Deep Learning With Apache Spark: Part 1
First part on a full discussion on how to do Distributed Deep Learning with Apache Spark. This part: What is Spark, basics on Spark+DL and a little more.

A primer on Apache Spark
If you work in the Data World, there’s a good chance that you know what Apache Spark is. If you don’t that’s ok! I’ll tell you what it is.

Apache Spark TM.
Spark, defined by its creators is a fast and general engine for large-scale data processing.
The fast part means that it’s faster than previous approaches to work with Big Data like classical MapReduce. The secret for being faster is that Spark runs on Memory (RAM), and that makes the processing much faster than on Disk.
The general part means that it can be use for multiple things, like running distributed SQL, create data pipelines, ingest data into a database, run Machine Learning algorithms, work with graphs, data streams and much more.
The RDD
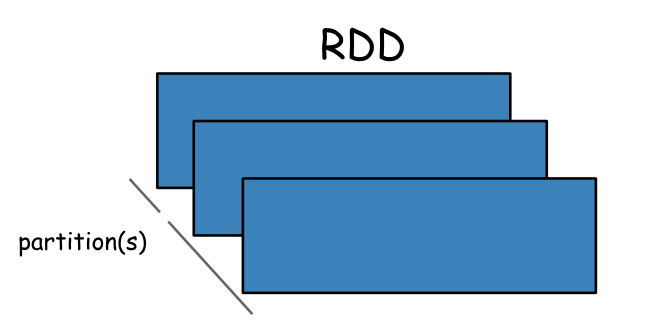
From PySpark-Pictures by Jeffrey Thompson.
The main abstraction and the beginnings of Apache Spark is the Resilient Distributed Dataset (RDD).
An RDD is a fault-tolerant collection of elements that can be operated on in parallel. You can create them parallelizing an existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, or any data source offering a Hadoop InputFormat.
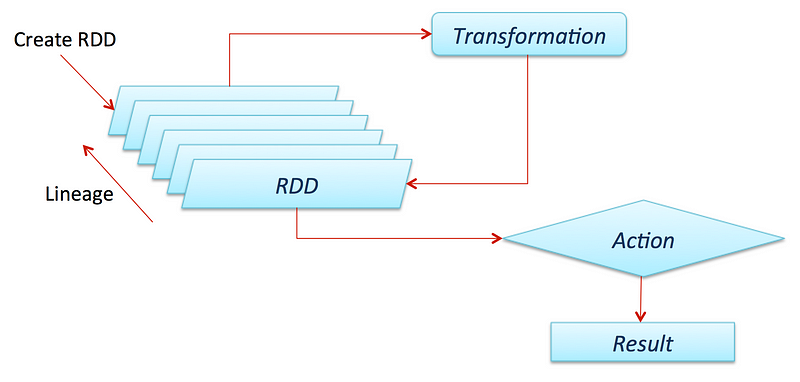
Something very important to know about Spark is that all transformations(we will define it soon) are lazy, that menas that they do not compute their results right away. Instead, they just remember the transformations applied to some base dataset (e.g. a file). The transformations are only computed when an action requires a result to be returned to the driver program.
By default, each transformed RDD may be recomputed each time you run an action on it. However, you may also persist an RDD in memory using the persist (or cache) method, in which case Spark will keep the elements around on the cluster for much faster access the next time you query it. There is also support for persisting RDDs on disk, or replicated across multiple nodes.
If you want to now more about transformations and actions for RDDs in Spark check out the official documentation:
The Dataframe
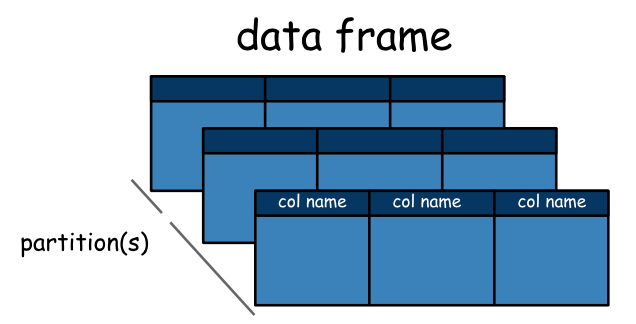
From PySpark-Pictures by Jeffrey Thompson.
Since Spark 2.0.0 a a DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood.
