Beyond Word2Vec Usage For Only Words
A good example on how to use word2vec in order to get recommendations fast and efficiently.
By Stanko Kuveljic, SmartCat.

Making a machine learning model usually takes a lot of crying, pain, feature engineering, suffering, training, debugging, validation, desperation, testing and a little bit of agony due to the infinite pain. After all that, we deploy the model and use it to make predictions for future data. We can run our little devil on a batch of data once in an hour, day, week, month or on the fly depending on the situation and use case.
Let’s take a look at an example related to an online sport betting recommender engine. The goal of that engine is to predict whether the user will play a particular selection on a game or not (e.g. final score - home win, goals - 3 or more goals, etc). These predictions are based on user history, and those predictions are used to construct a ticket that will be recommended to the user.
To achieve fast recommendation in real time, we can calculate everything before the user even appears. This use case allows us to fantasize with feature extraction, we can literally play with features in order to make a more accurate model without hurting the performance of the application. Some toy pipeline and prediction is presented in the image below. So basically, our application will fast serve predictions, and our satan rituals can run safely in the background.

Awwww, there are even unicorns in the picture. But, what about us not having a predefined set of data and having to do everything on the fly? Our unicorns won’t be happy :( Let’s go back to our good old example of online sports betting. We can prepare predictions for non-started games, but what about users who bet on games in the middle of a match, so-called live betting? Our complex feature engineering + model scoring pipeline can struggle to achieve this for thousands and thousands of users in real time. A single sport game can be changed every few seconds, so real time predictions are really something that we hope for. To make things even worse, we could have limited information about a game to make some needed features. One can try to optimize a model that works really well on non started games, and try to make a new model with less features. But, we can always try something new and look at the problem from a different angle. We have worked on a similar problem and we tried to approach word2vector, but in our case it is bet2vector. For a general explanation of word2vector, visit one of our latest blogs.
Everything2Vector
So everything2vector is where the fun begins. It is possible to make a vector representation for each user based only on its user id and ids of templates in the past. Let’s look at the following data sample:
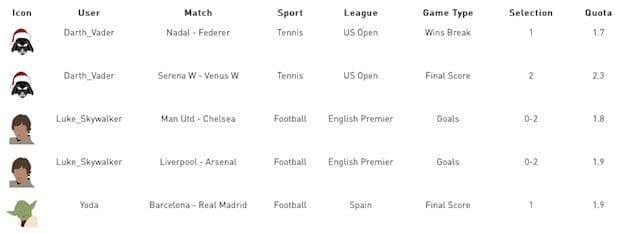
From the data we can see that Darth Vader likes to bet on tennis matches, but his son Luke likes to bet on English Premier League football. So how to make magic and learn from IDs only? First of all, we need to squash our information about games even more in order to get templates. These templates can group up data based on some similar features. In this case, templates are made in such a way to group similar games - football games from the same league, same game type and similar quota are grouped in the same template. For example:
- Template 1 - Tennis : US Open : Wins Break : 1 : quota_range (1.5 - 2.1)
- Template 2 - Tennis : US Open : Final Score : 2 : quota_range (1.8 - 2.6)
- Template 3 - Football : English Premier : Goals : 0-2 : quota_range (1.5 - 2.0)
- Template 4 - Football : Spain 1 : Final Score : 1 : quota_range (1.8 - 2.4)
- ………………..
- Template 1000 - Basketball : NBA : Total Score : >200 : quota_range (1.5 - 2.0)
These rules for determining templates can be calculated from data statistics, or defined with some domain knowledge. But, most importantly, these rules run very fast when it comes to determining template ID. This is everything we need from a feature engineering task. When we convert the previous data into a template we get:

Please note that skip-gram uses sentences like “Luke, I am your father” to determine what words are similar to each other. To make something like this, we need to group all history in sessions for every user. In this way we can obtain sentences representing user history, and user ID is now close to templates that he played in the past, like this:

Results
Let’s see how vector representation is learned during training. When an algorithm sees that a user has played some game template, it pushes the vectors representation of the user and played template close to each other in vector space. At the same time (using the sampling negatives technique) it pushes the player vector and non played game template vectors away from each other in vector space. In the image below, we can see how our “vectors” lay in space. There is a happy unicorn in the image again because it likes this solution.

We see that Darth Vader is close to templates that represent tennis matches because he likes to play tennis. Luke is away from his father, because he doesn’t like tennis, but he is into football and he would be closer to vectors representing football games. There is also Yoda who plays football but in a different league. But he is closer to Luke than to Darth because football templates are more similar than football and tennis templates.
The output of algorithm is a vector both for user IDs and template IDs that can be stored somewhere. Now, in prediction time where data changes every few seconds, we can always calculate predictions in real time. We just need to lookup currently available template vectors and do cosine similarity with the user vector in order to get similarity scores between the user and template. Aside from being fun to try, this technique realized good results on data set and also achieved the ultimately fast predictions for a huge number of users and templates that changes frequently. The most important part is that this technique can be applied everywhere and it would work nicely. For example, if we have information about history transactions [user ID - buy - item ID], we can only use the user IDs and item IDs to train vectors out of it. Based on trained vectors, we can recommend the most similar items to each user. By the most similar, we mean items that often occur together.
Merry Christmas and may the Force Vectors be with ya mon.
Original. Reposted with permission.
Related