 42 Steps to Mastering Data Science
42 Steps to Mastering Data Science
 42 Steps to Mastering Data Science
42 Steps to Mastering Data ScienceThis post is a collection of 6 separate posts of 7 steps a piece, each for mastering and better understanding a particular data science topic, with topics ranging from data preparation, to machine learning, to SQL databases, to NoSQL and beyond.

If you are interested in meta-tutorials on a variety of data science topics, you have come to the right place.
Of the six 7-step tutorials included herein, the first 3 tutorials cover, in order, the machine learning process from data preparation through to several different types of machine learning tasks, including both theoretical understanding and practical implementation using Python libraries.
The fourth tutorial covers deep learning, mainly from an "understanding" perspective, while the final 2 cover database topics: SQL for data science, and understanding NoSQL databases.
And so with a nod to Douglas Adams, and the answer to life, universe, and everything, let's have a look at 42 steps to mastering data science.
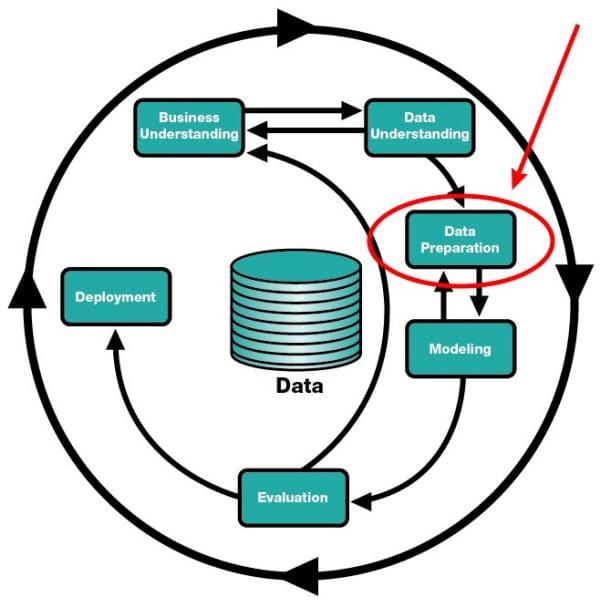
7 Steps to Mastering Data Preparation with Python
Data preparation, cleaning, pre-processing, cleansing, wrangling. Whatever term you choose, they refer to a roughly related set of pre-modeling data activities in the machine learning, data mining, and data science communities.
Keep in mind, however, that this article covers one particular set of data preparation techniques, and additional, or completely different, techniques may be used in a given circumstance, based on requirements. You should find that the prescription held herein is one which is both orthodox and general in approach.
7 Steps to Mastering Machine Learning With Python
This post aims to take a newcomer from minimal knowledge of machine learning in Python all the way to knowledgeable practitioner in 7 steps, all while using freely available materials and resources along the way. The prime objective of this outline is to help you wade through the numerous free options that are available; there are many, to be sure, but which are the best? Which complement one another? What is the best order in which to use selected resources?
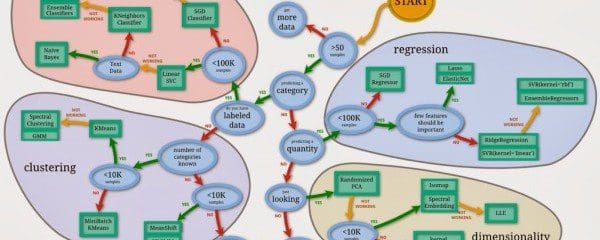
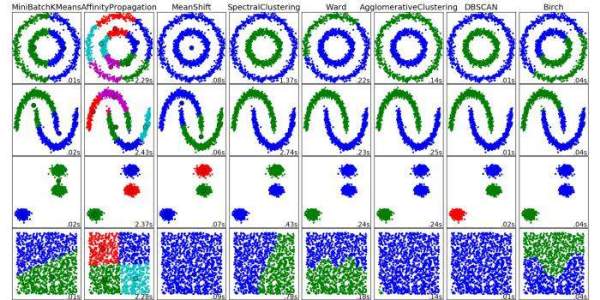
7 More Steps to Mastering Machine Learning With Python
After a quick review -- and a few options for a fresh perspective -- this post will focus more categorically on several sets of related machine learning tasks. Since we can safely skip the foundational modules this time around -- Python basics, machine learning basics, etc. -- we will jump right into the various machine learning algorithms. We can also categorize our tutorials better along functional lines this time.
7 Steps to Understanding Deep Learning
This collection of reading materials and tutorials aims to provide a path for a deep neural networks newcomer to gain some understanding of this vast and complex topic. Though I do not assume any real understanding of neural networks or deep learning, I will assume your familiarity with general machine learning theory and practice to some degree. To overcome any deficiency you may have in the general areas of machine learning theory or practice you can consult the recent KDnuggets post 7 Steps to Mastering Machine Learning With Python. Since we will also see examples implemented in Python, some familiarity with the language will be useful. Introductory and review resources are also available in the previously mentioned post.
7 Steps to Mastering SQL for Data Science
Clearly, SQL is important in data science. As such, this post aims to take a reader from SQL newbie to competent practitioner in a short time, using freely-available online resources. Lots of such resources exist on the internet, but mapping out a path from start to finish, using items which complement each other, is not always as straightforward as it may seem. Hopefully this post can be of assistance in this manner.

7 Steps to Understanding NoSQL Databases
The term NoSQL has come to be synonymous with schema-less, non-relational data storage schemes. NoSQL is an umbrella term, one which encompasses a number of different technologies. These different technologies aren't even necessarily related in any way beyond the single defining characteristic of NoSQL: they are not relational in nature; for right or wrong, Structured Query Language (SQL) has become conflated with relational database management systems over the years.

Related: