 Comparing Machine Learning as a Service: Amazon, Microsoft Azure, Google Cloud AI
Comparing Machine Learning as a Service: Amazon, Microsoft Azure, Google Cloud AI
 Comparing Machine Learning as a Service: Amazon, Microsoft Azure, Google Cloud AI
Comparing Machine Learning as a Service: Amazon, Microsoft Azure, Google Cloud AIA complete and unbiased comparison of the three most common Cloud Technologies for Machine Learning as a Service.
Speech and text processing APIs: Google Cloud Services
While this set of APIs mainly intersects with what Amazon and Microsoft Azure suggest, it has some interesting and unique things to look at.
Dialogflow. With various chatbots topping today’s trends, Google also has something to offer. Dialogflow is powered by NLP technologies and aims at defining intents in the text, and interpreting what a person wants. The API can be tweaked and customized for needed intents using Java, Node.js, and Python.
Cloud natural language API. This one is almost identical in its core features to Comprehend by Amazon and Language by Microsoft.
- Defining entities in text
- Recognizing sentiment
- Analyzing syntax structures
- Categorizing topics (e.g. food, news, electronics, etc.)
Cloud speech API. This service recognizes natural speech, and perhaps its main benefit compared to similar APIs is the abundance of languages supported by Google. Currently, its vocab works with over 110 global languages and variants of them. It also has some additional features:
- Word hints allow for customizing recognition to specific contexts and words that can be spoken (e.g. for better understanding of local or industry jargon)
- Filtering inappropriate content
- Handling noisy audio
Cloud translation API. Basically, you can use this API to employ Google Translate in your products. This one includes over a hundred languages and automatic language detection.
Besides text and speech, Amazon, Microsoft, and Google provide rather versatile APIs for image and video analysis.
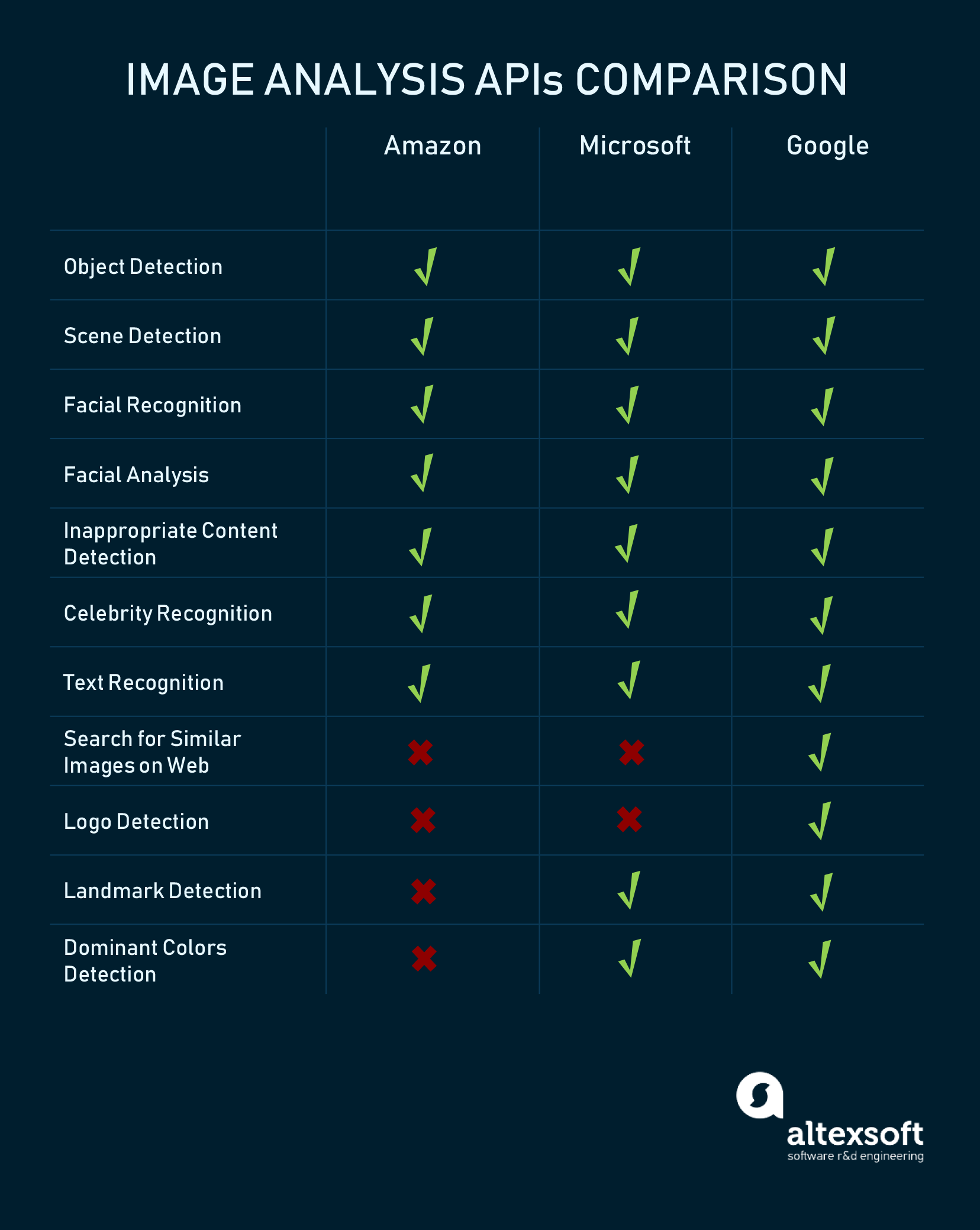
While image analysis closely intersects with video APIs, many tools for video analysis are still in development or beta versions. For instance, Google suggests rich support for various image processing tasks but definitely lacks video analysis features already available at Microsoft and Amazon.

