 Using Machine Learning to Predict and Explain Employee Attrition
Using Machine Learning to Predict and Explain Employee Attrition
 Using Machine Learning to Predict and Explain Employee Attrition
Using Machine Learning to Predict and Explain Employee AttritionEmployee attrition (churn) is a major cost to an organization. We recently used two new techniques to predict and explain employee turnover: automated ML with H2O and variable importance analysis with LIME.
By Matt Dancho, BusinessScience.io
Employee turnover (attrition) is a major cost to an organization, and predicting turnover is at the forefront of needs of Human Resources (HR) in many organizations. Until now the mainstream approach has been to use logistic regression or survival curves to model employee attrition. However, with advancements in machine learning (ML), we can now get both better predictive performance and better explanations of what critical features are linked to employee attrition. In this post, we’ll explain how we used the automated machine learning function from H2O to develop a predictive model that is in the same ballpark as commercial products in terms of ML accuracy we’ll also explain how we applied the new LIME package that enables breakdown of complex, black-box machine learning models into variable importance plots.
The Problem: Employee Attrition
Organizations face huge costs resulting from employee turnover. Some costs are tangible such as training expenses and the time it takes from when an employee starts to when they become a productive member. However, the most important costs are intangible. Consider what’s lost when a productive employee quits: new product ideas, great project management, or customer relationships. With advances in machine learning and data science, it’s possible to not only predict employee attrition but to understand the key variables that influence turnover.
We used the HR employee attrition data set that comes from the [IBM Watson website](https://www.ibm.com/communities/analytics/watson-analytics-blog/hr-employee-attrition/) to test out several advanced ML techniques. The dataset includes 1470 employees (rows) and 35 features (columns) a portion of which have left the organization (Attrition = “Yes”). Note that according to IBM, “this is a fictional data set created by IBM data scientists”.
The Solution: H2O and LIME
The solution we implemented used both H2O for automated machine learning and LIME for understanding and breaking down complex, black-box models. We’ll go over the highlights from the analysis, but the interested reader can see the [full solution including code here](http://www.business-science.io/business/2017/09/18/hr_employee_attrition.html).
Machine Learning with `h2o.automl()` from the `h2o` package: This function takes automated machine learning to the next level by testing a number of advanced algorithms such as random forests, ensemble methods, and deep learning along with more traditional algorithms such as logistic regression. The main takeaway is that we can now easily achieve predictive performance that is in the same ball park (and in some cases even better than) commercial algorithms and ML/AI software.
The leader model (most accurate model produced on the validation set) had an astounding 88% accuracy on a test set that was not seen during the modeling process. Further, the binary classification analysis had recall (the number of times the algorithm predicts Attrition = “Yes” when attrition is actually yes) of 62% meaning that HR professionals could accurately target 62 of 100 employees considered at risk. In an HR context recall is very important because we don’t want to miss at-risk employees and 62% performance is pretty good.
Feature (Variable) Importance with the `lime` package: The problem with advanced machine learning algorithms such as deep learning is that it’s near impossible to understand the algorithm because of its complexity. This has all changed with the `lime` package. The major advancement with `lime` is that by recursively analyzing the models locally it can extract feature importance that repeats globally. What this means to us is that `lime` has opened the door to understanding the ML models regardless of complexity. Now the best (and typically very complex) models can also be investigated and potentially understood as to what variables or features make the model tick.
