 Exploring DeepFakes
Exploring DeepFakes
 Exploring DeepFakes
Exploring DeepFakesIn this post, I explore the capabilities of this tech, describe how it works, and discuss potential applications.
By Gaurav Oberoi, Allen Institute for AI

The progress of a neural network that is learning how to generate Jimmy Fallon and John Oliver’s faces.
In December 2017, a user named “DeepFakes” posted realistic looking explicit videos of famous celebrities on Reddit. He generated these fake videos using deep learning, the latest in AI, to insert celebrities’ faces into adult movies.
In the following weeks, the internet exploded with articles about the dangers of face swapping technology: harassing innocents, propagating fake news, and hurting the credibility of video evidence forever.
It’s true that bad actors will use this technology for harm; but given that the genie is out of the bottle, shouldn’t we pause to consider what else DeepFakes could be used for?
In this post, I explore the capabilities of this tech, describe how it works, and discuss potential applications.
But first: what is DeepFakes and why does it matter?
DeepFakes offers the ability to swap one face for another in an image or a video. Face swapping has been done in films for years, but it required skilled video editors and CGI experts to spend many hours to achieve decent results.
The new breakthrough is that, using deep learning techniques, anybody with a powerful GPU, and training data, can create believable fake videos.
This is so remarkable that I’m going to repeat it: anyone with hundreds of sample images, of person A and person B can feed them into an algorithm, and produce high quality face swaps — video editing skills are not needed.
This also means that it can be done at scale, and given that so many of us have our faces online, it’s trivially easy to insert almost anyone into fake videos. Scary, but hopefully it’s not all doom and gloom, after all, we as a society have already come to accept that photos can easily be faked.

Generating faces is not new: in Star Wars Rogue One, an actress, along with some CGI magic was used to recreate a young Carrie Fisher. The dots helped map her face accurately (learn more here). This is not DeepFakes, but this is the sort of thing DeepFakes lets you do without any skill.
Exploring what DeepFakes is capable of
Before dreaming up how to use this tech, I wanted to get a handle on how it works and how well it performs.
I picked two popular late night TV hosts, Jimmy Fallon and John Oliver, because I can find lots of videos of them with similar poses and lighting — and also enough variation (like lip sync battles) to keep it interesting.

Luckily for me, there’s an active GitHub repo that contains the original DeepFakes code and many more improvements. It’s fairly straightforward to use, but the onus is still on the user to collect and prepare training data.
To make experimentation easy, I wrote a script to work directly with YouTube videos. This makes collecting and preprocessing training data painless, and converting videos one-step. Click here to view my Github repo, and see how easily I generated the videos below (I also share my model weights).
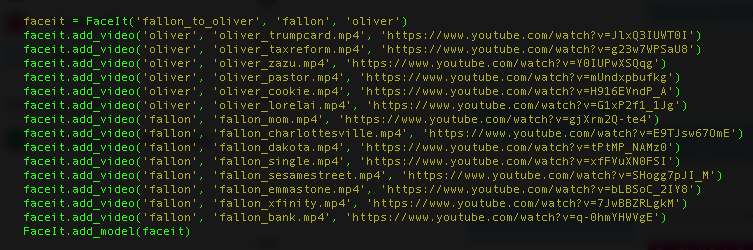
Easy peasy: my script faceit.py let’s you specify a list of YouTube videos for each person. Then run commands to preprocess (download videos from YouTube, extract frames, find faces), train, and convert videos with audio and options to resize, show side-by-side, etc.
Results: Jimmy Fallon to John Oliver
The following videos were generated by training a model on about 15k images of each person’s face (30k images total). I got faces for each celebrity from 6–8 YouTube videos of 3–5 minutes each, with 20 frames per second per video, and by filtering out frames that don’t have their faces present. All of this was done automatically — all I did was specify a list of YouTube video urls.
The total training time was about 72 hours on a NVIDIA GTX 1080 TI GPU. Training is primarily constrained by GPU, but downloading videos, and chopping them into frames is I/O bound and can be parallelized.
Note that while I had thousands of images of each person, decent face swaps can be achieved with as few as 300 images. I went this route because I pulled face images from videos, and it’s far easier to pick a handful of videos as training data, than to find hundreds of images.
The images below are low resolution to keep the size of the animated GIF file small. There’s a YouTube video below with higher resolution and sound.
Please don’t watch this unless you want to see John Oliver dancing to bumpin’ music.
While not perfect, the results above are quite convincing. The key thing to remember is: the algorithm learned how to do this by seeing lots of examples, I didn’t modify the videos in any way. Magical? Let’s look under the covers.