Image and video processing APIs: Amazon Rekognition
No, we didn’t misspell the word. The Rekognition API is used for image and, recently, video recognition tasks. They include:
- Objects detection and classification (find and detect different objects in images and define what they are)
- In videos, it can detect activities like “dancing” or complex actions like “extinguishing fire”
- Face recognition (for detecting faces and finding matching ones) and facial analysis (this one is pretty interesting as it detects smiles, analyzes eyes, and even defines emotional sentiment in videos)
- Detecting inappropriate videos
- Recognizing celebrities in images and videos (for whatever goals that might be)
Image and video processing APIs: Microsoft Azure Cognitive Services
The Vision package from Microsoft combines six APIs that focus on different types of image, video, and text analysis.
- Computer vision that recognizes objects, actions (e.g. walking), and defines dominant colors in images
- Content moderator detects inappropriate content in images, texts, and videos
- Face API detects faces, groups them, defines age, emotions, genders, poses, smiles, and facial hair
- Emotion API is another face recognition tool that describes facial expressions
- Custom Vision Service supports building custom image recognition models using your own data
- Video indexer is a tool to find people in videos, define sentiment of speech, and mark keywords
Image and video processing APIs: Google Cloud Services
Cloud vision API. The tool is built for image recognition tasks and is quite powerful for finding specific image attributes:
- Labeling objects
- Detecting faces and analyzing expressions
- Finding landmarks and describing the scene (e.g. vacation, wedding, etc.)
- Finding texts in images and identifying languages
- Dominant colors
Cloud Video Intelligence. The video recognition API from Google is early in development so it lacks many features available with Amazon Rekognition and Microsoft Cognitive Services. Currently, the API provides the following toolset:
- Labeling objects and defining actions
- Identifying explicit content
- Transcribing speech
While on the feature-list level Google AI services may be lacking some abilities, the power of Google APIs is in the vast datasets that Google has access to.
Specific APIs and tools
Here, we’ll discuss specific API offerings and tools that come from Microsoft and Google. We didn’t include Amazon here, as their sets of APIs merely match the above-mentioned categories of text analysis and image+video analysis. However, some of the capacities of these specific APIs are also present in Amazon products.
Azure Service Bot framework. Microsoft has put a lot of effort into providing its users with flexible bot development toolset. Basically, the service contains a full-blown environment for building, testing, and deploying bots using different programming languages.
Interestingly, the Bot Service doesn’t necessarily require machine learning approaches. As Microsoft provides five templates for bots (basic, form, language understanding, proactive, and Q&A), only the language understanding type requires advanced AI techniques.
Currently, you can use .NET and Node.js technologies to build bots with Azure and deploy them on the following platforms and services:
- Bing
- Cortana
- Skype
- Web Chat
- Office 365 email
- GroupMe
- Facebook Messenger
- Slack
- Kik
- Telegram
- Twilio
Bing Search from Microsoft. Microsoft suggests seven APIs that connect with the core Bing search features, including autosuggest, news, image, and video search.
Knowledge from Microsoft. This APIs group combines text analysis with a broad spectrum of unique tasks:
- Recommendations API allows for building recommender systems for purchase personalization
- Knowledge Exploration Service allows you to type in natural queries to retrieve data from databases, visualize data, and autocomplete queries
- Entity Linking Intelligence API is designed to highlight names and phrases that denote proper entities (e.g. Age of Exploration) and ensure disambiguation
- Academic Knowledge API does word autocompletion, finds similarities in documents both in words and concepts, and searches for graph patterns in documents
- QnA Maker API can be used to match variations of questions with answers to build customer care chatbots and applications
- Custom Decision Service is a reinforcement learning tool to personalize and rank different types of content (e.g. links, ads, etc.) depending on user’s preferences
Google Cloud Job Discovery. The API is still in the early development, but soon it may redefine the job search capacities that we have today. Unlike conventional job search engines that rely on precise keyword matches, Google employs machine learning to find relevant connections between highly variative job descriptions and avoid ambiguity. For instance, it strives to reduce irrelevant or too broad returns, like returning all jobs with the keyword “assistant” for the query “sales assistant.” What are the main features of the API?
