When reinforcement learning should not be used?
While reinforcement learning has achieved many successes, there are situations when it use is problematic. We describe the issues and how to work around them.
By Jason Xie.
I'll discuss some of the issues reinforcement learning faces.
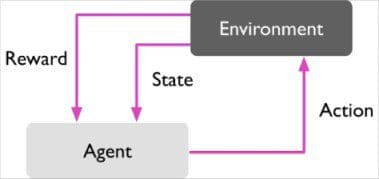 Reinforcement learning describes the set of learning problems where an agent must take actions in an environment in order to maximize some defined reward function.
Reinforcement learning describes the set of learning problems where an agent must take actions in an environment in order to maximize some defined reward function.
Unlike supervised deep learning, large amounts of labeled data with the correct input output pairs are not explicitly presented. Most of the learning happens online, i.e. as the agent actively interacts with its environment over several iterations, it eventually begins to learn the policy describing which actions to take to maximize the reward.
The way reinforcement learning models the problem requires several conditions:
You can quantify all the variables the environment describes and have access to these variables at each time step, or state
You can define a concrete reward function and compute the reward for taking an action
You can afford to make mistakes
You have time
It is because of these limitations that recent successes in reinforcement learning have happened almost entirely in simulated, controlled environments (think DeepMind's research on Atari, AlphaGo). There is still tremendous research needed in overcoming these limitations and adapting deep RL to work effectively in real-time agents.
Bio: Jason Xie is a student, interested in AI & robotics. Always curious and always learning.
Original Quora answer. Reposted with permission.
Related:
I'll discuss some of the issues reinforcement learning faces.
Reinforcement learning describes the set of learning problems where an agent must take actions in an environment in order to maximize some defined reward function.
Unlike supervised deep learning, large amounts of labeled data with the correct input output pairs are not explicitly presented. Most of the learning happens online, i.e. as the agent actively interacts with its environment over several iterations, it eventually begins to learn the policy describing which actions to take to maximize the reward.
The way reinforcement learning models the problem requires several conditions:
You can quantify all the variables the environment describes and have access to these variables at each time step, or state
- Neither may be the case in the real world; more often than not you only have access to partial information. The information that you do have access to itself can be inaccurate and in need of further extrapolation, since it is measured from an egocentric point of view (at least in the case of a robot interacting with an unknown environment).
You can define a concrete reward function and compute the reward for taking an action
- The reward function may not be obvious. For example, if I am designing an agent to perform path planning for an autonomous vehicle, how should we express the reward mathematically? How do we know that the reward function that we defined is "good"?
- One approach to get around this is inverse reinforcement learning (PDF)
You can afford to make mistakes
- The freedom to explore without consequence is not always present. If I want to build an autonomous vehicle using RL, how many thousands of times will the car crash itself before it can make even the simplest maneuvers?
- Still, training in simulated environments has yielded performance gains in the real world, and should not be dismissed. (see Playing for Data: Ground Truth from Computer Games)
You have time
- Since learning is predominantly online, you have to run trials many many times in order to produce an effective model. This is acceptable when the task at hand is simple, actions are discrete, and information is readily available. But in many cases, the problem formulation is significantly more complex and you must balance the precision of your simulator with both training time and real-time performance constraints.
It is because of these limitations that recent successes in reinforcement learning have happened almost entirely in simulated, controlled environments (think DeepMind's research on Atari, AlphaGo). There is still tremendous research needed in overcoming these limitations and adapting deep RL to work effectively in real-time agents.
Bio: Jason Xie is a student, interested in AI & robotics. Always curious and always learning.
Original Quora answer. Reposted with permission.
Related:
- Exclusive: Interview with Rich Sutton, the Father of Reinforcement Learning
- 3 different types of machine learning
- AlphaGo Zero: The Most Significant Research Advance in AI