We won’t discuss Datasets here, but they are defined as a distributed collection of data that can be constructed from JVM objects and then manipulated using functional transformations. They are only available in Scala and Java (because they’re typed).
DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs.
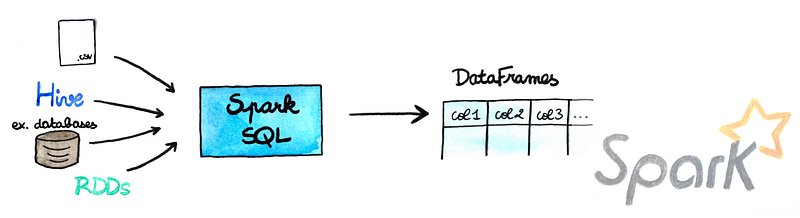
https://aspgems.com/blog/big-data/migrando-de-pandas-spark-dataframes
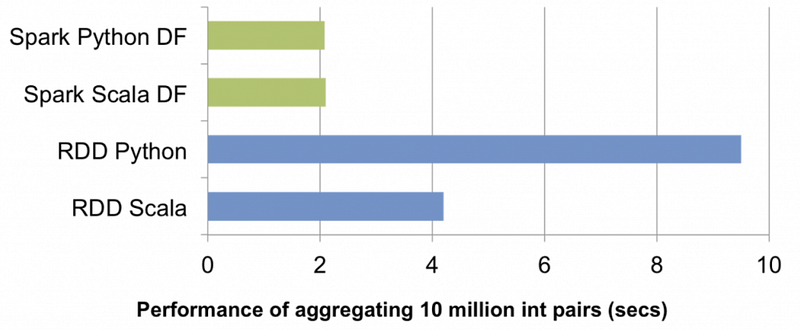
In simple words, the Dataframes API was the way from Spark creators to make easy to work with Data in the framework. They are very similar to Pandas Dataframes or R Dataframes, but with several advantages. The first of course is that they can be distributed across a cluster, so they work with a lot of data, and the second one is that it’s optimized.
It was a very important step that the community took. By the year 2014 it was much faster to use Spark with Scala or Java, and the whole Spark world turned into Scala (is an awesome language btw) because of performance. But with the DF API this was no longer an issue, and now you can get the same performance working with it in R, Python, Scala or Java.
The responsible for this optimization is the Catalyst. You can think of it as a wizard, he will take your queries (oh yes!, you can run SQL-like queries in Spark, run them against the DF and they will be parallelized as well) and your actions and create an optimized plan for distributing the computation.
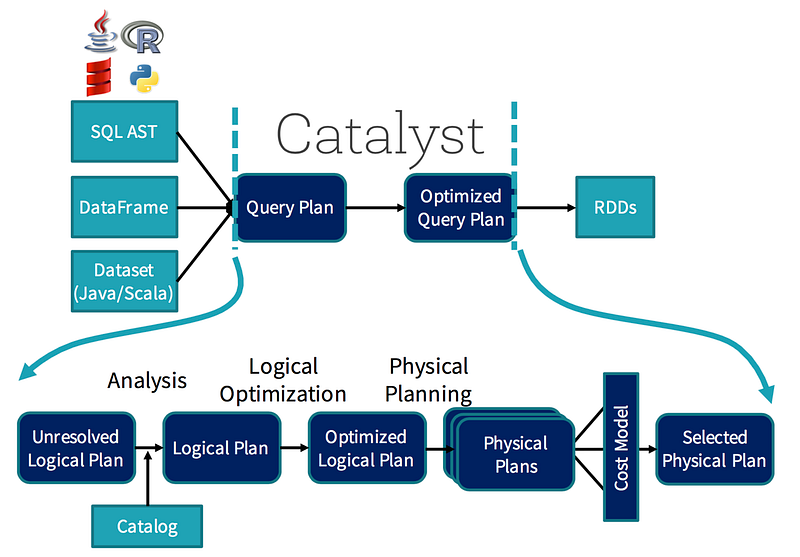
The process is not that simple, but you as a programmer won’t even notice it. Just now that it is there helping you out all the time.
Deep Learning and Apache Spark

https://becominghuman.ai/building-an-image-classifier-using-deep-learning-in-python-totally-from-a-beginners-perspective-be8dbaf22dd8
If you want to know more about Deep Learning please read these posts before continuing:
Why would you want to do Deep Learning on Apache Spark?
