 7 More Steps to Mastering Machine Learning With Python
7 More Steps to Mastering Machine Learning With Python
 7 More Steps to Mastering Machine Learning With Python
7 More Steps to Mastering Machine Learning With Python
This post is a follow-up to last year's introductory Python machine learning post, which includes a series of tutorials for extending your knowledge beyond the original.
So, you have been thinking about picking up machine learning, but given the confusing state of the web you don't know where to begin? Or maybe you have finished the first 7 steps and are looking for some follow-up material, beyond the introductory?
Machine learning algorithms.
This post is the second installment of the 7 Steps to Mastering Machine Learning in Python series (since there are 2 parts, I guess it now qualifies as a series). If you have started with the original post, you should already be satisfactorily up to speed, skill-wise. If not, you may want to review that post first, which may take some time, depending on your current level of understanding; however, I assure you that doing so will be worth your effort.
After a quick review -- and a few options for a fresh perspective -- this post will focus more categorically on several sets of related machine learning tasks. Since we can safely skip the foundational modules this time around -- Python basics, machine learning basics, etc. -- we will jump right into the various machine learning algorithms. We can also categorize our tutorials better along functional lines this time.
I will, once again, state that the material contained herein is all freely available on the web, and all rights and recognition for the works belong to their original authors. If something has not been properly attributed, please feel free to let me know.
Step 1: Machine Learning Basics Review & A Fresh Perspective
Just to review, these are the steps covered in the original post:
- Basic Python Skills
- Foundational Machine Learning Skills
- Scientific Python Packages Overview
- Getting Started with Machine Learning in Python: Introduction & model evaluation
- Machine Learning Topics with Python: k-means clustering, decision trees, linear regression & logistic regression
- Advanced Machine Learning Topics with Python: Support vector machines, random forests, dimension reduction with PCA
- Deep Learning in Python
As stated above, if you are looking to start from square one, I would suggest going back to the first article and proceeding accordingly. I will also note that the appropriate getting started material, including any and all installation instructions, are including in the previous article.
If, however, you are really green, I would start with the following, covering the absolute basics:
- Machine Learning Key Terms, Explained, by Matthew Mayo
- Statistical Classification on Wikipedia
- Machine Learning: A Complete and Detailed Overview, by Alex Castrounis
If you are looking for some alternative or complementary approaches to learning the basics of machine learning, I have recently been enjoying Shai Ben-David's video lectures and freely available textbook written with Shai Shalev-Shwartz. Find them both here:
- Shai Ben-David's introductory machine learning video lectures, University of Waterloo
- Understanding Machine Learning: From Theory to Algorithms, by Shai Ben-David & Shai Shalev-Shwartz
Remember, the introductory material does not all need to be digested before moving forward with the rest of the steps (in either this post or the original). Video lectures, texts, and other resources can be consulted when implementing models using the reflected machine learning algorithms, or when applicable concepts are being used practically in subsequent steps. Use your judgment.
Step 2: More Classification
We begin with the new material by first strengthening our classification know-how and introducing a few additional algorithms. While part 1 of our post covered decision trees, support vector machines, and logistic regression -- as well as the ensemble classifier Random Forests -- we will add k-nearest neighbors, the Naive Bayes classier, and a multilayer perceptron into the mix.
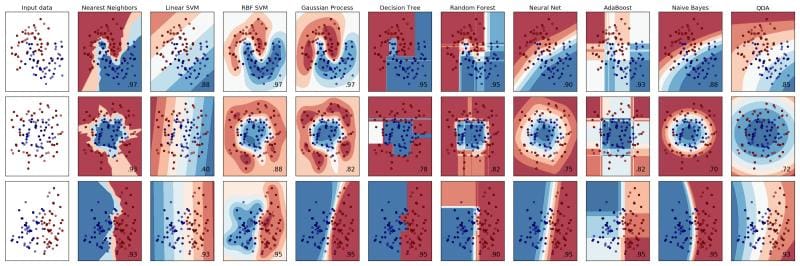
Scikit-learn classifiers.
k-nearest neighbors (kNN) is a simple classifier and an example of a lazy learner, in which all computation occurs at classification time (as opposed to occurring during a training step ahead of time). kNN is non-parametric, and functions by comparing a data instance with the k closest instances when making decisions about how it should be classified.
Naive Bayes is a classifier based on Bayes' Theorem. It assumes that there is independence among features, and that the presence of any particular feature in one class is not related to any other feature's presence in the same class.
- Document Classification with scikit-learn, by Zac Stewart
The multilayer perceptron (MLP) is a simple feedforward neural network, consisting of multiple layers of nodes, where each layer is fully connected with the layer which comes after it. The MLP was introduced in Scikit-learn version 0.18.
First read an overview of the MLP classifier from the Scikit-learn documentation, and then practice implementation with a tutorial.
- Neural network models (supervised), Scikit-learn documentation
- A Beginner’s Guide to Neural Networks with Python and SciKit Learn 0.18!, by Jose Portilla
Step 3: More Clustering
We now move on to clustering, a form of unsupervised learning. In the first post we covered the k-means algorithm; we will introduce DBSCAN and Expectation-maximization (EM) herein.
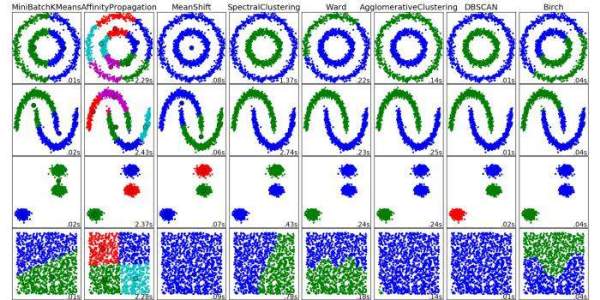
Scikit-learn clustering algorithms.
First off, read these introductory posts; the first is a quick comparison of k-means and EM clustering techniques, a nice segue into new forms of clustering, and the second is an overview of clustering techniques available in Scikit-learn:
- Comparing Clustering Techniques: A Concise Technical Overview, by Matthew Mayo
- Comparing different clustering algorithms on toy datasets, Scikit-learn documentation
Expectation-maximization (EM) is a probabilistic clustering algorithm, and, as such, involves determining the probabilities that instances belong to particular clusters. EM ”approaches maximum likelihood or maximum a posteriori estimates of parameters in statistical models” (Han, Kamber & Pei). The EM process begins with a set of parameters, iterating until clustering is maximized, with respect to k clusters.
First read a tutorial on the EM algorithm. Next, have a look at the relevant Scikit-learn documentation. Finally, follow a tutorial and implement EM clustering yourself with Python.
- A Tutorial on the Expectation Maximization (EM) Algorithm, by Elena Sharova
- Gaussian mixture models, Scikit-learn documentation
- Quick introduction to gaussian mixture models with Python, by Tiago Ramalho
If "Gaussian mixture models" is confusing at first glance, this relevant section from the Scikit-learn documentation should alleviate any unnecessary worries:
The
GaussianMixtureobject implements the expectation-maximization (EM) algorithm for fitting mixture-of-Gaussian models.
Density-based spatial clustering of applications with noise (DBSCAN) operates by grouping densely-packed data points together, and designating low-density data points as outliers.
First read and follow an example implementation of DBSCAN from Scikit-learn's documentation, and then follow a concise tutorial:
- Demo of DBSCAN clustering algorithm, Scikit-learn documentation
- Density-based clustering algorithm (DBSCAN) and Implementation