- Fixing spelling errors in job search queries
- Matching the desired seniority level
- Finding relevant jobs that may have variative expressions and industry jargon involved (e.g. returning “barista” for the “server” query instead of “network specialist”; or “engagement specialist” for the “biz dev” query)
- Dealing with acronyms (e.g. returning “human resources assistant” for the “HR” query)
- Matching variative location descriptions
IBM Watson and others
All three platforms described before provide quite an exhaustive documentation to jump-start machine learning experiments and deploy trained models in a corporate infrastructure. There are also a number of other ML-as-a-service solutions that come from startups, and are respected by data scientists, like PredicSis and BigML.
But what about IBM Watson Analytics?
IBM Watson Analytics isn’t yet a full-fledged machine learning platform for the purpose of business prediction. Currently, Watson’s strength is visualizing data and describing how different values in it interact. It also has visual recognition servicesimilar to what Google offers and a set of other cognitive services (APIs). The current problem with Watson is that the system performs narrow and relatively simple tasks that are easy to operate for non-professionals. When it comes to custom machine learning or prediction duties, it’s too early in its development to consider IBM Watson.
Data storage
Finding the right storage for collecting data and further processing it with machine learning is no longer a great challenge, assuming that your data scientists have enough knowledge to operate popular storage solutions.
In most cases, machine learning requires both SQL and NoSQL database schemes, which are supported by many established and trusted solutions like Hadoop Distributed File System (HDFS), Cassandra, Amazon S3, and Redshift. For organizations that have used powerful storage systems before embarking on machine learning, this won’t be a barrier. If you plan to work with some ML-as-a-service system, the most straightforward way is to choose the same provider both for storage and machine learning as this will reduce time spent on configuring a data source.
However, some of these platforms can be easily integrated with other storages. Azure ML, for instance, mainly integrates with other Microsoft products (Azure SQL, Azure Table, Azure Blob) but also supports Hadoop and a handful of other data source options. These include direct data upload from a desktop or on-premise server. The challenges may arise if your machine learning workflow is diversified and data comes from multiple sources.
Modeling and computing
We’ve discussed ML-as-a-service solutions that mainly provide computing capacities. But if the learning workflow is performed internally, the computing challenge will strike sooner or later. Machine learning in most cases requires much computing power. Data sampling (making a curated subset) is still a relevant practice, regardless of the fact that the era of big data has come. While model prototyping can be done on a laptop, training a complex model using a large dataset requires investment into more powerful hardware. The same applies to data preprocessing, which can take days on regular office machines. In a deadline-sensitive environment – where sometimes models should be altered and retrained weekly or daily – this simply isn’t an option. There are three viable approaches to handling processing while keeping high performance:
- Accelerate hardware. If you do relatively simple tasks and don’t apply your models for big data, use solid-state drives (SSDs) for such tasks as data preparation or using analytics software. Computationally intensive operations can be addressed with one or several graphical processing units (GPUs). A number of libraries are available to let GPUs process models written even with such high-level languages as Python.
- Consider distributed computing. Distributed computing implies having multiple machines with tasks split across them. However, this approach isn’t going to work for all machine learning techniques.
- Use cloud computing for scalability. If your models process customer-related data that has intensive peak-moments, cloud computing services will allow for rapid scalability. For the companies that are required to have their data on-premise only, it’s worth considering private cloud infrastructure.
The next move
It’s easy to get lost in the variety of solutions available. They differ in terms of algorithms, they differ in terms of required skillsets, and eventually they differ in tasks. This situation is quite common for this young market as even the three leading solutions that we’ve talked about aren’t fully competitive with each other. And more than that, the velocity of change is impressive. There’s a high likelihood that you’ll stick with one vendor and suddenly another one will roll out something unexpectedly that matches your business needs.
The right move is to articulate what you plan to achieve with machine learning as early as possible. It’s not easy. Creating a bridge between data science and business value is tricky if you lack either data science or domain expertise. We at AltexSoft encounter this problem often when discussing machine learning applications with our clients. It’s usually a matter of simplifying the general problem to a single attribute. Whether it’s the price forecast or another numeric value, the class of an object or segregation of objects into multiple groups, once you find this attribute, deciding the vendor and choosing what’s proposed will be simpler.
Bradford Cross, founding partner at DCVC, argues that ML-as-a-services isn’t a viable business model. According to him, it falls in the gap between data scientists who are going to use open source products and executives who are going to buy tools solving tasks at the higher levels. However, it seems that the industry is currently overcoming its teething problems and eventually we’ll see far more companies turning to ML-as-a-service to avoid expensive talent acquisitions and still possess versatile data tools.
Original. Reposted with permission.
Related