How To Write Better SQL Queries: The Definitive Guide – Part 2
Most forget that SQL isn’t just about writing queries, which is just the first step down the road. Ensuring that queries are performant or that they fit the context that you’re working in is a whole other thing. This SQL tutorial will provide you with a small peek at some steps that you can go through to evaluate your query.
By Karlijn Willems, Data Science Journalist & DataCamp Contributor.
Editor's note: This post is a continuation of part one, which was posted yesterday and can be found here. While the content herein can be considered independent of the first, reading part one before moving one would most certainly be of benefit.
The introductory paragraph of the first post is shown below in order to set the general mood of the tutorial.
Structured Query Language (SQL) is an indispensable skill in the data science industry and generally speaking, learning this skill is fairly easy. However, most forget that SQL isn’t just about writing queries, which is just the first step down the road. Ensuring that queries are performant or that they fit the context that you’re working in is a whole other thing.
Set-based versus Procedural Approaches to Querying
What was implicit in the above anti-patterns is the fact that they actually boil down to the difference in set-based versus procedural approach to building up your queries.
The procedural approach of querying is an approach that is much like programming: you tell the system what to do and how to do it.
An example of this is the redudant conditions in joins or cases where you abuse the HAVING clause, like in the above examples, in which you query the database by performing a function and then calling another function, or you use logic that contains loops, conditions, User Defined Functions (UDFs), cursors, … to get the final result. In this approach, you’ll often find yourself asking a subset of the data, then requesting another subset from the data and so on.
It’s no surprise that this approach is often called “step-by-step” or “row-by-row” querying.
The other approach is the set-based approach, where you just specify what to do. Your role consists of specifying the conditions or requirements for the result set that you want to obtain from the query. How your data is retrieved, you leave to the internal mechanisms that determine the implementation of the query: you let the database engine determine the best algorithms or processing logic to execute your query.
Since SQL is set-based, it’s hardly a surprise that this approach will be quite more effective than the procedural one and it also explains why, in some cases, SQL can work faster than code.
Tip the set-based approach of querying is also the one that most top employers in the data science industry will ask of you to master! You’ll often need to switch between these two types of approaches.
Note that if you ever find yourself with a procedural query, you should consider rewriting or refactoring it.
From Query to Execution Plans
Knowing that anti-patterns aren’t static and evolve as you grow as an SQL developer and the fact that there’s a lot to consider when you’re thinking about alternatives also means that avoiding query anti-patterns and rewriting queries can be quite a difficult task. Any help can come in handy and that’s why a more structured approach to optimize your query with some tools might be the way to go.
Note also that some of the anti-patterns mentioned in the last section had roots in performance concerns, such as the AND, OR and NOT operators and their lack of index usage. Thinking about performance doesn’t only require a more structured approach but also a more in-depth one.
Be however it may, this structured and in-depth approach will mostly be based on the query plan, which, as you remember, is the result of the query that’s first parsed into a “parse tree” and defines exactly what algorithm is used for each operation and how the execution of operations is coordinated.
Query Optimization
As you have read in the introduction, it could be that you need to examine and tune the plans that are produced by the optimizer manually. In such cases, you will need to analyze your query again by looking at the query plan.
To get a hold of this plan, you will need to use the tools that your database management system provides to you. Some tools that you might have at your disposal are the following:
- Some packages feature tools which will generate a graphical representation of a query plan. Take a look at this example:
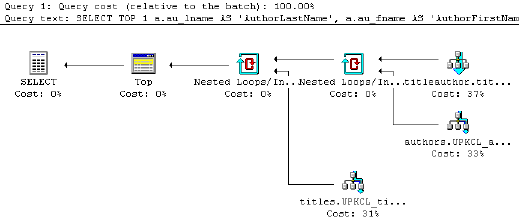
- Other tools will be able to provide you with a textual description of the query plan. One example is the
EXPLAIN PLANstatement in Oracle, but the name of the instruction varies according to the RDBMS that you’re working with. Elsewhere, you might findEXPLAIN(MySQL, PostgreSQL) orEXPLAIN QUERY PLAN(SQLite).
Note that if you’re working with PostgreSQL, you make the difference between EXPLAIN, where you just get a description that states the idea of how the plannner intends to execute the query without running it, while EXPLAIN ANALYZE actually executes the query and returns to you an analysis of the expected versus actual query plans. Generally speaking, an actual execution plan is one where you actually run the query, whereas an estimated execution plan works out what it would do without executing the query. Although logically equivalent, an actual execution plan is much more useful as it contains additional details and statistics about what actually happened when executing the query.
In the remainder of this section, you’ll learn more about EXPLAIN and ANALYZE and how you can use these two to learn more about your query plan and the possible performance of your query. To do this, you’ll get started with some examples in which you’ll work with two tables: one_million and half_million.
