organization applications is being empowered by image recognition. In addition to providing a photo storage, the apps want to go a step further by providing people with much better discovery and search functions. They can attain that with the capabilities of automated image organization provided by machine learning. The image recognition application programming interface integrated in the applications classifies the images based on identified patterns and groups them thematically.
The other applications of image recognition include stock photography and video websites, interactive marketing and creative campaigns, face and image recognition on social networks and image classification for websites with huge visual databases.
Image Recognition is a Tough Task to Accomplish
Image recognition is not an easy task to achieve. A good way to think about achieving it is through applying metadata to unstructured data. Hiring human experts for manually tagging the libraries of music and movies may be a daunting task but it becomes highly impossible when it comes to challenges such as teaching the driverless car’s navigation system to differentiate pedestrians crossing the road from various other vehicles or filtering, categorizing or tagging millions of videos and photos uploaded by the users that appear daily on social media.
One way to solve this problem would be through the utilization of neural networks. We can make use of conventional neural networks for analyzing images in theory, but in practice, it will be highly expensive from a computational perspective. Take for example, a conventional neural network trying to process a small image(let it be 30*30 pixels) would still need 0.5 million parameters and 900 inputs. A reasonably powerful machine can handle this but once the images become much larger(for example, 500*500 pixels), the number of parameters and inputs needed increases to very high levels.
There is another problem associated with the application of neural networks to image recognition: overfitting. In simple terms, overfitting happens when a model tailors itself very closely to the data it has been trained on. Generally, this leads to added parameters(further increasing the computational costs) and model’s exposure to new data results in a loss in the general performance.
Convolutional Neural Networks

Convolutional Neural Network Architecture Model
Image: Parse
To the way a neural network is structured, a relatively straightforward change can make even huge images more manageable. The result is what we call as the CNNs or ConvNets(convolutional neural networks).
The general applicability of neural networks is one of their advantages, but this advantage turns into a liability when dealing with images. The convolutional neural networks make a conscious tradeoff: if a network is designed for specifically handling the images, some generalizability has to be sacrificed for a much more feasible solution.
If you consider any image, proximity has a strong relation with similarity in it and convolutional neural networks specifically take advantage of this fact. This implies, in a given image, two pixels that are nearer to each other are more likely to be related than the two pixels that are apart from each other. Nevertheless, in a usual neural network, every pixel is linked to every single neuron. The added computational load makes the network less accurate in this case.
By killing a lot of these less significant connections, convolution solves this problem. In technical terms, convolutional neural networks make the image processing computationally manageable through filtering the connections by proximity. In a given layer, rather than linking every input to every neuron, convolutional neural networks restrict the connections intentionally so that any one neuron accepts the inputs only from a small subsection of the layer before it(say like 5*5 or 3*3 pixels). Hence, each neuron is responsible for processing only a certain portion of an image.(Incidentally, this is almost how the individual cortical neurons function in your brain. Each neuron responds to only a small portion of your complete visual field).
The Working Process of a Convolutional Neural Network
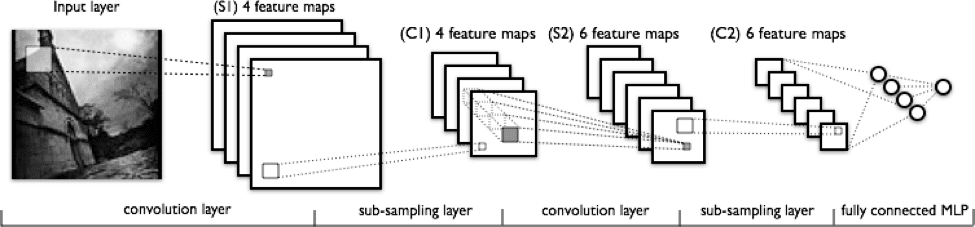
Image: deeplearning4j
From left to right in the above image, you can observe:
- The real input image that is scanned for features. The filter that passes over it is the light rectangle.
- The Activation maps are arranged in a stack on the top of one another, one for each filter you use. The larger rectangle is 1 patch to be downsampled.