This was the question I asked myself before beginning to study the subject. And the answer comes in two parts for me:
- Apache Spark is an amazing framework for distributing computations in a cluster in a easy and declarative way. Is becoming an standard across industries so it would be great to add the amazing advances of Deep Learning to it.
- There are parts of Deep Learning that are computationally heavy, very heavy! Distributing these processes may be the solution to this an other problems, and Apache Spark is the easiest way I could think to distribute them.
There are several ways to do Deep Learning with Apache Spark, I discussed them before, I listed them here again (not exhaustive):
1. Elephas: Distributed DL with Keras & PySpark:
maxpumperla/elephas
elephas — Distributed Deep learning with Keras & Sparkgithub.com
2. Yahoo! Inc.: TensorFlowOnSpark:
yahoo/TensorFlowOnSpark
TensorFlowOnSpark brings TensorFlow programs onto Apache Spark clustersgithub.com
3. CERN Distributed Keras (Keras + Spark) :
cerndb/dist-keras
dist-keras — Distributed Deep Learning, with a focus on distributed training, using Keras and Apache Spark.github.com
4. Qubole (tutorial Keras + Spark):
Distributed Deep Learning with Keras on Apache Spark | Qubole
Deep learning has been shown to produce highly effective machine learning models in a diverse group of fields. Some of…www.qubole.com
5. Intel Corporation: BigDL (Distributed Deep Learning Library for Apache Spark)
intel-analytics/BigDL
BigDL: Distributed Deep Learning Library for Apache Sparkgithub.com
Deep Learning Pipelines
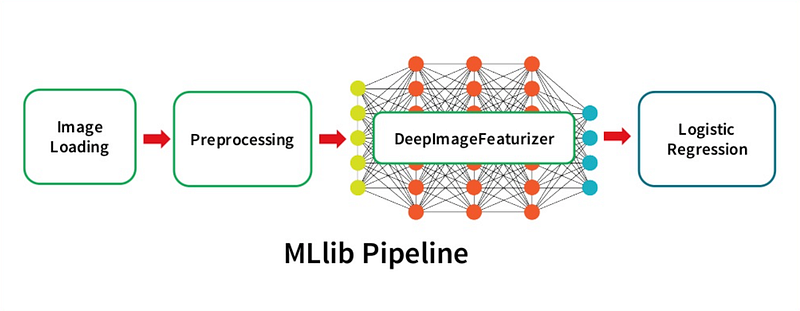
Databricks
But the one I will focus on these articles is Deep Learning Pipelines.
Deep Learning Pipelines is an open source library created by Databricks that provides high-level APIs for scalable deep learning in Python with Apache Spark.
It is an awesome effort and it won’t be long until is merged into the official API, so is worth taking a look of it.
Some of the advantages of this library compared to the ones I listed before are:
- In the spirit of Spark and Spark MLlib, it provides easy-to-use APIs that enable deep learning in very few lines of code.
- It focuses on ease of use and integration, without sacrificing performace.
- It’s build by the creators of Apache Spark (which are also the main contributors) so it’s more likely for it to be merged as an official API than others.
- It is written in Python, so it will integrate with all of its famous libraries, and right now it uses the power of TensorFlow and Keras, the two main libraries of the moment to do DL.
In the next post I will focus entirely on the DL pipelines library and how to use it from scratch. One of the things you will be seeing are Transfer Learning on a simple Pipeline, how to use pre-trained models to work with “small” amount of data and being able to predict things, how to empower everyone in your company by making the deep learning models you created available in SQL and much more.
And also I will create an environment to work in a notebook with this library in the Deep Cognition Platform so you can test everything. Go ahead and create a free account if you don’t have one to get started:
Oh!! BTW, if you want to now more about pipelines in Data Science with Python check out these great articles by Matthew Mayo:
And for a brief on pipelines on Spark check out this:
See you soon :)
If you want to contact me make sure to follow me on twitter:
and LinkedIn:
Bio: Favio Vázquez is the Principal Data Scientist at Oxxo. He is the principal developer and maintainer of Optimus.
Original. Reposted with permission.
Related:
- My Journey into Deep Learning
- The Two Sides of Getting a Job as a Data Scientist
- Another Day in the Life of a Data Scientist