You can retrieve the current information of the table one_million with the help of EXPLAIN; Make sure to put it right on top of your query and when it’s run, it’ll give you back the query plan:
EXPLAIN
SELECT *
FROM one_million;
QUERY PLAN
____________________________________________________
Seq Scan on one_million
(cost=0.00..18584.82 rows=1025082 width=36)
(1 row)In this case, you see that the cost of the query is 0.00..18584.82 and that the number of rows is 1025082. The width of number of columns is then 36.
Also, you can then renew your statistical information with the help of ANALYZE.
ANALYZE one_million;
EXPLAIN
SELECT *
FROM one_million;
QUERY PLAN
____________________________________________________
Seq Scan on one_million
(cost=0.00..18334.00 rows=1000000 width=37)
(1 row)Besides EXPLAIN and ANALYZE, you can also retrieve the actual execution time with the help of EXPLAIN ANALYZE:
EXPLAIN ANALYZE
SELECT *
FROM one_million;
QUERY PLAN
___________________________________________________________
Seq Scan on one_million
(cost=0.00..18334.00 rows=1000000 width=37)
(actual time=0.015..1207.019 rows=1000000 loops=1)
Total runtime: 2320.146 ms
(2 rows)The downside of using EXPLAIN ANALYZE here is obviously that the query is actually executed, so be careful with that!
Up until now, all the algorithms you have seen is the Seq Scan (Sequential Scan) or a Full Table Scan: this is a scan made on a database where each row of the table under scan is read in a sequential (serial) order and the columns that are found are checked for whether they fulfill a condition or not. In terms of performance, the Sequential Scan is definitely not the best execution plan out there because you’re still doing a full table scan. However, it’s not too bad when the table doesn’t fit into memory: sequential reads go quite fast even with slow disks.
You’ll see more on this later on when you’re talking about the index scan.
However, there are some other algorithms out there. Take, for an example, this query plan for a join:
EXPLAIN ANALYZE
SELECT *
FROM one_million JOIN half_million
ON (one_million.counter=half_million.counter);
QUERY PLAN
_________________________________________________________________
Hash Join (cost=15417.00..68831.00 rows=500000 width=42)
(actual time=1241.471..5912.553 rows=500000 loops=1)
Hash Cond: (one_million.counter = half_million.counter)
-> Seq Scan on one_million
(cost=0.00..18334.00 rows=1000000 width=37)
(actual time=0.007..1254.027 rows=1000000 loops=1)
-> Hash (cost=7213.00..7213.00 rows=500000 width=5)
(actual time=1241.251..1241.251 rows=500000 loops=1)
Buckets: 4096 Batches: 16 Memory Usage: 770kB
-> Seq Scan on half_million
(cost=0.00..7213.00 rows=500000 width=5)
(actual time=0.008..601.128 rows=500000 loops=1)
Total runtime: 6468.337 msYou see that the query optimizer chose for a Hash Join here! Remember this operation, as you’ll need this to estimate the time complexity of your query. For now, note that there is no index on half_million.counter, which you could add in the next example:
CREATE INDEX ON half_million(counter);
EXPLAIN ANALYZE
SELECT *
FROM one_million JOIN half_million
ON (one_million.counter=half_million.counter);
QUERY PLAN
________________________________________________________________
Merge Join (cost=4.12..37650.65 rows=500000 width=42)
(actual time=0.033..3272.940 rows=500000 loops=1)
Merge Cond: (one_million.counter = half_million.counter)
-> Index Scan using one_million_counter_idx on one_million
(cost=0.00..32129.34 rows=1000000 width=37)
(actual time=0.011..694.466 rows=500001 loops=1)
-> Index Scan using half_million_counter_idx on half_million
(cost=0.00..14120.29 rows=500000 width=5)
(actual time=0.010..683.674 rows=500000 loops=1)
Total runtime: 3833.310 ms
(5 rows)You see that, by creating the index, the query optimizer has now decided to go for a Merge join where Index Scans are happening.
Note the difference between the index scan and the full table scan or sequential scan: the former, which is also called “table scan”, scans the data or index pages to find the appropriate records, while the latter scans each row of the table.
You see that the total runtime has been reduced and the performance should be better, but there are two index scans, which makes that the memory will become more important here, especially if the table doesn’t fit into memory. In such cases, you first have to do a full index scan, which are fast sequential reads and pose no problem, but then you have a lot of random reads to fetch rows by index value. It’s those random reads that are generally orders of magnitude slower than sequential reads. In these cases, the full table scan is indeed faster than the full index scan.
Tip: if you want to get to know more about EXPLAIN or see the examples in more detail, consider reading the book “Understanding Explain”, written by Guillaume Lelarge.