- The activation maps condensed via downsampling.
- A new group of activation maps generated by passing the filters over the stack that is downsampled first.
- The second downsampling – which condenses the second group of activation maps.
- A fully connected layer that designates output with 1 label per node.
How does a CNN filter the connections by proximity? The secret is in the addition of 2 new kinds of layers: pooling and convolutional layers. We will break the process down below, utilising the example of a network that is designed to do just one thing, i.e, to determine whether a picture contains a grandpa or not.
The first step in the process is convolution layer which in turn has several steps in itself.
- At first, we will break down grandpa’s picture into a series of overlapping 3*3 pixel tiles.
- After that, we will run each of these tiles via a simple, single-layer neural network by keeping the weights unaltered. This will change the collection of tiles into an array. As we kept each of the images small(3*3 in this case), the neural network needed to process them stays manageable and small.
- Then, the output values will be taken and arranged in an array that numerically represents each area’s content in the photograph, with the axes representing color, width and height channels. So, for each tile, we would have a 3*3*3 representation in this case. (We would throw in a fourth dimension for time if we were talking about the videos of grandpa).
The next step is the pooling layer. It takes these 3 or 4 dimensional arrays and applies a downsampling function together with spatial dimensions. The result is a pooled array that contains only the image portions that are important while discarding the rest, which minimizes the computations that are needed to be done while also avoiding the overfitting problem.
The downsampled array is taken and utilized as the regular fully connected neural network’s input. Since the input’s size has been reduced dramatically using pooling and convolution, we must now have something that a normal network will be able to handle while still preserving the most significant portions of data. The final step’s output will represent how confident the system is that we have the picture of a grandpa.
In real life, the process of working of a CNN is convoluted involving numerous hidden, pooling and convolutional layers. In addition to this, the real CNNs usually involve hundreds or thousands of labels rather than just a single label.
How to Build a Convolutional Neural Network?
Building a CNN from scratch can be an expensive and time–consuming undertaking. Having said that, a number of APIs have been developed recently developed that aim to enable the organizations to glean insights without the need of in-house machine learning or computer vision expertise.
Google Cloud Vision
Google Cloud Vision is the visual recognition API of Google and uses a REST API. It is based on the open-source TensorFlow framework. It detects the individual faces and objects and contains a pretty comprehensive label set.
IBM Watson Visual Recognition
IBM Watson Visual Recognition is a part of the Watson Developer Cloud and comes with a huge set of built-in classes but is built really for training custom classes based on the images you supply. It also supports a number of nifty features including NSFW and OCR detection like Google Cloud Vision.
Clarif.ai
Clarif.ai is an upstart image recognition service that also utilizes a REST API. One interesting aspect regarding Clarif.ai is that it comes with a number of modules that are helpful in tailoring its algorithm to specific subjects such as food, travel and weddings.
While the above APIs are suitable for few general applications, you might still be better off developing a custom solution for specific tasks. Fortunately, a number of libraries are available that make the lives of developers and data scientists a little easier by dealing with the optimization and computational aspects allowing them to focus on training models. Many of these libraries including Theano, Torch, DeepLearning4J and TensorFlow have been successfully used in a wide variety of applications.
An Interesting Application of Convolutional Neural Networks
Adding Sounds to Silent Movies Automatically
To match a silent video, the system must synthesize sounds in this task. The system is trained utilizing thousand video examples with the sound of a drum stick hitting distinct surfaces and generating distinct sounds. A deep learning model associates the video frames with a database of pre-recorded sounds to choose a sound to play that perfectly matches with what is happening in the scene. The system will then be evaluated with the help of a set-up which resembles a turing-test where humans have to determine which video has the fake(synthesized) or real sounds. This is a very cool application of convolutional neural networks and LSTM recurrent neural networks. Check out the video here.
Bio: Savaram Ravindra was born and raised in Hyderabad, India and is now a Content Contributor at Mindmajix.com. Previously, he was a Programmer Analyst at Cognizant Technology Solutions. He has MS degree in Nanotechnology from VIT University. Contact him at savaramravindra4@gmail.com.
Related: