 What is a Bayesian Neural Network?
What is a Bayesian Neural Network?
 What is a Bayesian Neural Network?
What is a Bayesian Neural Network?BNNs are important in specific settings, especially when we care about uncertainty very much.
By Jonathan Gordon, University of Cambridge
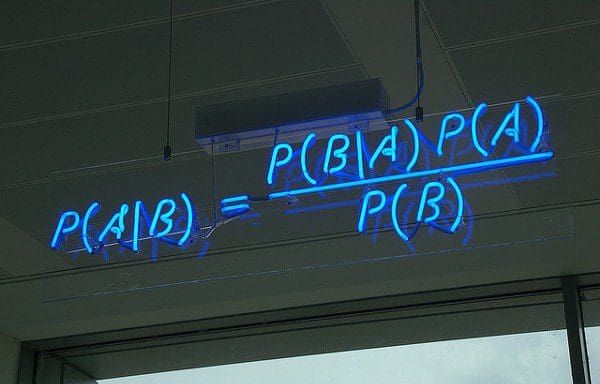
A Bayesian neural network (BNN) refers to extending standard networks with posterior inference. Standard NN training via optimization is (from a probabilistic perspective) equivalent to maximum likelihood estimation (MLE) for the weights.
For many reasons this is unsatisfactory. One reason is that it lacks proper theoretical justification from a probabilistic perspective: why maximum likelihood? Why just point estimates? Using MLE ignores any uncertainty that we may have in the proper weight values. From a practical standpoint, this type of training is often susceptible to overfitting, as NNs often do.
One partial fix for this is to introduce regularization. From a Bayesian perspective, this is equivalent to inducing priors on the weights (say Gaussian distributions if we are using L2 regularization). Optimization in this case is akin to searching for MAP estimators rather than MLE. Again from a probabilistic perspective, this is not the right thing to do, though it certainly works well in practice.
The correct (i.e., theoretically justifiable) thing to do is posterior inference, though this is very challenging both from a modelling and computational point of view. BNNs are neural networks that take this approach. In the past this was all but impossible, and we had to resort to poor approximations such as Laplace’s method (low complexity) or MCMC (long convergence, difficult to diagnose). However, lately there have been some super-interesting results on using variational inference to do this [1], and this has sparked a great deal of interest in the area.
BNNs are important in specific settings, especially when we care about uncertainty very much. Some examples of these cases are decision making systems, (relatively) smaller data settings, Bayesian Optimization, model-based reinforcement learning and others.
[1] - [1505.05424] Weight Uncertainty in Neural Networks
Bio: Jonathan Gordon (website) is a PhD candidate with the machine learning group at the University of Cambridge. His research interests lie at the intersection of deep learning and probabilistic modelling, where he primarily focuses on developing probabilistic models (typically parameterised by deep neural networks) and accompanying scalable inference algorithms. He is especially interested in deep generative models, Bayesian deep learning methods, and variational inference to improve data efficiency in complex learning regimes.
Original. Reposted with permission.
Related:
- The Truth About Bayesian Priors and Overfitting
- How Bayesian Networks Are Superior in Understanding Effects of Variables
- Bayesian Machine Learning, Explained