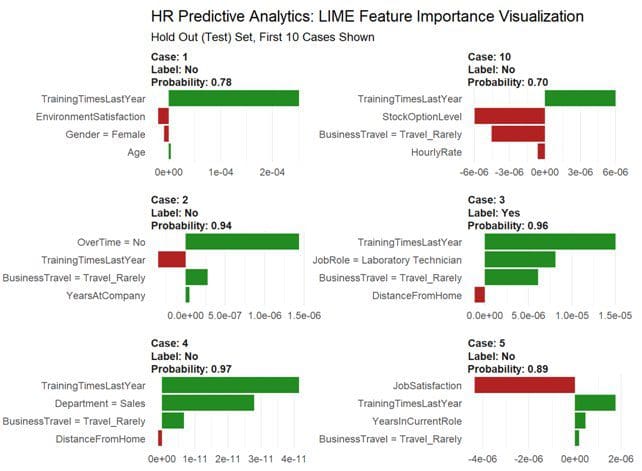
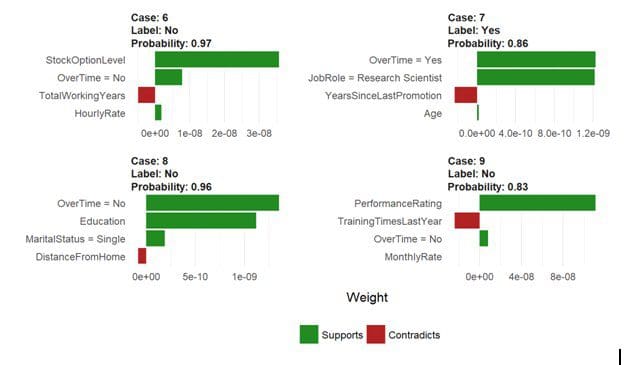
The payoff for the work we put into using LIME is this feature importance plot. The top four features for each of the first ten cases (observations) are shown. The green bars mean that the feature supports the model conclusion and the red bars contradict. LIME detected Over Time, Job Role, and Training Time as features that are relevant to the model predictions.
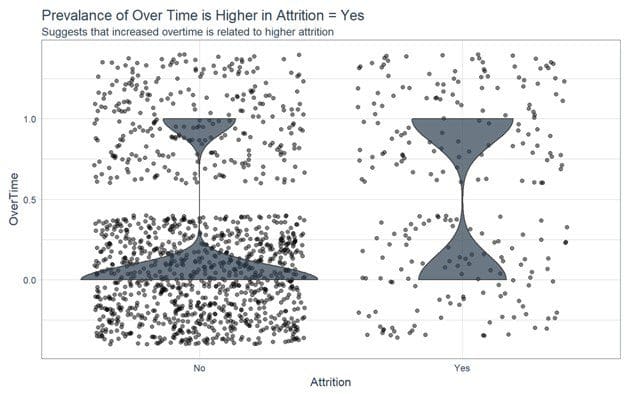
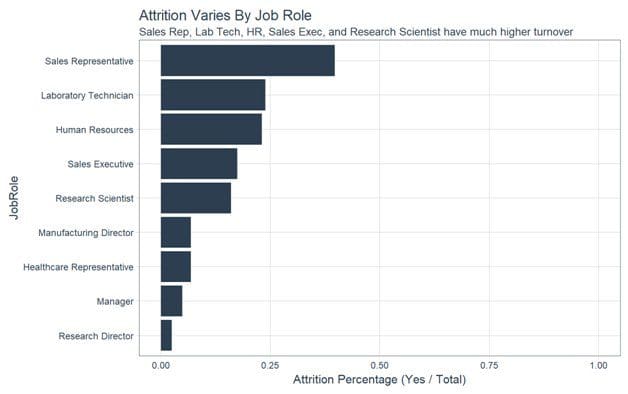
We then analyzed the critical features get an idea of whether the features were linked to attrition. For features like Over Time and Job Role, the variance appears to be linked. We can see that the group with Attrition = “No” has a lower proportion of employees working overtime. In addition roles such as Sales Representative, Laboratory Technician and Human Resources had a higher attrition percentage as compare to other Job Roles.
Conclusion
New machine learning techniques can be applied to business applications and specifically predictive analytics. In this case we use H2O and LIME to develop and explain sophisticated models that very accurately detect employees that are at risk of turnover. The `h2o.autoML` function from H2O worked well for classifying attrition with accuracy around 88% on unseen / un-modeled data. LIME helped to breakdown the complex ensemble model returned from H2O into critical features that are related to attrition.
Bio: Matt Dancho is the founder of [Business Science](www.business-science.io), a consulting firm that assists organizations in applying data science to business applications. He is the creator of R packages tidyquant and timetk and has been working with data science for business and financial analysis for six years. Matt holds master’s degrees in business and engineering, and has extensive experience in business intelligence, data mining, time series analysis, statistics and machine learning.
Related: